1. 오픈 소스 LLM
- 주요 라이센스
- MIT License
자유로운 복사 및 배포는 가능하나, 유료화는 불가함 - CC-BY-SA 4.0
자유로운 복사, 배포가 가능하며, 유료화 또한 가능함.
- MIT License
- LLM에 대하여는
다음 두가지 라이센스를 꼭 생각해야함.- 학습 데이터에 대한 라이센스
- 사용하고자 하는 모델 코드에 대한 라이센스
- Llama 1 발표 이전에는
ChinchillaGopherGPT-NeoXOPTPythia같은 오픈소스 모델들이 있었으나 - 해당 서비스의 활용이 매우 어렵고 성능이 저조했다.
2. Llama
- Chinchilla Scaling Law
동일 자원에서 모델 성능을 가장 높이는 학습 데이터 수와 모델 크기 관계식을 의미함- 정해진 사전 학습 예산 존재 시 모델 크기와 학습 데이터는 반비례 관계임.
- 모델 크기: 학습데이터 = 1:21.6
- LLM 학습 시 모델 크기 별 학습 데이터 수 설정에 활용이 됨.
모델 크기 대비 21.6배 크기의 데이터로 학습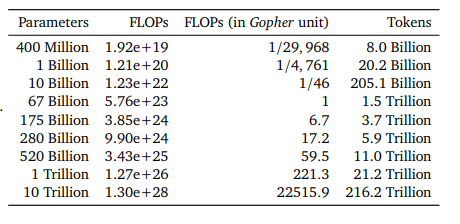
출처: Training Compute-Optimal Large Language Models, Hoffmann et al., 2022
-
Llama는 이런 Chinchilla Scaling Law를 지키지 않음.
- 기존 LLM은 모델 크기 대비 21.6배 데이터로 학습하였음.
- 그러나 Llama의 경우 그 이상의 데이터로 학습하였는데, 이유는 LLM 활용 시에 학습 예산의 최적화가 중요한 것 이 아니라, 추론시의 비용 최소화가 중요하다고 판단했기 때문.
- 추론 비용은 모델 크기와 비례하므로, 작은 모델을 더 오래 학습 시켜 배포하는 것이 모델 배포 관점에서 더 효율적이라 판단한 까닭임.
-
그렇게 더 많은 데이터로 학습 한결과 Llama 1, 2는 더 높은 성능 달성
3. Alpaca, etc...
Llama 7B에 대해서 LLM을 적극 활용해 훈련한 모델
- GPT API를 이용하여 SFT 데이터를 생성 및 학습한 프레임워크가 반영된 모델
4. LLM 평가
-
평가 목적
LLM의 범용 수행능력 (다양한 Task에 대한 능력)
안전성이 확보된 답변을 반환하는가? -
평가 데이터
범용적 능력 평가용 데이터
- 평가 방법론
Task 별로 상이하다.
ex) MMLU: LLM의 범용 Task 수행능력 평가용 데이터셋
ex) HellaSwag: 사람이 가지고 있는 상식 평가 데이터셋
ex) HumanEval: LLM의 코드 생성 능력 평가 데이터셋
G-Eval: GPT-4를 이용한 생성문 평가 방법론
5. 요약
- 모델과 데이터에 대한 라이센스 확인 필요
- SFT 학습데이터 구축시 GPT-4 등을 이용해 효율적으로 구축 가능하고 이는 Alpaca 모델에서 확인할 수 있음.
- LLM 평가시 평가와 부합하는 데이터셋을 활용해야 함.
- 창의성의 영역 또한 G-Eval을 이용하여 Human Evaluation을 대체할 수 있다.

헤매는 만큼 자기 땅이다.