1. Decoder 모델에 대한 Review
GPT: 다음 토큰을 예측하는 생성 Task로 학습됨
Decoder-only model의 세가지 특성
- Auto Regressive
- Self-Attention
- Causal Masking
2. LLaMA (Meta AI)
- 오픈소스 LLM이다.
- AutoRegressive Decoder-Only Model
- 현재 1, 2, 3, 3.1, 3.2
- Firstly released in Feb, 2023
2023년 2월에 최초 공개되고나서 벌써 3.2까지 나왔고 3.2는 텍스트 뿐만이 아니라 사진까지 처리 가능한 멀티모달로 나왔음.
그 모든 과정에서
알파카, 비쿠냐 등의 연구가 나왔고 최신 연구 트랜드도 영향을 주고 있음
-
기존 Transformer의 문제점
- 임베딩 단계에서 위치정보를 넣어준 것이 바로 Positional Embedding인데, Output과 가장 먼 임베딩 레이어에서 해당 위치정보를 설정해주는 문제로 인하여 레이어를 지날 수록 실제 그 위치정보가 제대로 전해지지 않을 때가 많았고
- 절대적 위치 외에 상대적 위치가 덜 인지되는 문제가 있었음
- 가, 나, 다, 라, 마 이런 순서가 있지 않은 상태에서 별 네모 세모 이런 형태로 학습된 것. 각각이 얼마나 떨어져있고 가깝고 이런 정보가 positional embedding에는 담겨있지 않음
-
여기서 등장한게 바로 Rotery Embedding
Query와 Key 부분에만 한정해서 위치정보를 한번 더 넣어줌
어텐션 레이어 한번 계산 될 때마다 로터리 임베딩의 위치정보를 같이 계산해주면서 상대적인 정보와 절대적인 정보를 같이 이해하도록 함. -
Layer Normalization 중에서 더 간소화 된 RMSNorm이 적용됨. 어텐션 계산 후가 아닌 이전에 들어옴.
-
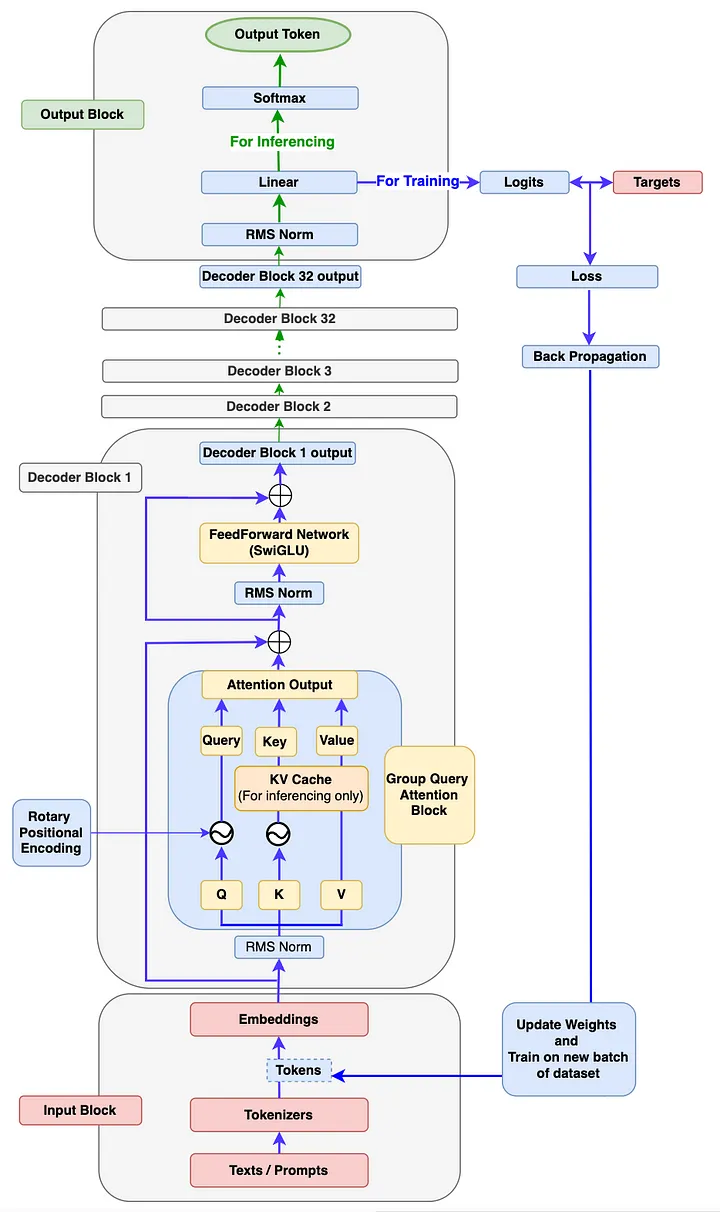
LLaMA 구조
핵심구성요소
Rotary Positional Embedding, RoPE
Multi-Headed Attention (FFN) + GQA
Multi Layer Perceptron (MLP)
RMS Normalization
Flash Attention 2
3. Code-Level LLaMA
- Rotary Positional Embedding, RoPE
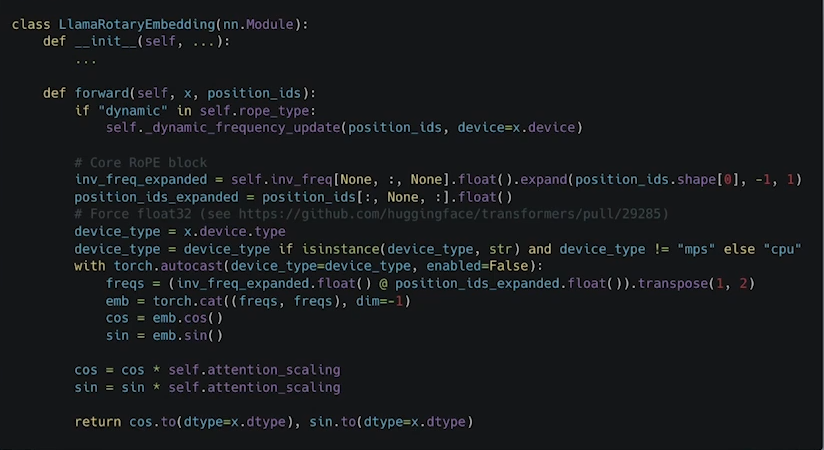
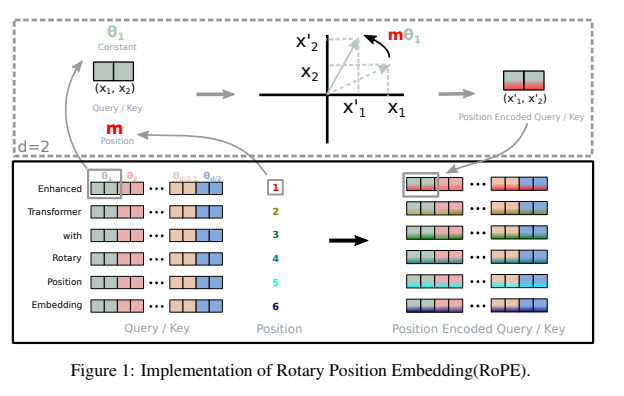
출처: https://arxiv.org/pdf/2104.09864
- Multi-Headed Attention
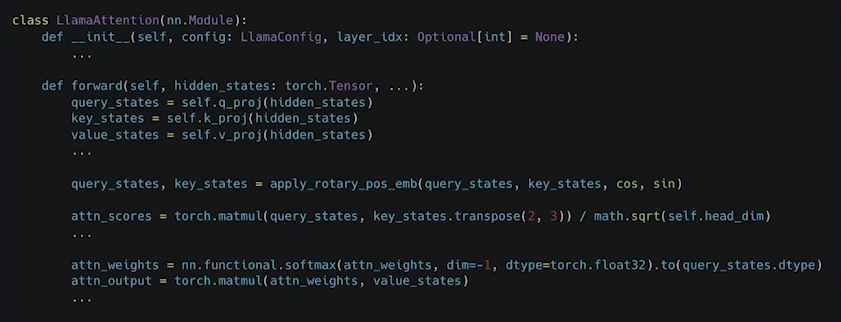
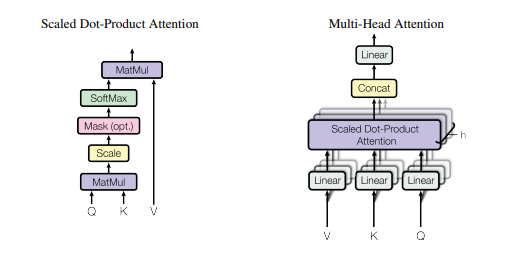
출처: https://arxiv.org/pdf/1706.03762
- Multi Layer Perceptron (FFN), MLP
MLP는 그냥 거대한 nn.Linear이라고 보면 되고
거대한 지식을 담는 곳이라고 보면 됨.
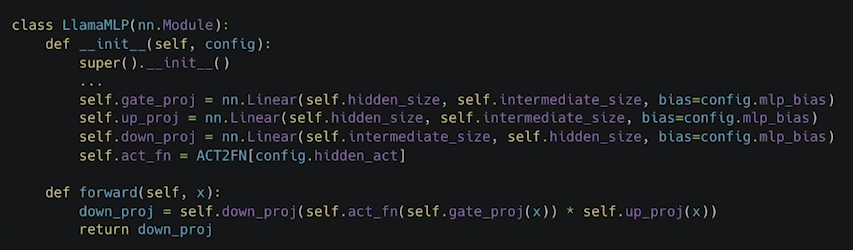
-
Root Mean Square Normalization, RMS Norm
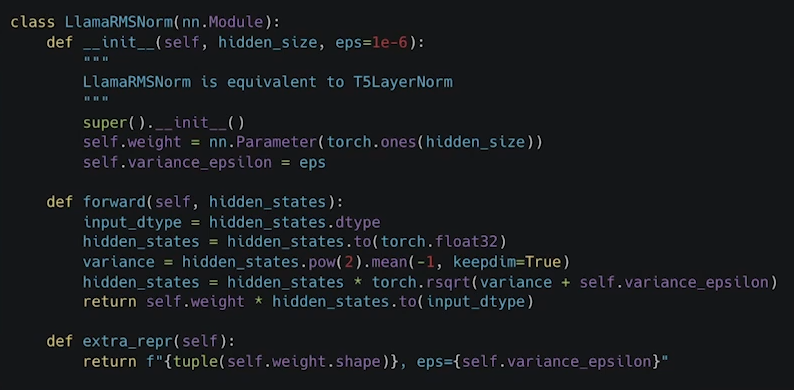
-
batch normalization?
배치 단위 안에서 Mean과 표준편차를 통해 표준화 -
Layer Normalization
배치 단위가 아니라 Feature scale을 통해서 Meanrhk 표준편차를 통해 표준화 해준다.-
그런데 ! Mean과 표준편차 구하는게 꽤나 계산량이 든다는 문제!
그래서 사용하는게 바로 아래의 RMSNorm 다만, RMSNorm은 학습이 되지 않는다
-
-

- Flash Attention 2
플래시 어텐션은 라마의 전유물은 아니다.
TGI, vLLM에서도 사용중
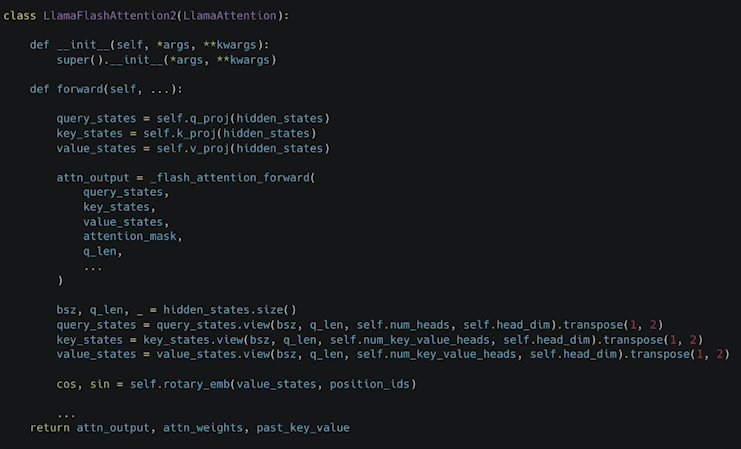
이건 코드 안에 직접 구현되어 있다기 보다는 라이브러리에서 불러와서 해결해버리는 편.
