1. Large Laguage Model 기본
-
LLM이란?
- 범용적이며
- 사전 학습 데이터와 파라미터수가 매우 큰
- 모델을 종합적으로 지칭한다.
-
Zeor/Few-Shot Learning
-
LLM의 범용 목적 모델 동작 원리
-
모델 추가 학습 불필요
-
입력 데이터 구성을 통하여 다양한 Task 수행
-
Zero shot / Few shot의 차이
- 예시를 주느냐 안 주느냐의 차이
모델 사이즈가 커지면 사용자가 context 안에서 데이터 구성만 제대로 해줘도 큰 성능 향상이 있음
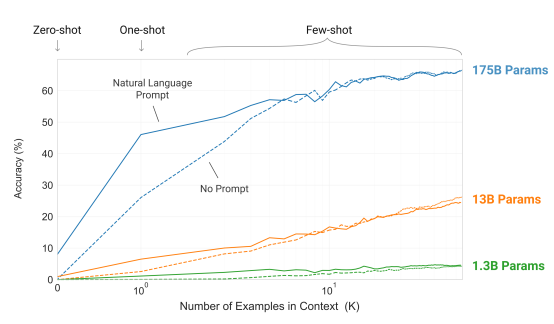
Language Models are Few-Shot Learners, Brown et al., 2020"
-
Prompt
- Zero/Few shot Learning이 가능한 LLM의 입력 구성 방식
- 구성 요소:
- Task Description
수행할 Task에 대한 묘사 - Demonstration
수행할 Task 예시(입력-출력 쌍) - Input
실제 Task를 수행할 입력 데이터
- Task Description
- Prompt 구성 방식에 따라 모델 성능 변화
-
최근 모델 구조
- 대부분의 LLM은 Causal Decoder 구조를 사용한다.
- 내부 구조는 Transformer와 대동소이하고
- Pretrain 방식으로써 대부분 Next Token Prediction을 수행하는데, 이는 구현 방식 및 연산이 효율적이기 때문이다.
2. Instruction Tuning
- LLM의 능력
- 다양한 문장을 생성할 수 있는 능력이 있으며
- 존재하지 않는 어휘에 대해서도 문장을 생성할 수 있다.
- 따라서 세장대왕 맥북사건 같은 ISUUE가 생기기도 함. (할루시네이션)
- Safety & Helpfulness
- 사용자가 물어보는 모든 질문에 답하는 것이 아니라, 적절하게 경우에 따라 혐오 표현 및 윕혀적 표현을 출력하지 않아야 함(Safety)
- 사용자의 다양한 입력에 적절하게 답해야하고, 사용자가 원하는 광범위한 입력에 대하여 질의자의 요구사항에 맞춰 custom 된 출력을 뱉을 줄 알아야 함 (HelpFulness)
위와 같은 이슈들을 가능하게 하는 것이 바로 Instruction Tuning
-
Instruction Tuning
- 사전 학습: 이전 단어를 바탕으로 다음 단어를 예측하도록 학습시키고
- Instruction Tuning을 통하여
- 사용자의 광범위한 입력에 대하여
- 안전하면서(Safety)
- 도움이 되는 (Helpfulness)
- 적절한 답변을 생성하도록 Fine-tuning 함.
- Instruction Tuning은 3단계로 구성되는데
- SFT(Superviese FineTuning)
광범위한 사용자 입력에 대하여 정해진 문장을 생성하도록 Finetune - Reward Modeling
LLM의 생성문에 대한 선호도를 판별하는 모델 Finetune - RLHF(Reinforcement Learning with Human Feedback)
광범위한 사용자 입력에 대해 인간이 선호하는 답변을 출력하도록 강화학습
- SFT(Superviese FineTuning)
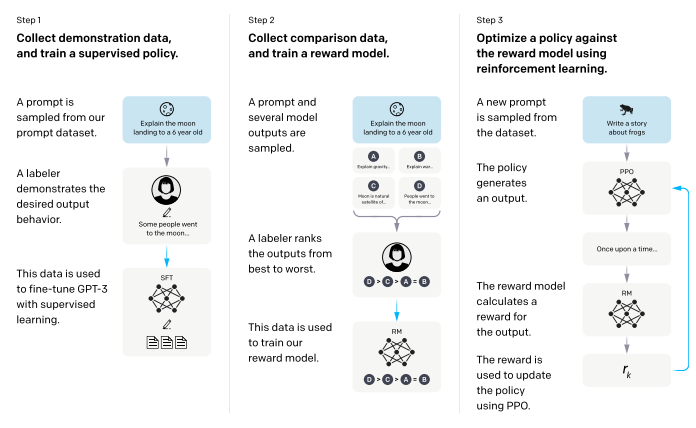
-
SFT 및 RLHF 효과
- Supervised Finetuning:
사용자 지시(Instruction)을 따르도록 (Following) 모델 FInetune - Instruction Following 능력 향상 목적
- SFT 및 RLHF 학습 시 사전학습 LLM보다 다양한 지표에서 개선
- 사용자 지시(Instruction) 호응도 상승
- 거짓 정보(Hallucination) 생성 빈도 감소
- Supervised Finetuning:
- SFT 및 RLHF 학습시에 사전 학습 LLM 보다 다양한 지표에서 개선이 되었는데, 특히 RLHF를 적용할 시에 작은 모델(1.3B)에서 큰 모델(175B)보다 높은 Instruction Following 능력을 기록하게 됨.
- 위와 같은 것에 비추어 보아 LLM은 모델 크기가 중요하긴 하나, Instruction Tuning 방법론 또한 매우 중요함.
- 그러나 비용이 매우 크게 드는 만큼 정말 잘 설계를 해야함. 기회비용이 크기 때문

헤매는 만큼 자기 땅이다.