1. 인코더-디코더
인코더-디코더 ? 트랜스포머로 잘 알려져 있다.
1.1 모델의 발전 흐름
Transformer
GPT
BERT
GPT-2
RoBERTa
GPT-3
--Encoder 모델의 부흥(NLU의 급속한 발전)--
ChatGPT
GPT-4/GPT-4o
--생성형 AI의 시대--
1.2 Encoder-Decoder 모델
인코더에서는 정보를 해석하고, 디코더에서는 그 기반으로 생성한다.
Bidirectional Encdoer와 Autoregressive Decoder 부분으로 나뉘는데, 전자만 쓰게되면 BERT 계열이 되고, 후자만 쓰게되면 GPT 계열이 되는 것.
모두 쓰게 되면 Transformer !
다만, Encoder-Decoder의 경우에 다음의 문제로 한계를 마주하게 됨.
- 효율성의 문제: 각각의 Self-Attention 외에도 연결부 Cross-Attention에서의 병목현상
- 확장성의 부족: In-Context Learning이 인코더에 최적화할 때에 추가 비용이 듦.
1.3 Encoder-only
-
BERT: 바이디렉셔널 인코더 모델
이 모델은 애당초 태어나기를 마스크 토큰 예측하면서 학습됨.'
그리고 자기 스스로 라벨을 만들고 그 라벨을 예측하도록 학습을 진행했는데
이때 이걸 바로 Self-Supervised-Learning 이라고 하는 것. -
문서 분류, 스팸 필터링
-
정보 검색(임베딩)
-
Extradctive QA
다만 Encoder-only모델의 경우에 Auto-Regressive한 Task 즉, Sequential 한 Task에 대해 한계를 보였음.
왜냐하면 학습을 MLM으로 수행했기 때문!
1.4 Decoder-only 모델
- 대표적으로 GPT가 있다.
Causal Language Model로써, 앞 토큰 및 문맥을 토대로 이후의 토큰을 예측한다.
그래서 생성형 Task, Sequential Task에 강점이 있음.
Decoder-only 모델의 발전
- Emergent Abilities(Model Size, Training Flops)
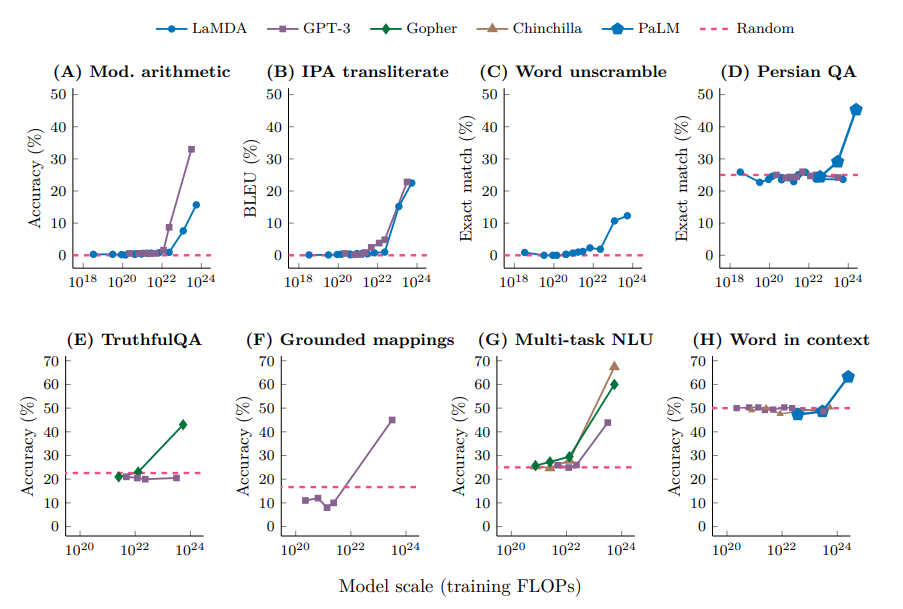
출처 : Emergent abilities of large language models
작은 모델에서는 나타나지 않는데, 특정 수준 크기의 모델에서부터는 학습이 매우 크게 증진됨.
- 생성만 잘하나요?
- 아니요, NLU Task들에 있어서 훨씬 더 쉽게 잘 풀고 있다. Few shot만으로도 상당히 큰 수준을 보여줌.
- LLM의 시대? Decoder-only 모델의 시대
2. LLM의 시대
2.1 LLM과 Decoder-only 모델
LLM과 Decoder-only 모델은 다른게 아니다
다만, LLM이라고하면 그 크기가 매울 클 것.
Few-shot, In-Context Learning 뭐가 다른가요?
같다.
예시를 넣어서 보여주는 것이다.
다만 단순히 예제 몇개를 보여준다고 풀 수 없는 Task가 있기 때문에
아래와 같은 CoT(Chain-of-Thought)를 사용한다.
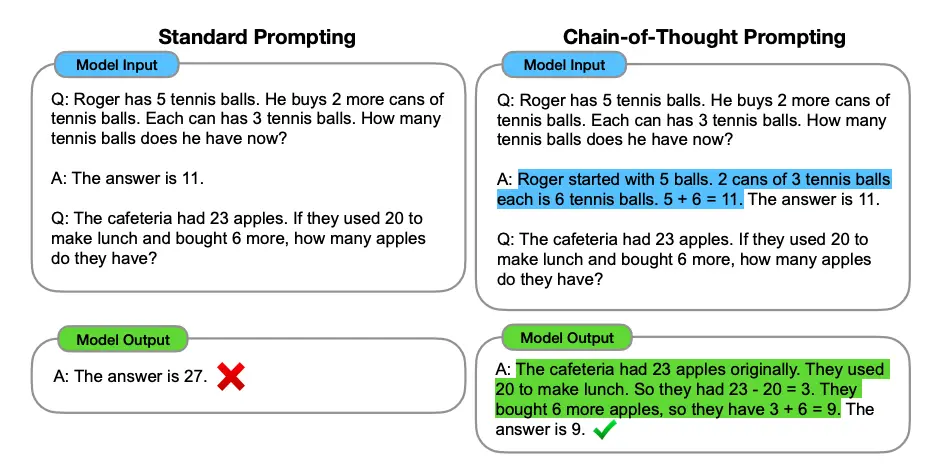
출처: https://arxiv.org/abs/2201.11903
원하는 형식으로 생성하도록 모델을 유도하는 과정으로는 아래가 있다.
Human Alignmnet
-
Instruction Tuning
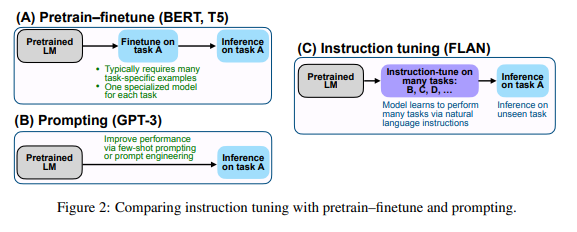
출처 : https://arxiv.org/pdf/2109.01652 -
RLHF
형식을 잘 따라가도 좀 더 좋은 내실을 갖추도록 할 수 있는데 그게 바로 RLHF
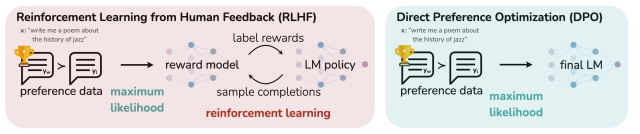
출처: https://arxiv.org/pdf/2305.18290
