1. LLM의 발전
-
학습 데이터와 모델 파라미터 사이즈가 커질수록 성능이 점점 향상되는 것을 확인하였음
-
보통 범용 웹 데이터로 사전학습을 수행하고 Downstream Task에 맞춰서 Finetuning해왔음
위와 같은 방법은 특정 Task에 대한 성능 향상을 보장했음. -
모든 파라미터를 학습하는 경우 성능 향상이 가장 높은 것으로는 확인 되었으나, 매우 큰 비용이 소모되고, 성능 측면에서 사실 모델이 추가적으로 학습하는 과정에서 기존 학습 정보를 잊어버리게 되는 현상 또한 발견됨
즉 모든 파라미터를 새로운 데이터에 대해 학습하는 것이 항상 정답이 될 수 없음.
-
그래서 등장한 것이
ICL
in-context-learning을 통해 별도의 학습 없이 입력을 통해 원하는 출력을 얻을 수 있게 됨.- 다만, 신뢰성 측면에서 몇몇의 경우에 random한 label을 넣어주더라도 문제를 잘 해결한다는 연구 결과가 존재하는 바, ICL의 결과물을 항상 신뢰하기는 어려울 수 있음이 밝혀짐

출처: Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?, Min et al., 2022
- 다만, 신뢰성 측면에서 몇몇의 경우에 random한 label을 넣어주더라도 문제를 잘 해결한다는 연구 결과가 존재하는 바, ICL의 결과물을 항상 신뢰하기는 어려울 수 있음이 밝혀짐
2. 파라미터 수가 많은 LLM도 효율적으로 학습할 수 없을까?
-
PEFT: Parameter-Efficient Fine-Tuning
- Transformer 모델의 모든 파라미터를 업데이트 하지 않고 각 방법론 별로 소량의 파라미터를 효율적으로 업데이트 함
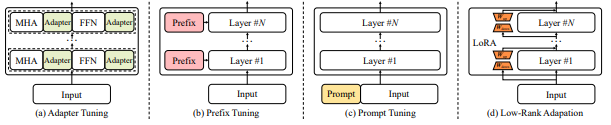
- Transformer 모델의 모든 파라미터를 업데이트 하지 않고 각 방법론 별로 소량의 파라미터를 효율적으로 업데이트 함
PEFT
-
Adapter
- 기존에 이미 학습이 완료된 모델의 각 레이어에 대하여 학습 간증한 FFN을 삽입하는 구조
- Adapter layer는 transformer의 vector를
- 더 작은 차원으로 압축한 후에
- 비선형 변환을 거쳐
- 원래 차원으로 복원하는 병목 구조(bottleneck architecture)로 이루어짐.
- Adapter 모듈은 fine-tuning 단계에서 특정 target task에 대해 최적화 되는데
- 이 때 나머지 transformer 레이어는 모두 고정됨.
-
Prefix Tuning
- Transformer의 각 레이어에 prefix라는 훈련 가능한 vector를 추가하는 방법으로, prefix는 가상의
embedding으로 간주될 수 있음. - 각 Task를 더욱 잘 풀이하기 위하여 벡터를 최적화해 기존 모델과 병합할 수 있음.
- Transformer의 각 레이어에 prefix라는 훈련 가능한 vector를 추가하는 방법으로, prefix는 가상의
- Prompt Tuning
- Prefix tuning과 달리 모델의 입력 레이어에 훈련 가능한 prompt vector를 통합하는 방법론
- input 문장에 직접적인 자연어 prompt를 덧붙이는 promptng과는 다른 개념임
- Embedding Layer를 최적화하는 방법론으로, target task에 최적화 됨.
예시
from transformers import GPT2Tokenizer, GPT2LMHeadModel import torch.nn as nn import torch # 기본 모델 및 토크나이저 tokenizer = GPT2Tokenizer.from_pretrained("gpt2") model = GPT2LMHeadModel.from_pretrained("gpt2") # Prompt 벡터 초기화 (학습 가능하도록 설정) prompt_length = 5 # Prompt 길이 hidden_size = model.config.n_embd prompt_embedding = nn.Parameter(torch.randn(prompt_length, hidden_size)) # Forward 함수에 Prompt 추가 def forward_with_prompt(input_ids): # 기존 입력 임베딩 input_embeddings = model.transformer.wte(input_ids) # Prompt 벡터 추가 prompt_embeddings = prompt_embedding.unsqueeze(0).expand(input_embeddings.size(0), -1, -1) inputs_with_prompt = torch.cat([prompt_embeddings, input_embeddings], dim=1) # 모델 Forward outputs = model(inputs_embeds=inputs_with_prompt) return outputs # 입력 예시 text = "The capital of France is" input_ids = tokenizer(text, return_tensors="pt").input_ids outputs = forward_with_prompt(input_ids) print(outputs)
- LoRA
- 사전 학습된 모델의 파라미터를 고정하고, 학습 가능한 rank decomposition 행렬을 삽입한다.
- 행렬의 차원을 'rank'만큼 줄이는 행렬과, 다시 원래의 차원 크기로 바꿔주는 행렬로 구성되며
- 레이어 마다 hidden states에 LoRA prarmeter를 더하여 tuning을 실시한다.
- 가장 많이 쓰이는 PEFT 방법론
- Adapter layer를 추가하는 방법과 달리 Inference Latency가 증가하지도 않고
- LoRA를 활용하면 새롭게 학습한 파라미터에 대하여 기존 모델에 쉽게 합쳐줄 수 있어서 추가 연산이 필요하지도 않아
Inference speed를 유지하며 모델의 아키텍쳐를 변형하지 않고도 활용할 수 있다는 점에서 활용도가 높음

헤매는 만큼 자기 땅이다.