Further Reading
단일 머신을 사용한 모델 병렬화 모범 사례
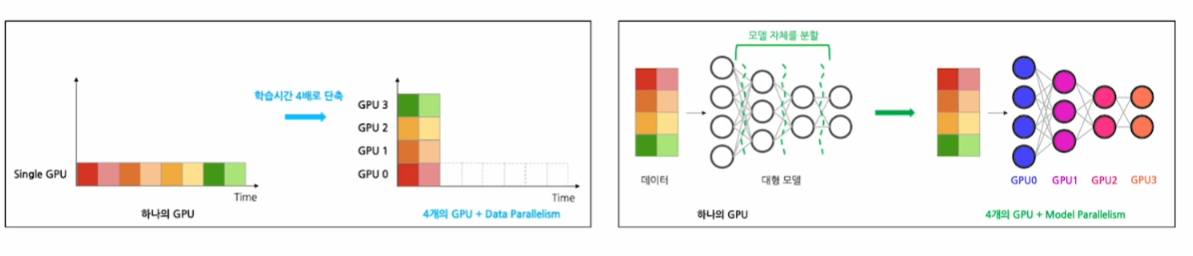
Model Parallelism
큰 모델을 여러 GPU에 나누는 방법론
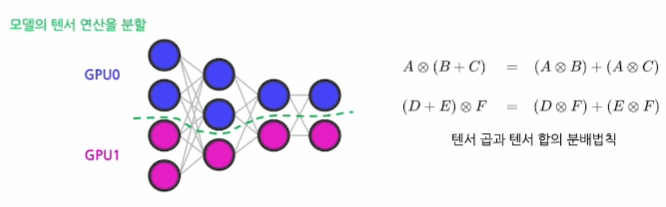
1. Tensor Parallelism
- 텐서 연산을 여러 차원의 슬라이스로 나눈 후에 GPU 들에 할당하여 처리하는 패러다임이다.
- 텐서 연산을 나누어 수행해도 똑같은 값을 얻을 수 있다는 개념에서 시작
- 크기가 큰 텐서 연산도 수행 가능하지만, 적용 과정이 복잡함
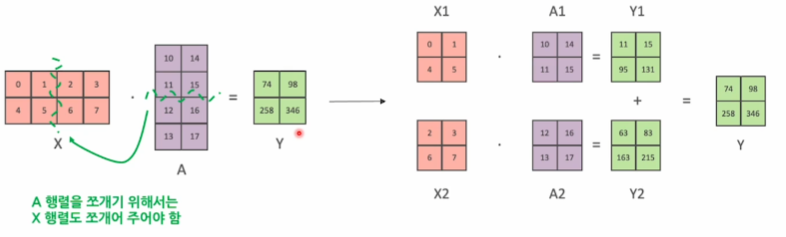
- 나누는 것은 주로 weights 행렬이다.
- inputs x weights = outputs
- 어느 방향으로 텐서를 나눌 것인지에 따라 2가지로 분류
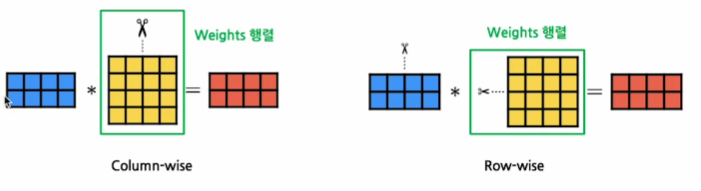
- column-wise
텐서를 세로로 쪼갠다.
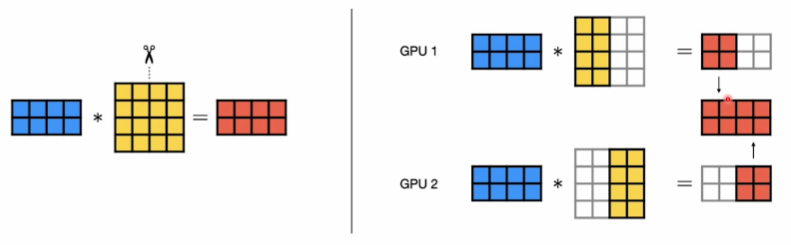
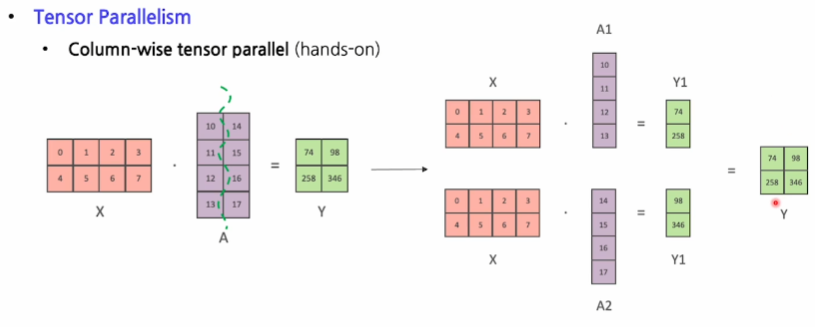
- input 행렬이 주어졌을 때, 각 GPU는
weight행렬의 열 부분을 나누어 계산 - 각 GPU의 output 값의 열 부분만 계산
-> output 행렬의 전체적인 차원을 완성하기 위해 다른 GPU의 계산 결과가 필요(퍼즐 맞추기) - Forward Pass:
각 GPU의 output 값을 그대로 이어붙여 하나의 전체 output 행렬을 형성 - Backward Pass:
각 GPU의 열 단위 gradients를 모든 GPU에 동일하게 공유
- column-wise
-
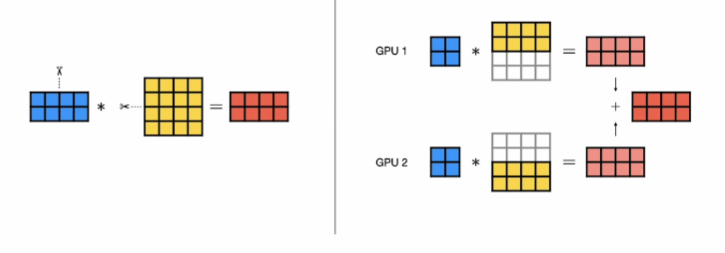
row-wise
텐서를 가로로 쪼갠다.
- input 행렬이 주어졌을 때, 각 GPU가
weight행렬의 행 부분을 나누어 계산 - 각 GPU의 output 행렬 차원은 동일
-> output 값을 합산하여 동일한 값으로 출력 - Forward Pass
각 GPU의 output 값을 합산하여 동일한 값으로 출력 - Backward Pass
각 GPU의 행 단위 gradients를 그대로 이어붙여 전체 gradients를 형성
- input 행렬이 주어졌을 때, 각 GPU가
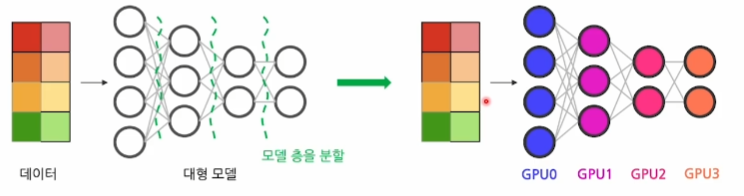
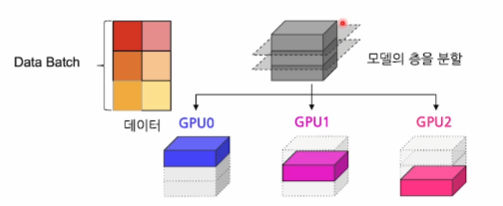
2. Pipeline Parallelism
- 모델의 여러 층을 스테이지 단위로 나우어서 각각의 GPU에 분재하고 데이터들을 나누어 순차적으로 넣어 주는 패러다임
- 각 GPU가 서로 다른 레이어를 처리하므로, 계산 효율성을 높이고 메모리 사용량을 분산할 수 있음
- 모든 GPU가 일할 수 있게 하는 효율적인 패러다임이지만, 스테이지 간 연산량에 차이가 클 경우 대기 시간(latency)이 길어질 수 있음
단계
1. Initialization
- 모델을 연속적인 여러 스테이지로 나누고
- 각각의 스테이지들을 GPU에 할당한다.
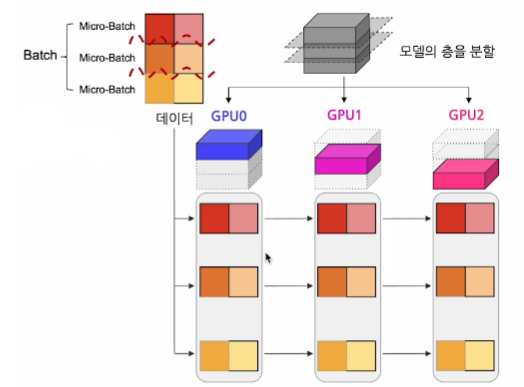
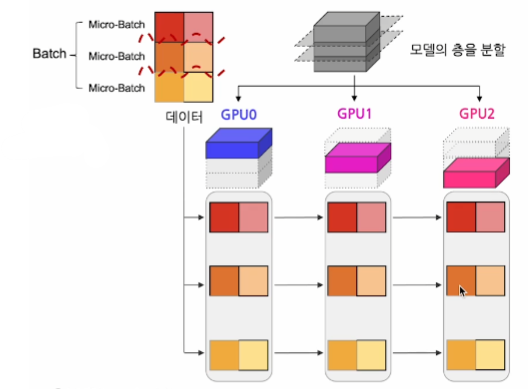
2. Forward Pass
- 데이터 Batch를 더 작은 단위로 쪼갬
- 쪼개진 Micro-batch 데이터를 순차적으로 주입
- 왜 잘게 쪼개서 주입하나요?
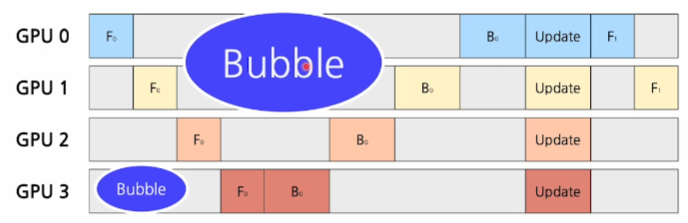
각 GPU에서는 이전의 스테이지가 끝나야지만 연산을 시작할 수 있음
GPU가 연산을 하지 못하는 유휴 시간을Pipeline Bubble이라 지칭
위와 같은 버블 타임을 줄이려면 데이터를 쪼개어 순차적으로 넣어주면 된다.
쪼개진 데이터 단위의 크기만큼 GPU가 쉬기 때문!
다만, 그렇다고해서 너무 작게 분해할 경우 어쨌뜬 현재 Multi-GPU를 사용하는 만큼 그 통신 비용도 존재하기에 통신비용과 데이터사이즈 간에 적절한 최적을 찾아야함
3. Backward Pass
마이크로배치들이 스테이지에 들어간 역순으로 gradients 계산 모델 업데이트

동기화/비동기화 Pipeline

-
Synchronous Pipeline
각 GPU가 Forward Pass, Backward Pass의 순서를 지켜 처리하여 마이크로배치의 gradients를 동기적으로 집계됨- Forward 연산을 마치기ㄱ 전까지 Backward 연산을 실행하지 않는다.
모든 Backward 연산을 마치면 한번에 모델 update를 진행한다.
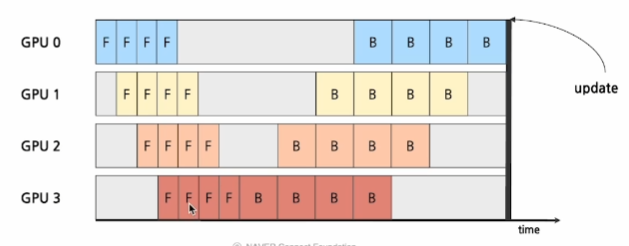
- Forward 연산을 마치기ㄱ 전까지 Backward 연산을 실행하지 않는다.
-
Asynchronous Pipeline
각 GPU가 Forward Pass, Backward Pass를 번갈아 처리함으로써 gradients가 각 GPU에 따라 비동기적으로 집계됨- 한 마이크로 배치의 Forward 연산과 (연산가능한 경우) Backward Pass를 번갈아가면서 수행함
- 각 파이프라인 단계가 독립적으로 작동 (다른 GPU 완료 여부에 영향 X)
- 단계 간의 동기화 지점이 없어 더욱 빠른 다음 마이크로배치 처리 <- Bubble 추가 감소
- 파라미터를 모든 GPU가 공유하지 않고 GPU별로 일부분을 개별 관리 (
DDP와 같은 원리) - 통신비용이 발생하지 않는다는 장점이 있으며 보다 효율적이게 GPU를 쓸 수 있음
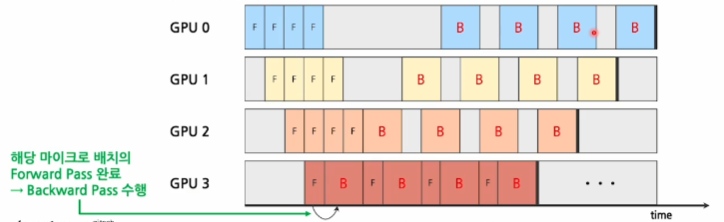
- 한 마이크로 배치의 Forward 연산과 (연산가능한 경우) Backward Pass를 번갈아가면서 수행함
- 병렬화의 효과
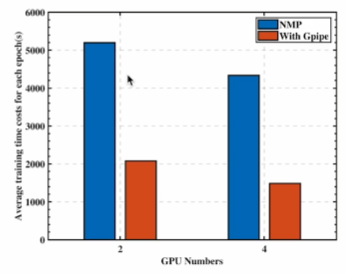
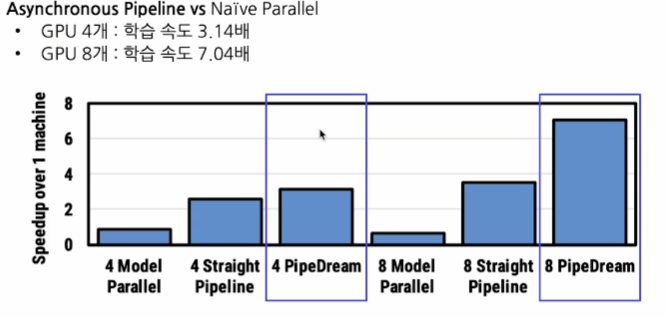
병렬 학습의 Trade-off
학습 속도, 메모리 효율성, 수렴 특성 간의 다양한 트레이드오프가 존재
Trade-off
- 학습 속도, 메모리 효율성, 수렴 특성은 서로 충돌하는 경우가 많다.
- 마이크로 배치 수를 늘리면:
- 더 빈번한 단계 통신이 필요해져서 오버헤드가 증가할 수 있다. (메모리 효율성 감소).
- 때로는 모델의 정확도가 낮아지고 (수렴 감소).
- 마이크로 배치 수를 줄이면:
- GPU 메모리 효율성이 감소하게 된다.
- 파이프라인 단계를 줄이면:
- 파이프라인 크기가 증가하여 파이프라인 Bubble이 더 많이 발생한다.
프레임워크 비교:
프레임워크 개발사 유형 속도 향상 메모리 효율성 수렴 GPipe 동기 3 1 3 PipeDream Microsoft 비동기 3 1 1 DAPPLE Alibaba 동기 2 4 4 PipeMare SambaNova Systems 비동기 4 2 2 어떤 전략도 모든 장점을 동시에 달성하기는 힘들다.
동기화 vs 비동기화 pipeline 비교
| 분류 | Synchronous Pipeline | Asynchronous Pipeline |
|---|---|---|
| 학습 속도 | 학습 속도가 크게 증가하지만 동기화 과정에서 병목 현상이 발생할 수 있음 | 동기화 과정이 없으므로 학습 속도 크게 증가 |
| 메모리 효율성 | 모든 GPU에서 gradients들이 동기화되어야 하기 때문에 메모리 효율성이 상대적으로 낮음 | 동기화 과정에서 생기는 idle time을 최소화하기 때문에 메모리 효율성이 높음 |
| 수렴도 | 안정적이고, 모델의 정확도 높음 | 각 GPU에서 비동기적으로 gradients를 업데이트하기 때문에 불안정하고, 정확도 상대적으로 낮음 |
| 장점 | 구현이 상대적으로 쉬움 | 학습 속도, 메모리 효율성 증가 |
| 단점 | Gradient 동기화 과정으로 인한 idle time 발생 | 구현이 매우 복잡함 |
| 사용 전락 | 동일한 GPU를 여러 개 사용하고, 모델이 안정적으로 수렴해야 할 때 사용 | GPU 환경이 각각 다르고, 메모리 효율성을 극대화할 때 사용 |
요약
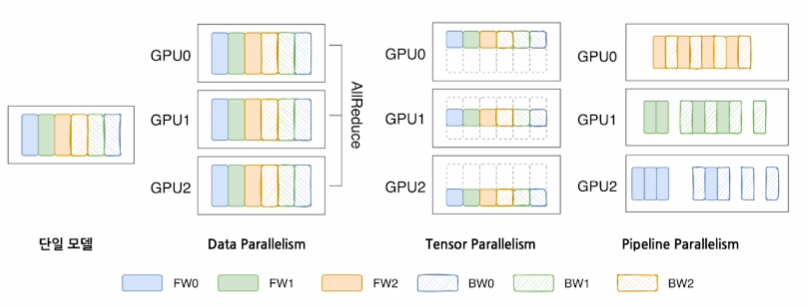
| 구분 | Data Parallelism | Tensor Parallelism | Pipeline Parallelism |
|---|---|---|---|
| 전략 | 데이터를 여러 GPU에 분산하여 각 GPU가 모델의 복사본으로 병렬 처리 | 모델의 텐서(weights)를 여러 GPU에 분산하여 각 GPU가 모델의 일부만 처리 | 모델의 여러 층들을 GPU에 분산하여 각 GPU가 순차적으로 모델 일부를 처리 |
| 장점 | 구현이 쉽고, 큰 데이터셋 처리에 효과적 | GPU당 메모리 사용량 감소 | 매우 큰 모델 처리 가능하고, 메모리 부담 감소 |
| 단점 | 각 GPU에 모델 전체가 필요해 메모리 한계 존재 | GPU간 통신이 증가하여 병목(bottleneck) 가능 | 모델 간 데이터 전달로 인한 지연 발생 |
| 사용 전략 | 큰 데이터셋과 중간 크기 모델 학습에 적합 | GPT-3와 같은 초대형 모델 학습에 적합 | 깊은 구조의 대형 모델에 적합 |
3. 최적화, 경량화 요약
어떻게 하면 다양한 상황 속에서 AI 모델들을 더가볍게 만들고, 한정된 자원을 효율적으로 활용할 수 있을까?
최적화경량화키워드를 잘 생각해라
-
모델 경량화
Pruning
Knowledge Distillation
Quantization

-
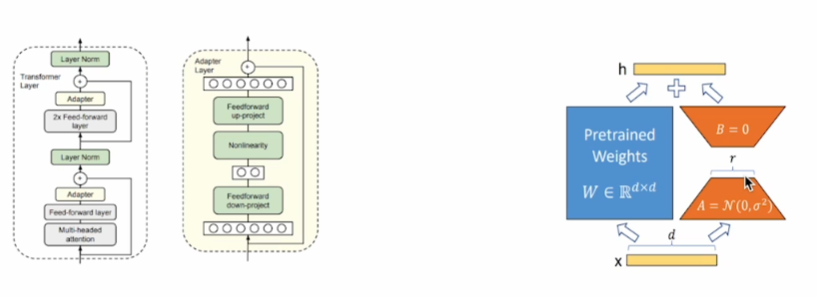
PEFT
Adapter
Low-Rank Adaptation(LoRA)
QLoRA
- 병렬 컴퓨팅
Data Parallelism
Model Parallelism