1. DMOps: Data Management Operation and Recipes
1.1 AI 개발을 위한 데이터의 종류
- 말뭉치류
- 대화문, 기사, SNS 텍스트
- 사전/데이터베이스 류
- 온톨로지, 워드넷, 시소러스
1.2 데이터 관련 용어 정리
텍스트
주석, 번역, 서문 등에 적힌 본문이나 원문
말뭉치
어떤 기준으로든 한 덩어리로 볼 수 있는 말의 뭉치
데이터
컴퓨터가 처리할 수 있는 문자, 소리, 그림 따위의 형태로 된 정보
1.3 언어학의 연구 분야
- 음성 : 음성학
- 음운, 음절 ,어절 : 음운론
- 단어(어휘), 구, 절 : 형태론--|의미론,
- 문장 : 동사론---------------|화용론
- 텍스트 : 텍스트 언어학
- 말뭉치 : 말뭉치 언어학
1.4 DMOps
출처https://arxiv.org/pdf/2301.01228
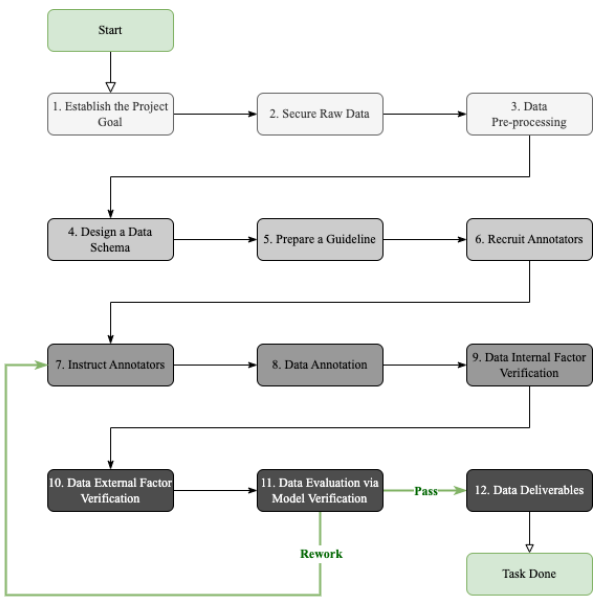
왜 DMOps가 필요할까?
실무에서는 specific한 데이터가 필요하고 이러한 수요에 따라 NLP 데이터 관리 프로세스에 따라 효과적으로 데이터를 관리하는 step-by-step 지침서가 제안될 필요가 있다.
- 즉, DMOps 는 데이터를 생산하는데 베이스라인으로 역할하며 일관성 있고 신뢰할 수 있는 고품질의 데이터를 생살할 수 있게 한다.
1. Establish the Project Goal
- 데이터 제작 목적, 사업적 요구 분석을 수행
- 모델팀, 사업 운영팀과의 협업이 필요함
2. Secure Raw Data
- 원시 데이터 조사 및 수집
- 고객사에서 데이터 제공
- 자체적인 크라우드 소싱 이용
- 크롤링
- 사내 내부 이벤트
- 공공 데이터
- 이러한 모든 활동들은 사실 법무적 검토를 거쳐야 함.
- 원시 데이터에 대해 제한된 엑세스 권한을 제공하여야 함.
- 원시 데이터 수집 시 고려사항
- 데이터 다양성
- 신뢰성
- 획득 가능성
- 법 제도 준수
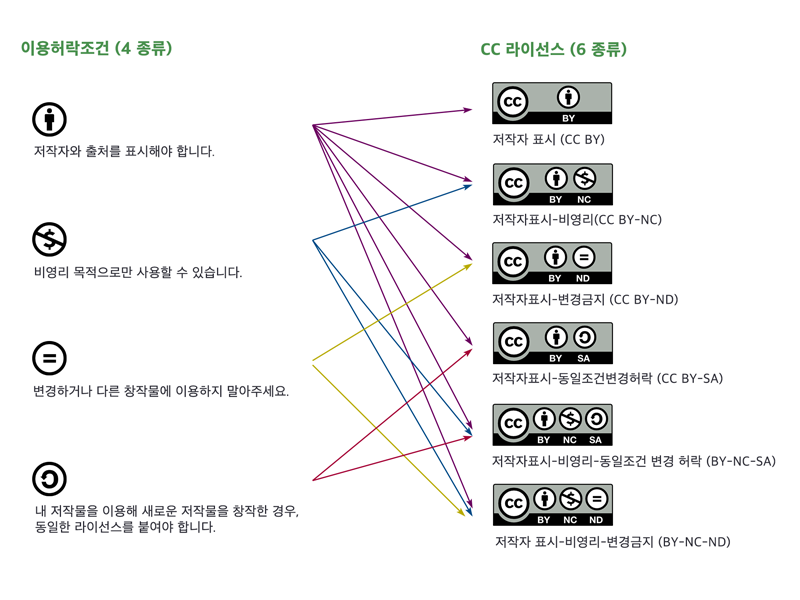
- 저작권
출처 : https://ccl.cckorea.org/about/
3. Data-Pre-processing
- 원시 데이터를 전처리를 통해 가공하여 품질을 높힌다.
- 데이터에 내재된 특성을 바탕으로 품질 향상
- 비 윤리적, 사생활 침해, 노이즈 등 제거
- 크롤링 개인 식별 정보 삭제
- 전처리를 제대로 하지 못하면 원석을 가공하지 못하는 것과 동일
데이터 전처리 시 유의사항
- 정제 기준
구축목적에 맞는 데이터를 선별하기 위한 기준을 명확히 수립하고 기준미달은 효과적으로 제거해야함- 비식별화
- 중복성 방지
4. Desighn a Data Schema
- 데이터셋이 필요로 하는 정보를 모두 담을 수 있도록 주석 작업을 설계하는 단계
- 데이터를 직접 보면서 AI모델로 해결하고자 하는 문제를 풀기 위해 필요한 정보를 담을 수 있는 주석 체계를 만듦
또한 효율성과 정확성을 향상시키기 위해 자동화 할 수 있는 부분과 인간의 입력이 필요한 부분을 분리한다. - 해당 과정에서는 추후 파일럿 작업을 통해 부족한 부분의 내용을 빠르게 보강하는 것이 중요
5. Prepare a Guideline
작업자들에게 설명하기 위해 Document를 작성하는 단계
크라우드 워커들에게 쉽게 알아들을 수 있도록 설명해야 한다.
- Overview -> 용어정의 -> 어노테이션 체계 -> 유의사항 -> Edge Case로 목차 구성
6. Recruit Annotators
- 좋은 데이터셋을 만들기 위해 적합한 작업자 선정
- 정당한 보상 등의 윤리 고려
7. Instruct Annotators
- 작성한 가이드라인을 작업자와 공유하는 양방향 소통 단계
- 라벨링의 전체적 흐름을 따라갈 수 있도록 하는 것이 중요
8. Data Annotation
- 실제 데이터를 구축
- 작업자의 직관을 데이터로 옮기는 과정
9. Data Inspection
- 데이터 고유 요소인 주석 자체에 대해 검증하는 단계
- 같은 것에 대해 작업자들이 다르게 라벨링 하는 경우 가이드라인을 다시 수정
10. Data Verification
- 데이터의 외재적 요소를 검증
11. Data Evaluation via Model Verification
- 실제 모델링을 통해 데이터 품질을 평가함
- 데이터 양을 늘려가면서 데이터 효율성을 봄. 데이터의 구간을 분리하여 데이터 품질 일관성을 검증하는 실험을 진행
- 데이터 제작 목표와 요구사항에 맞춰 데이터가 제작되었는지를 체크
- 해당 구간에서 만족스러운 검증이 되지 않는다면 다시 7로 돌아가 작업자 교육부터 11단계까지 다시 해야함.
12. Data Deliverables
- 데이터에 대한 정보를 모델팀 혹은 유관부서에 전달
- 프로토콜에 맞는 버져닝으로 데이터를 공유함.
2. Data Annotation Tool
- 인간번역의 장점
- 높은 정확도
- 사회/문화 차이 고려 가능
- 중의문에 대한 표현 해석 가능
- 기계번역의 장점
- 비용 우월
- 하나의 시스템으로 번역 가능
- 번역 결과가 일관적임
이 둘은 비용/정확성 측면에서 각기 다른 장단점을 갖춤
즉 사람과 인공지능은 일종의 협업을 해야함
2.1 HAMT (Human Aided Machine Translation)
- HAMT (Human Aided Machine Translation): 사람의 사전 또는 사후 편집으로 자동 번역 품질을 높이는 시스템. 법률, 기술 문서 등 고품질 번역이 요구되는 분야에 적합함
- CAT (Computer Aided Translation): 번역 메모리(TM)를 활용해 일관성 있는 번역을 지원하는 도구. SDL Trados, MemoQ 등 대표적 도구들로 번역자의 생산성 최적화 기능 포함됨
- Doccano: 텍스트 분류, NER, 감정 분석 등 다양한 주석 작업을 지원하는 오픈 소스 도구. 팀 협업 기능 제공.
- BRAT (Browser-Based Rapid Annotation Tool): 구조적 텍스트 주석에 특화된 도구로 언어학 및 생의학 분야에서 사용됨.
- TagEditor: 형식 태그(HTML, XML 등)가 포함된 문서의 태그 관리를 지원하는 도구.
- Tagtog: 웹 기반 주석 도구로 문서 분류 및 NER 작업 지원. 자동 태그 적용과 협업 주석 환경 제공.
- LightTag: 팀 기반 협업 주석 도구로, NER 및 텍스트 분류 작업에 유용함.
- Label-Studio: 이미지, 텍스트, 오디오 등 다양한 데이터 유형의 주석을 지원하는 오픈 소스 도구로, ML 파이프라인과의 통합 용이.
- Upstage Data Labeling Space: 클라우드 기반 데이터 주석 플랫폼으로, 이미지, 비디오, 텍스트 주석을 위한 맞춤형 워크플로우 지원.
3. Data Software Tool
- CleanLab: 머신러닝 데이터셋의 라벨 오류 식별 및 수정 지원 오픈 소스 파이썬 라이브러리. 데이터셋 품질 향상 및 모델 성능 개선에 유용함.
- Snorkel: 약한 지도 학습을 통한 자동 주석 생성 지원 프레임워크. 주석 데이터가 부족한 환경에서 라벨링 함수로 작업 가능.
- Refinery: 데이터셋 준비, 정제 및 전처리 지원 도구. 데이터 레이블링 및 구조화 관리에 적합함.
- Great Expectations: 데이터 유효성 검사, 문서화 및 프로파일링 지원 오픈 소스 프레임워크. 데이터 파이프라인의 품질 관리에 유용함.
- ydata-profiling: 탐색적 데이터 분석(EDA) 보고서 생성 지원 파이썬 라이브러리. 데이터셋의 일관성 및 이상값 식별 용이함.
4. 크라우드 소싱
-
전문가가 아닌 대중 누구나 외부 발주에 참여하는 것
-
데이터 가공 시장 전망
- 데이터 가공 시장 규모가 커짐에 따라서 데이터의 중요성이 대두된다.
-
크라우드소싱 과정은 발주, 데이터 생산 미션 제공, 미션 참여하여 데이터 생산, 데이터에 따라 차등적 리워드 지급, 데이터 취합 및 전달의 단계로 이루어져 있다.
4.1 셀렉트스타
셀렉트스타는 인공지능(AI) 데이터 구축을 위한 크라우드소싱 플랫폼으로, 대규모 작업자 네트워크를 통해 다양한 고품질 데이터셋을 제공합니다. 이미지, 텍스트, 오디오 등 다채로운 AI 학습 데이터를 수집, 가공하며, 기업 및 연구기관에 맞춤형 데이터셋 구축 서비스를 제공함. 무료 오픈 데이터셋도 지원함
4.2 딥네츄럴
딥네츄럴은 자연어 처리 기반 데이터 구축을 전문으로 하여, 다양한 언어의 텍스트 데이터를 수집하고, 데이터 정제 및 가공을 지원하는 크라우드소싱 서비스임. 이를 통해 언어 번역, 감정 분석 등 여러 AI 관련 데이터 처리 지원
4.3 크라우드웍스
크라우드웍스는 데이터 라벨링 및 가공을 위한 플랫폼으로, AI 학습용 데이터 수집과 가공을 크라우드소싱 방식으로 제공. 여러 산업군의 AI 프로젝트에 필요한 텍스트, 이미지, 음성 데이터 등의 구축을 지원
4.4 Annotation AI
Annotation AI는 다양한 AI 모델 학습에 필요한 데이터셋 라벨링을 전문으로 하는 서비스임. 자동화 도구를 활용해 데이터 가공 효율성을 높이며, 텍스트와 이미지 등 다양한 데이터를 대상으로 라벨링 지원
4.5 텍스트넷
텍스트넷은 주로 텍스트 데이터에 특화된 크라우드소싱 플랫폼으로, 텍스트 라벨링 및 정제 작업을 지원하여 언어 모델 학습용 데이터를 제공하는 플랫폼임.
4.6 에이모
에이모는 이미지, 비디오, 텍스트 데이터를 위한 라벨링 서비스를 제공하며, 주로 자율 주행, 의료 영상, 리테일 등 다양한 AI 분야에서 활용되는 데이터셋을 구축하는 플랫폼임. 작업자 네트워크와 협력하여 고품질 데이터 라벨링을 수행
4.7 Appen
Appen은 글로벌 크라우드소싱 플랫폼으로, 언어 데이터 수집, 텍스트 분석, 이미지 라벨링, 음성 데이터 구축 등 다양한 AI 데이터 관련 서비스를 제공하며, 다국적 기업들이 AI 모델을 학습시키는 데 주로 사용함.
4.8 Tictag Korea
Tictag Korea는 사용자가 원하는 대로 태그와 라벨을 손쉽게 추가할 수 있는 플랫폼으로, 텍스트, 이미지 등 다양한 형태의 데이터를 위한 데이터 라벨링을 지원함.
4.9 Speechocean
Speechocean은 특히 음성 데이터 수집과 라벨링에 특화된 플랫폼으로, 다국어 음성 데이터와 텍스트 데이터를 수집하여 음성 인식 및 텍스트 분석 모델에 필요한 고품질 학습 데이터를 제공함
4.10 Flitto
Flitto는 번역 및 언어 데이터를 제공하는 크라우드소싱 플랫폼으로, 텍스트 및 음성 번역, 다국어 데이터 수집을 통해 AI 언어 모델 학습을 지원함.
4.11 Dataforce
Dataforce는 글로벌 크라우드 워커 네트워크를 활용한 텍스트와 음성 데이터 라벨링 플랫폼으로, 고객사 맞춤형 데이터셋을 구축하여 다양한 AI 프로젝트를 지원함.
4.12 Scale.ai
Scale.ai는 이미지와 텍스트 데이터 라벨링 자동화 플랫폼으로, 자율 주행, 전자 상거래, 금융 등 여러 산업에 활용되는 AI 모델을 위한 고정밀 데이터셋을 제공함.
