1. LLM은 생각을 하는가?
-
LLM 자체에는 생각하는 능력이 없다.
-
LLM 또한 결국
Auto-Regressive Model이다.
즉, 단순히 다음 단어를 맞추는 모델이라는 것. -
그렇다면 아예 생각을 못하는 것일까?
- CoT: Chain-of-Thought
생각하는 과정을 모사하여 모델 입력으로 주면 성능이 올라간다.
경우에 따라 기존 모델이나Fine-tuned 모델보다 우수한 성능을 보이기도 한다.
- CoT: Chain-of-Thought
2. Chain-of-Thought
- CoT의 경우 자연어 형태일 때 가장 효과적으로 작동한다.
- 식만 적거나 변수 계산만 적시하면 효과가 미미하다.
- 답을 적고 이유를 적는 경우에는 효과가 없다.
- Auto-regressive이기 때문이다.
- CoT는 큰 모델에서만 작동한다.
- Reasoning의 경우 코드 데이터에 사전 학습이 된 경우에만 작동한다는 보고가 존재한다.
Zero-Shot Chain-of-Thought
Zero-shot CoT는 naive zero-shot 보다 다양한 분야에서 우월한 정확도를 보이는데, 특히 쉬운 문제보다 복잡한 문제에서 더욱 두각을 드러낸다.Few-shot CoT로 여러 예시를 생성한 후에 해당 예시로 Few-shot CoT를 수행하는 경우 정확도가 상승한다.
Reasoning extraction을 위한 Prompt의 경우 그 이후에 이유가 나오는 경우에만 효과가 있다. 의미가 없거나 잘못 지시를 전달하는 경우에 효과가 없다.
즉 Reasoning 과정에서 치명적인 실수는 추론 결과를 완전히 달라지게 하는데, 이러한 실수는
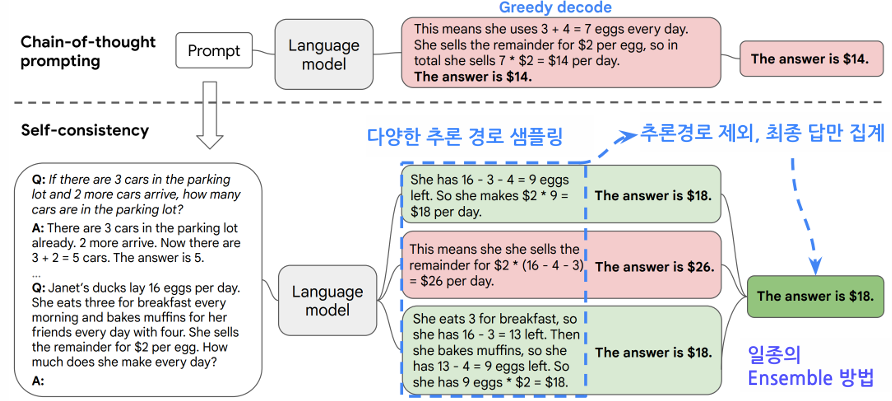
Greedy decoing을 통한 생성 과정에서 알아낼 방법이 없다.방법이 없나?
있다.Self-consistency
3. Self-Consistency
- Beam Search를 통해 가장 좋은 Reasoning path들로 추론하기 보다, Sampling을 통하여 다양한 Reasoning path들로 추론할 때 더욱 높은 정확도를 보인다.
- 낮은 Temperature >> 낮은 다양성 >>> 낮은 정확도
- 모델 크기가 클수록 Greedy decoding과의 격차가 증가
- Sample 개수가 많을 수록 정확도가 상승하다가 수렴한다.
4. Least-to-Most Prompting
- 어려운 문제를 그대로 풀지 말고 쉽고 작은 문제들로 분리해보자.
- 예를 들어 "365 x 24 x 60"이라는 계산을 "365 x 24 = 8760", "8760 x 60 = 525600" 처럼 단계별로 나누어 풀이한다.
- 이 방법론은 CoT 보다 산수 연산 및 기호 추론 과제에서 우수한 성적을 기록했다.
- 계산에 필요한 단계가 많을 수록 Naive한 CoT보다 높은 정확도를 보인다. 특히 3단계 이상의 복잡한 계산에서 CoT 대비 15-20% 높은 정확도를 기록했다.
- Few-shot 예시에서 단계 수가 달라지는 등, 예시와 다소 달라져도 일반화를 Naive CoT보다 잘한다.
- Code 데이터에 학습된 LLM에서 더욱 좋은 정확도를 보여줬다.
# CoT 방식
def calculate_total(items):
return sum(item.price * item.quantity for item in items)
# Least-to-Most 방식
def calculate_total(items):
# 1. 각 아이템의 개별 가격 계산
item_totals = []
for item in items:
single_total = item.price * item.quantity
item_totals.append(single_total)
# 2. 전체 합계 계산
final_total = sum(item_totals)
return final_total5. Decomposed Prompting
- 작은 문제(Sub-task)를 사전에 정의하고
- Decomposer와 Sub-task handler가 상호작용하게 하는 것.
- 실제 적용 예시로 "주어진 텍스트에서 감정 분석하기" 태스크를 다음과 같이 세분화할 수 있다
- 문장 분리
- 각 문장별 감정 레이블링
- 전체 문맥 고려한 최종 감정 도출
- Decomposed prompt는 Least-to-Most보다 뛰어난 정확도와 일반화를 보여줬다.
- 이는 처리 길이가 길어져도 그 정확도와 일반화를 뛰어나게 보여준다는 점에서 주목할만 하다.
- 외부 기능을 활용하는 형태로도 Sub-task handler 활용이 가능하다:
- 번역 작업에서 Google Translate API 연동
- 이미지 분석에서 Vision API 활용
- 데이터베이스 쿼리 실행을 위한 SQL 엔진 연결
6. ReAct
- ReAct 단독으로는 정확도가 좋지 않아서 Self-consistency와 함께 사용한다. 이 경우 복잡한 추론 문제에서 단독 사용 대비 25% 이상 성능이 향상된다.
- ReAct는 같은 검색을 반복하거나 잘못된 검색 결과로 추론이 틀리는 경우가 많다. 예를 들어 "파리의 인구는?" 같은 질문에 대해 동일한 검색을 반복하는 순환적 오류가 발생한다.
- CoT-SC는 Hallucination(환각) 현상에 취약하여 추론이 틀리는 경우가 많은데
- CoT-SC -> ReAct:
Cot-SC에서 다수 답안이 없는 경우 ReAct로 가고 - ReAct -> CoT-SC:
ReAct로 추론이 실패했을 경우 CoT-SC로 가는 것이 좋다.
- CoT-SC -> ReAct:
- ReAct는 In-context learning 방식 보다 Fine-tuning 방식이 좋은 정확도를 발휘한다.
- Fine-tuning 적용 시 고려사항:
- 최소 10만 건 이상의 학습 데이터 필요
- 도메인별 특화된 프롬프트 템플릿 구성
- 검색-추론-행동의 균형있는 데이터셋 구성

헤매는 만큼 자기 땅이다.