1. Extraction-based MRC란 무엇인가?
주어진 context 안에 항상 질문에 대한 답변이 span형태로 존재하는 기계독해를 의미.
- span?
특정 범위를 의미 - Extraction-based MRC 예시
문맥이 "The capital of France is Paris."이고 질문이 "What is the capital of France?"일 때, 시스템은 "Paris"라는 답변을 문맥에서 추출.
이처럼 답변이 문맥 내에 명확하게 존재하는 경우에 Extraction-based MRC 라고 함.
1.1 Extraction-based MRC 평가방법
- EM Score
정답과 완전히 overlap되어야 정답 인정 - F-1 Score
예측과 정답 사이의 overlap된 비율을 계산한다. 0 또는 1이 아닌, 그 사이 부분점수를 받을 수 있기에 대개 EM score보다 F-1 score가 높음.
1.2 MRC 프로젝트에서 만들어 나갈 model 개요
1.2.1 step_1 : preprocess
입력되는 raw data (context, qeustion, answer)를 토크나이저를 통해 토큰화 시켜준다.
-
Tokenization
텍스트를 작은 단위로 나눠주는 것. 띄어쓰기, 형태소, subword등의 여러 단위가 해당 기준이 될 수 있다. -
Special token
통상 모델에 context와 question이 들어갈때에 Special Tokens로 Query와 context가 구분되어 들어간다.
[CLS],[SEP],[PAD]등의 토큰들이 사용됨 -
Attention Mask
입력 시퀀스 중에서 0 또는 1로 각 토큰을 표시하여 의미가 없는 무시할 것([PAD])과 그렇지 않은 것을 구분 -
Token Type IDs
question과 context가 같이 들어오는 MRC의 경우처럼 입력이 둘 이상의 시퀀스로 들어올 때에 각각의 시퀀스 구분을 위하여 각각에 ID를 부여해 모델이 구분하여 학습, 해석하도록 유도한다.
MRC Task에서 질문이 항상 첫번째 문장으로 들어오기에 해당 하는 범위는 0으로 처리되고
PAD 토큰 또한 Question에 대한 대답으로 PAD토큰내에서 정답을 찾으면 안되므로 0으로 처리하여 학습에서 제외시킨다.max token - 입력시퀀스
위 값을 계산하면 보통 입력될 pad 토큰이 나올텐데, 이때 주의할 것은 padding은 query, context 각각에 따로 들어가는 것이 아니라, 입력시퀀스 자체가 query가 앞에오고 뒤에 context가 sep 토큰으로 구분되어 연속적으로 들어가기에 그 둘의 합이 입력시퀀스여서 pad는 항상 맨 마지막에 줄줄줄 붙는다.
간단한 예시를 보자.문맥 (Context)
“서울은 대한민국의 수도입니다.”질문 (Question)
“대한민국의 수도는 어디인가요?”토큰화 (Tokenization)
이 두 문장을 토큰화하면 다음과 같다:질문: [CLS] 대한민국의 수도는 어디인가요? [SEP]
문맥: 서울은 대한민국의 수도입니다. [SEP]전체 입력 시퀀스를 합치면 다음과 같다:
입력 시퀀스: [CLS] 대한민국의 수도는 어디인가요? [SEP] 서울은 대한민국의 수도입니다. [SEP]
Token Type IDs: [0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1]
Attention Mask: [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
Padding
만약 max_token 길이가 20이라면, 나머지 2개의 토큰은 [PAD]로 채워진다:입력 시퀀스: [CLS] 대한민국의 수도는 어디인가요? [SEP] 서울은 대한민국의 수도입니다. [SEP][PAD] [PAD]
Token Type IDs: [0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0]
Attention Mask: [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0] -
모델의 출력
Extraction-based MRC에서는 답안을 생성하는 것이 아니라, 시작위치와 끝 위치를 예측하도록 학습한다.
즉, Generative가 아닌, Token Classification Task가 되는 것이다.
1.2.2 step_2 : Fine-tuning
토큰화된 각 토큰들이 모델의 embedding layer에서 벡터화되고 해당 벡터화된 토큰들에 대해 Extraction-based MRC Model이 학습을 진행한다.
이때 Extraction-based MRC Model이라고 함은 Pre-trained language model에 classifier를 얻은 것을 말한다.
이때 학습의 과정에서 Output은 각 token이 start position이 될 확률과
각 token이 end position이 될 확률을 내뱉게 되는데
이때의 Output 값에 대해서 실제 답의 start/end position과 cross-entropy loss를 계산하여 해당 로스만큼 학습이 진행되게 된다.
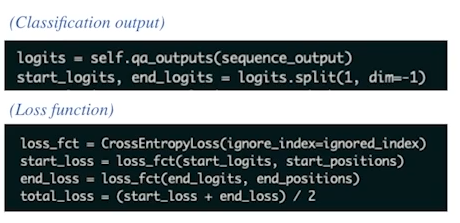
구체적인 코드 예시
# Classification output # 모델 출력인 sequence_output을 입력으로 받아서 질문에 대한 시작점과 끝점의 로짓을 계산함. logits = self.qa_outputs(sequence_output) # 로짓을 시작점과 끝점으로 나누며, dim=-1 은 마지막 차원을 기준으로 나누는 것을 말함. start_logits, end_logits = logits.split(1, dim=-1) # Loss function # 패딩 인덱스 따위는 무시(igonre_index) loss_fct = CrossEntropyLoss(ignore_index=ignored_index) # 예측, 실 start/end position 간 손실 계산 start_loss = loss_fct(start_logits, start_positions) end_loss = loss_fct(end_logits, end_positions) # 시작점 손실과 끝점 손실의 평균을 구하여 총 손실을 계산함. total_loss = (start_loss + end_loss) / 2
1.2.3 step_3 : Post-processing
최종적으로 모델이 내보내는 것은 시작점(Start position)과 끝점(End position)이 된다.
이때 숫자를 내보내는 것이 아닌, context와 question 각각에 해당하는 contextualize 벡터들에 대해서 scaler value로 내보냄으로써 일종의 각 postition의 시작 끝이 될 수 있는 점수중 가장 높은 점수를 갖는 위치를 start position과 end position으로 내보내게 되는 것 해당 position에 있는 값을 내보낸 후에는 해당 위치에 있는 span을 가져와 내뱉는다.
구체적인 예시
문맥 (Context)
“서울은 대한민국의 수도입니다.”질문 (Question)
“대한민국의 수도는 어디인가요?”모델의 출력
모델은 문맥에서 답변을 찾기 위해 시작점(Start position)과 끝점(End position)을 예측구체적 과정은 이하와 같다.
시작점(Start position): 모델은 "서울"이라는 단어의 시작 위치를 예측
끝점(End position): 모델은 "서울"이라는 단어의 끝 위치를 예측
- 토큰화 (Tokenization)
문맥과 질문을 토큰화합니다. 예를 들어, 문맥 "서울은 대한민국의 수도입니다."는 다음과 같이 토큰화될 수 있다:[서울, 은, 대한민국, 의, 수도, 입니다, .]
질문 "대한민국의 수도는 어디인가요?"는 다음과 같이 토큰화될 수 있다:[대한민국, 의, 수도, 는, 어디, 인가요, ?]
2. 벡터화 (Vectorization)
각 토큰을 임베딩 레이어를 통해 벡터로 변환한다. 이 벡터들은 모델이 이해할 수 있는 숫자 형태로 변환된다.
모델 학습 (Model Training)
모델은 이 벡터들을 입력으로 받아 학습합니다. 학습 과정에서 모델은 문맥 내에서 답변의 시작점과 끝점을 예측하는 방법을 배운다.예측 (Prediction)
모델이 예측한 시작점과 끝점은 다음과 같다:시작점: "서울"의 시작 위치
끝점: "서울"의 끝 위치
- Post-processing
모델은 예측한 시작점과 끝점을 기반으로 문맥에서 해당 범위를 추출한다. 이때, 모델은 단순히 숫자를 내보내는 것이 아니라, 각 위치에 대한 점수를 계산하여 가장 높은 점수를 갖는 위치를 선택한다.예를 들어, 모델이 "서울"의 시작 위치를 3, 끝 위치를 3으로 예측했다면, 문맥에서 "서울"이라는 단어를 추출하여 답변으로 내보낸다.
이때 주의할 것은 '서울'시작위치 끝위치에 해당하는 해당 숫자는 토큰화된 인덱스를 말하는 것으로 이하와 같다.
[서울, 은, 대한민국, 의, 수도, 입니다, .]여기서 각 토큰의 인덱스는 다음과 같다:
서울: 0
은: 1
대한민국: 2
의: 3
수도: 4
입니다: 5
.: 6
이렇게 해서 최종적으로 "서울"이라는 답변을 얻게 된다.
-
추가적으로 Post-processing에서는 불가능한 답을 제거하는데 다음과 같은 경우가 해당한다.
- End가 start보다 앞에 있는 경우
- 예측 위치가 context에 해당하는 token index가 아닌경우
- 미리 설정한 max_answer_length보다 길이가 더 긴 경우
-
위와 같은 로직을 반영하여 다음과 같이 최적의 답안이 찾아진다.
- start/end position에 대한 예측에서 logits가 가장 높은 N개를 찾아내기
모델은 문맥 내에서 답변의 시작점과 끝점을 예측하고 각 위치에 대해 logit 값을 계산한다. 그리고 이값이 높은 N개의 위치를 선택하는데, N이 5인 경우라면 시작점과 끝점 각각에서 로짓 값이 높은순으로 5개의 위치를 선택한다.
- 불가능한 start/end 조합을 제거한 후에
- 가능한 조합들을 score합이 큰 순서대로 정렬하고
가능한 모든 시작점과 끝점의 조합을 만들고 각 조합의 점수를 계산하는데, 이때 점수를 계산한다고 함은 시작점 끝점의 로짓값의 합을 말한다. 이 점수를 기준으로 조합을 정렬한다.
- score가 가장 큰 조합을 최종 예측으로 선정한다.
정렬된 조합 중에서 가장 높은 조합을 최종 예측으로 선택하며 이 조합이 모델이 예측한 최적 답변의 위치가 된다.
- Top-k가 필요한 경우 차례로 내보낸다.
여러개의 답변이 필요한 경우를 의미한다. 점수가 높은 순서대로 Top-K 조합을 선택하여 내보낸다. 예를들어 K가 3인경우에는 점수가 높은 순서대로 3개의 조합을 선택하여 내보낸다.
- start/end position에 대한 예측에서 logits가 가장 높은 N개를 찾아내기
2. 예시를 통한 output 과정 설명
문맥 (Context)
“서울은 대한민국의 수도입니다.”
질문 (Question)
“대한민국의 수도는 어디인가요?”
-
Start/End Position에 대한 예측
모델이 예측한 시작점과 끝점의 로짓 값이 다음과 같다고 가정:시작점 로짓: [0.1, 0.2, 0.9, 0.4, 0.3]
끝점 로짓: [0.1, 0.3, 0.8, 0.5, 0.2]여기서 로짓 값이 가장 높은 N=2개의 위치를 선택하면:
시작점: 2 (로짓 값 0.9), 3 (로짓 값 0.4)
끝점: 2 (로짓 값 0.8), 3 (로짓 값 0.5) -
불가능한 조합 제거
가능한 조합은 (2, 2), (2, 3), (3, 3)입니다. 여기서 (3, 2)는 불가능한 조합이므로 제거 -
조합 정렬
각 조합의 점수를 계산:(2, 2): 0.9 + 0.8 = 1.7
(2, 3): 0.9 + 0.5 = 1.4
(3, 3): 0.4 + 0.5 = 0.9
점수 순으로 정렬하면:(2, 2): 1.7
(2, 3): 1.4
(3, 3): 0.9 -
최종 예측
점수가 가장 높은 (2, 2) 조합을 최종 예측으로 선택. -
Top-k
Top-3를 원한다면, (2, 2), (2, 3), (3, 3) 순서로 내보낸다.
