유니코드와 Tokenization
1. Unicode
전 세계 모든 문자를 일관되게 표현할 수 있도록 만들어진 문자셋을 의미한다. 각 문자마다 숫자 하나에 맵핑한다.
- U+AC00
U+의 경우 유니코드를 뜻하는 접두어이며
AC00의 경우 16진수로 표현된 Code point를 의미한다.
2. UTF-8
유니코드와 다른 방법론으로 UTF-8 인코딩이 있는데
인코딩이란 문자를 컴퓨터에서 저장하고 처리할 수 있게 이진수로 바꿔주는 것을 의미하고
UTF-8이란 그러한 인코딩 방식 중 하나로써, 문자가 어떤 타입을 지녔는지에 따라 다른 길이의 byte를 할당한다. 현재 가장 많이 쓴다.
보통 영어의 경우에 ASCII(아스키)로 해결되지만, 다른 언어들을 같이 쓰기 시작하면서 더 많은 바이트를 할당하게 되었다. 그런데 그걸 미리 바이트를 할당해 놓는 것이 아니라, 인코딩할 문자가 어떤 타입을 지녔는지에 따라 UTF-8은 다른 길이의 바이트를 할당해준다.
-
UTF- 8 인코딩 예시
문자 : '가'
유니코드 코드 포인트 : U+AC00
UTF-8 인코딩 : 1110 1010 1000 0000 1000 0000 (3바이트)문자: ‘😊’
유니코드 코드 포인트: U+1F60A
UTF-8 인코딩: 1111 0000 1001 1111 1001 1000 1010 1010 (4바이트)
-
ASCII(아스키) 코드란?
American Standard Code for Information Interchange의 약자로 딱 봐도 영어만 다룰 것 같은 냄새가 물씬 난다.
아스키 코드는 컴퓨터와 통신 장비에서 텍스트를 표현할 때에 사용되는 표준 문자 인코딩 시스템으로, 아스키 코드 역시 문자를 컴퓬터에서 저장하고 처리할 수 있도록 이진수로 바꿔주는 역할을 한다.
ASCII 코드의 경우 7비트로 구성되어 있으며 총 128개의 문자와 제어문자를 포함한다.주요 특징
영문 알파벳: 대문자와 소문자 (A-Z, a-z)
숫자: 0-9
특수 문자: @, #, $, %, &, 등
제어 문자: 개행(LF), 캐리지 리턴(CR), 탭(HT) 등예시
문자 ‘A’: ASCII 코드 65, 이진수로 01000001
문자 ‘a’: ASCII 코드 97, 이진수로 01100001
숫자 ‘0’: ASCII 코드 48, 이진수로 00110000아스키 코드는 기본적으로 7비트로 구성되나, 나머지 1비트에 관해 패리티 비트로 오류 검출에 사용되거나 그냥 9으로 채워진다. 따라서 1바이트로 저장되지만, 실제 문자정보는 7비트로 표현된다.
3. Python에서 Unicode확인하기
Python3부터 string 타입은 유니코드를 표준으로 사용한다.
- ord
문자를 유니코드 codie point로 변환해준다. - chr
code point를 문자로 변환해준다.
3.1 예시
# 'A'의 유니코드 코드 포인트를 구합니다.
unicode_point = ord('A')
print(unicode_point) # 출력: 65
# 유니코드 코드 포인트 65를 문자로 변환합니다.
character = chr(65)
print(character) # 출력: 'A'4. 유니코드와 한국어
한국어는 유니코드에서 상당히 많은 코드를 차지하고 있다.
이는 한국어를 완성형으로 표현하기에 생기는 문제이다.
-
조합형(NFD)
한글을 초성/중성/종성으로 분리하여 유니코드로 표현하는 방식으로 각 자모를 개별적으로 인코딩하여 조합한다.예컨데 한이라는 글자는 ㅎ ㅏ ㄴ 으로 분리되는 바
초성 ‘ㅎ’: U+1112
중성 ‘ㅏ’: U+1161
종성 ‘ㄴ’: U+11AB
조합형 유니코드: U+1112 U+1161 U+11AB위와 같이 나타난다.
-
완성형(NFC)
완성형은 하나의 완성된 글자를 유니코드로 표현하는 방식으로, 각 글자가 고유한 유니코드 값을 가진다. -
완성형인지 조합형인지에 따라 같은 글자여도 len()을 통해 확인하면 길이가 다를 수 있다.
예컨데 '한'이라는 글자는 하나의 완성된 글자로 인코딩 된다. 한 => U+D55C
chr(0x1100) + chr(0x1161) # (ㄱ + ㅏ) = 가
5. Tokenization
5.1 토크나이징이란?
텍스트를 토큰 단위로 나누는 것을 말한다. 다양한 기준(띄어쓰기, 형태소, subword 등)으로 텍스트가 나뉘어진 다.
- Subword 토크나이징
쉽게 말하자면, 자주 쓰이는 글자 조합은 하나의 단위로, 자주 쓰이지 않는 조합은 Subword로 쪼개서 자주 쓰이는 조합으로 만들어 준다.
예를 들어 '졸업여행'의 경우에 '졸업' '여행' 으로 쪼개주는데, 이때 보통 쪼개지는 뒷 단어의 앞에 '##'을 붙여 디코딩 할 때에 해당 토큰의 앞 토큰에 대하여 다시 붙여줌으로써 원상복구를 해준다.
길이 기반은 아니며, 자주 나오는 단어 기반으로 나누어준다고 파악하면 된다.
위키독스 토크나이저 부분 참고
BERT에서 사용되었지만, 좀 더 일반적인 방법론으로써 말하자면, BPE(Byte-Pair-Encoding)이 있다.
이는 가장 자주 나오는 글자 단위들을 다른 글자로 치환한 후에 해당 치환된 글자를 따로 저장하는 방식으로 작용하는 알고리즘인데, 현재 NLP분야에서 토크나이저 방식으로 활발하게 사용되고 있다.
5.2 Regular Expression의 활용 여부
결론만 말하자면, BPE 같은 알고리즘 없이도 하나씩 찾아서 단어장에 추가하는 정규표현식을 활용한 방법 또한 물론 된다.
그러나 최근 그러기에는 빅데이터의 등장과 함께 너무나 막대한 용량의 텍스트가 쏟아지고 있고 그러한 데이터를 다루기 위해서는 해당 모델이 다루는 Data에 대한 Data-driven 접근이 필요한 바, 앞서 설명한 BPE와 같은 알고리즘이 적용된 토크나이저가 많이 활용되고 있다.
6. 데이터셋 - KorQuAD
LG CNS에서 개발한 질의응답/기계독해에 사용되는 한국어 데이터셋이다.
데이터셋 특성
- 한국어 위키피디아 1550개 문서를 가져와서 하위 10649건의 하위 문서들과 크라우드 소싱을 통해 제작함.
- 누구나 데이터셋을 내려받고 학습한 모델을 제출한 후 공개 리더보드에서 평가받을 수 있음
- 현재 1.0 버전과 2.0버전이 공개되었고, 2.0버전의 경우에는 단순 한국어 문장 뿐 아니라, HTML형태의 복잡한 표, 리스트 등도 포함되어 있어서 문서 전체구조에 대한 이해가 필요하다.
KorQuAD v1.0 수집 과정
- 대상 문서 수집 (이미지/표 제거)
- 질문 답변 생성 (작업자가 양질의 질의응답 생성)
- 2차 답변 태깅 (Human Performance 측정)
Huggingface 라이브러리를 활용한 데이터셋 다운로드
from datasets import load_dataset # squad_kor_v2도 불러올 수 있음 dataset = load_dataset('squad_kor_v1', split='train')
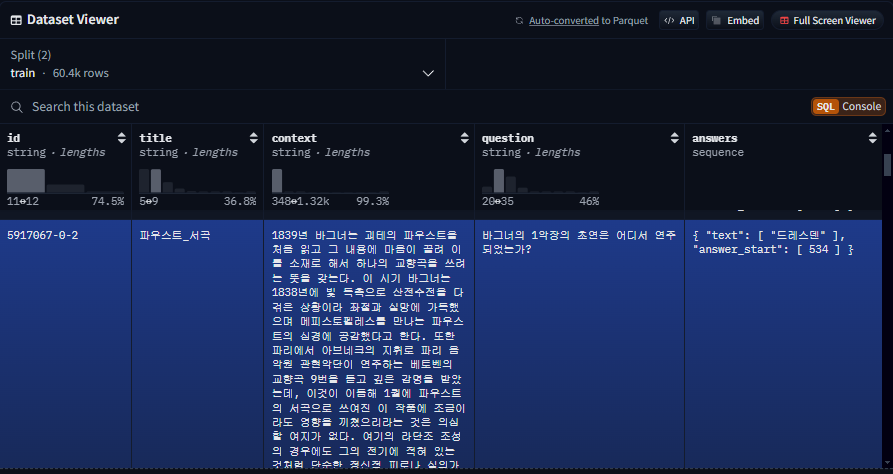
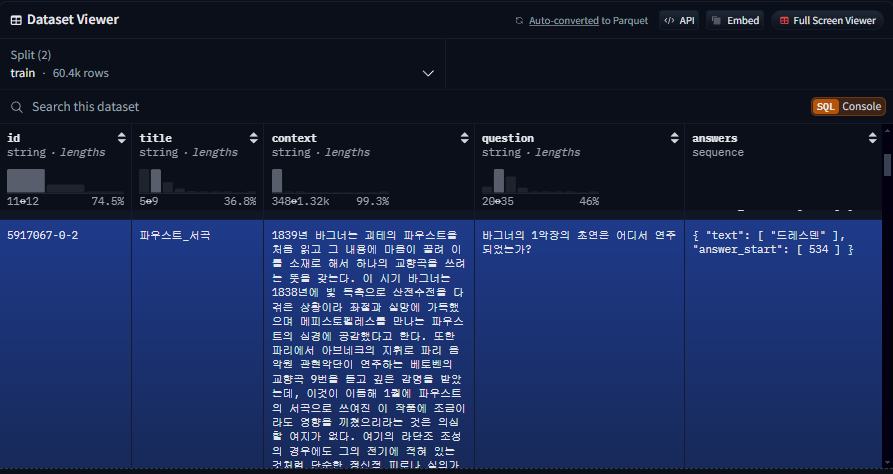
Huggingface squad_kor_v1 주소
프로젝트의 데이터는 KorQuAD와 유사하지만 다른 실제 제작한 데이터다.
- KorQuAD 또한 Extractive 한 데이터이기 때문에 항상 지문 내에 답변이 존재한다.
- 답변 set에 answer_start가 들어있는데 이건 실제 답변에 사용되는 문장이 여러개가 들어가는 경우를 대비한 것이다. 학습할 때에 제대로 supervision을 하기위해서 넣었으나, 해당 부분이 없더라도 학습 자체는 된다.
지문 :
대한민국의 수도는 서울이다. 서울은 한국의 정치, 경제, 문화의 중심지이다. 서울은 한강을 중심으로 발전해 왔다.
질문 :
대한민국의 수도는 어디인가요?
답변 :{ "text": "서울", "answer_start": 10 }위와 같이 답변이 시작하는 인덱스는 10이기에 answer_start로 10을 주면 더욱 강하게 supervised된 학습이 가능하다.
다만, 지금의 경우는 답변이 하나만 있는 경우이기에 별도의 리스트형태가 보이지 않았으나, 원래 해당 'answers'에 벨류로 들어가는 'answer_start'와 'text'의 경우 여러개의 값을 리스트형식으로 넣어둘 수 있다. 왜냐하면 해당 context에서 주어지는 답이 여러 개 있을 수 있기 때문이다.
