[NOTA 기업해커톤]오디오 언어모델 경량화
1. 개요
본 리포트는 2025년 1월 10일 부터 2월 11일까지 진행한 오디오 언어모델 경량화 프로젝트에 대한 Wrap-up 보고서이다.
1.1 주제 설명
오디오 데이터와 텍스트 입력을 기반으로 텍스트를 생성하는 멀티모달 언어 모델을 다루며, 성능 하락을 최소화하면서 경량화를 목표로 한다. 해당 모델은 오디오 인코더를 통해 음성 및 비음성 특징을 추출하고, 이를 Window-level Q-Former를 통해 새롭게 임베딩하여 입력된 텍스트와 함께 LLM에 전달한다. LLM은 이를 바탕으로 적절한 텍스트 응답을 생성한다.
1.2 평가 방법
1.2.1 WER (Word Error Rate)
음성 인식 결과의 정확도를 평가하는 지표로, 원본 텍스트(참조 텍스트)와 예측된 텍스트 간의 차이를 기반으로 계산된다. 수식은 다음과 같다.
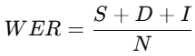
S: 대체 단어 수, D: 삭제 단어 수, I : 삽입 단어 수, N: 참조 문장 총 단어 수
1.2.2 SPIDEr (SPICE + CIDEr)
이미지 캡션 및 오디오-텍스트 생성 모델에서 일반적으로 사용되는 메트릭으로, SPICE와 CIDEr 점수의 조합이다. 각각의 수식은 다음과 같다.
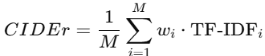
M: 참조 문장 수, wi: n-gram 가중치, TF-IDFi: 각 n-gram의 TF-IDF값
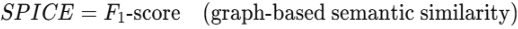
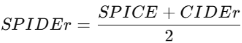
1.2.3 Inference time (second)
모델이 입력 데이터를 처리하여 출력을 생성하는데 걸리는 시간으로써 본 프로젝트에서는 첫 토큰 생성 시간과 후속 토큰 생성 시간의 합으로 계산한다.
1.2.4 Memory Use (GB)
모델이 추론 과정에서 사용하는 메모리 양을 측정한다.
1.3 데이터 구성
LibriSpeech, MusicNet, Clotho, WavCaps, GigaSpeech, AudioCaps 6가지의 공개 데이터셋으로 주로 음성 인식, 음악 분석, 오디오 캡션 및 기타 오디오 처리 작업에 사용된다.
| AudioCaps | 1초~1분 정도의 환경소리 |
|---|---|
| MusicNet | 55초~18분 정도의 음악 |
| Clotho | 15~30초 정도의 환경소리 |
| GigaSpeech | 0~30초 정도의 음성 데이터 |
| WavCaps | 1초~5분 정도의 환경소리 |
| Libri Speech | 0~30초 정도의 음성 데이터 |
2. 팀 구성 및 역할
| 팀원 | 역할 |
|---|---|
| 홍성균 | 팀장, baseline 작성, 데이터EDA, 모델 탐색 및 실험 |
| 장요한 | 모델 탐색 및 실험 |
| 이정민 | Nvidia Canary 모델 개발, 전체 모델 최적화 실험 |
| 박규태 | CED 아키텍처 통합, 지식 증류(Knowledge Distillation), 모델 탐색 및 실험 |
| 한동훈 | streamlit관리, 데이터 EDA |
| 강신욱 | 데이터 EDA, 모델 탐색 및 실험 |
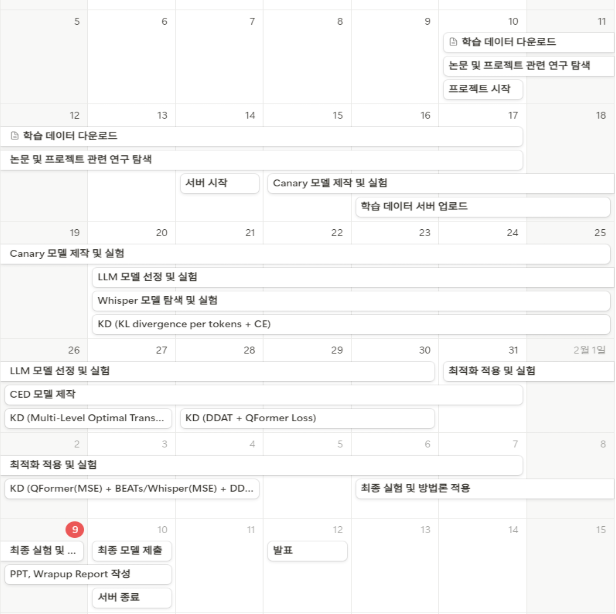
3. 프로젝트 타임라인
4. 프로젝트 수행 내용
4.1 Model Centric
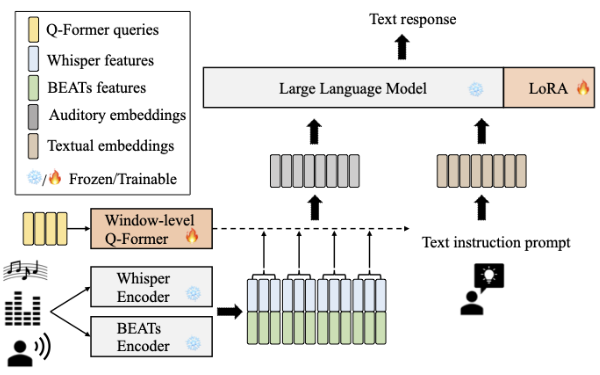
SALMONN(Speech Audio Language Music Open Neural Network) 구조에서 전체적인 모델 성능과 GPU 메모리 사용량에 가장 큰 영향을 미치는 요소는 LLM, Whisper Encoder, 그리고 BEATs Encoder이다. 실험을 통해 이 두 구성 요소의 성능에 따라 모델의 성능 변동이 크며, GPU 메모리 사용량도 달라지는 것을 확인할 수 있었다. 따라서 모델 성능을 유지하면서도 경량화를 목표로, 해당 구성 요소를 교체하거나 최적화하는 시도를 진행했다.
4.1.1 Audio Encoder 변경: Speech data Recognition
openai/whisper모델에 관하여 허깅페이스에서 제공하는 ASR 리더보드를 통해 얻을 수 있는 정보는 다음과 같다.
| 모델 | params | 평균 WER | LS Clean | LS Other | |
|---|---|---|---|---|---|
| openai/whisper-large-v3 | 1.54B | 7.44% | 2.01 | 3.91 | |
| openai/whisper-large-v3-turbo | 809M | 7.83% | 2.1 | 4.24 | |
| openai/whisper-large-v2 | 1.54B | 7.83% | 2.83 | 5.14 | |
| openai/whisper-medium.en | 764M | 8.09% | 3.02 | 5.85 | |
| openai/whisper-small.en | 242M | 8.59% | 3.05 | 7.25 |
이를 바탕으로 총 두가지 실험을 진행 하였는데, 먼저 동일 모델에서 Whisper 부분만을 교체하는 경량화 실험을 진행하였고, 아래 표와 같은 결과를 얻을 수 있었다. 실험에 따르면 Whisper-small.en의 경우 동일 조건하에서 Whisper-large-v3 보다 inference time을 0.1s 이상 줄일 수 있었지만, 그 성능이 ASR에서는 8% 이상 하락하는 차이를 보였고, AAC의 경우 토큰이 max_token 까지 반복 생성되는 이유로 측정이 불가하였다.
| 모델 | ASR (WER) | AAC (SPIDEr) | TTFT (s) | TPOT (s) | Inference time(s) | Memory (GB) |
|---|---|---|---|---|---|---|
| Whisper-large-v3 | 11.38% | 0.1621 | 0.1858 | 0.0228 | 0.2086 | 5.9759 |
| Whisper-small.en | 19.62% | ERROR | 0.0921 | 0.0234 | 0.1155 | 3.7484 |
다음으로는 앞선 실험에서 채택된 Whisper-large-v3과 그 Encoder 부분만 활용하도록 모델링한 Whisper-large-v3-turbo 간의 A/B test를 진행한 결과 다음과 같은 결과를 얻을 수 있었다. 단, 프로젝트가 진행됨에 따라 다른 데이터셋으로 진행하였기 때문에 Whisper-large-v3의 점수가 앞선 실험과 동일하지 않다.
| 모델 | ASR (WER) | AAC (SPIDEr) | TTFT (s) | TPOT (s) | Inference time(s) | Memory (GB) |
|---|---|---|---|---|---|---|
| Whisper-large-v3 | 8% | 0.336 | 0.2034 | 0.0416 | 0.2450 | 9.1771 |
| Whisper-large-v3-turbo | 7.96% | 0.3224 | 0.2070 | 0.0420 | 0.2491 | 9.1771 |
실험 결과, Whisper-large-v3-turbo는 Whisper-large-v3보다 파라미터 수가 약 절반으로 적지만, 프로젝트 아키텍처가 Whisper의 Encoder만 활용하기 때문에 실제 파라미터 수는 비슷하며 메모리 및 추론 효율 차이는 실험 오차 수준으로 미미했다. 모델 로드 시간을 줄이기 위해 Whisper-large-v3-turbo를 Speech Audio Encoder로 선택했다.
4.1.2 Audio Encoder 변경: Non-Speech Data Processing
CED는 VIT 기반 모델로 다수의 더 큰 파라미터를 가지고 있는 성능 좋은 Teacher 모델들로 부터 지식 증류를 받아 작은 파라미터를 가짐에도 좋은 성능을 보이도록 구현된 모델이다. 구현된 CED 모델들은 CED-base(86M), CED-small(22M), CED-mini(10M), CED-tiny(5.5M)가 있으며, 모두 90M 파라미터를 가진 BEATs보다 작은데 불구하고 비교된 벤치마크에서 BEATs 보다 좋은 성능을 보이고 심지어 가장 작은 CED-tiny 마저도 BEATs에 비견되는 성능을 보여준다.(Heinrich Dinkel.2023) (Liu, J., Li, G. 2024)
CED 모델을 SALMONN 아키텍처에 통합하기 위해, 기존 BEATs와 동일하게 인코더만 활용하도록 CED 모델의 소스코드를 일부 수정했다.
또한 현재 아키텍처는 최대 30초 길이의 데이터만 사용하도록 제한되어 있으며, 이보다 긴 데이터는 30초로 잘라서 입력으로 사용된다. 샘플링 레이트 16,000 기준으로 최대 입력 길이는 3001이 되는데, 원본 CED 소스코드에서는 target length가 1012로 설정되어 있다. CED 모델은 긴 입력 데이터에 대해 디코더 생성 시간 지연 등의 이슈 해결 위해서 입력을 target length 단위로 분할하여 처리하도록 설계되어, 하나의 입력이 여러 부분으로 나뉘게 된다. 그 결과, 최종적으로 QFormer에 전달할 때 Whisper 모델의 출력과 concat하는 과정에서 차원 오류가 발생하게 된다. 이를 방지하기 위해 target length를 3001로 변경하여, 하나의 입력이 여러 부분으로 분할되지 않게 하여 차원 오류가 발생하지 않도록 수정하였다.
| 모델 | ASR (WER) | AAC (SPIDEr) | TTFT | TPOT | Inference time | Memory |
|---|---|---|---|---|---|---|
| BEATs | 11.58% | 0.3262 | 0.2065 | 0.0407 | 0.2472 | 9.1761 |
| CED-base | 9.65% | 0.3111 | 0.1747 | 0.0382 | 0.213 | 9.1398 |
| CED-small | 9.44% | 0.3091 | 0.1735 | 0.0388 | 0.2109 | 8.8325 |
| CED-mini | 10.58% | 0.3115 | 0.1735 | 0.0381 | 0.2116 | 8.8487 |
| CED-tiny | 15.49% | 0.2886 | 0.173 | 0.038 | 0.2109 | 8.8325 |
실험은 SALMONN 아키텍처에서 LLM은 meta-llama/Llama-3.2-3B-Instruct, Whisper는
Whisper-large-V2 을 고정하고 같은 데이터셋(version-2)에 대해서 같은 훈련 조건 하에서 진행되었다. 해당 실험 결과, BEATs 대비 AAC는 소폭 하락하는 대신에 CED-base, CED-small 에서 ASR 점수가 큰 폭으로 향상하는 것을 볼 수 있었고 Inference time 역시 최대 약 14.7% 개선 되었으며 (0.2472 초 → 0.2109 초), 메모리 또한 모든 모델에서 개선되는 것을 확인할 수 있었다. 특히 CED-mini와 CED-tiny을 비교해보았을 경우 각각 10M, 5.5M 되지 않는 BEATs와 10 배~18 배 정도 차이나는 파라미터의 차이에도 불구하고 BEATs와 비슷하거나 비교될만한 성능을 보여주었다.
최종적으로 CED-base 대비 CED-mini, CED-tiny는 다른 CED 모델과 비교해보았을 때 작은 파라미터로 인해서 성능 하락을 보였다. 동일 데이터셋에서 실험한 결과, ASR에서는 각각 약 8.8%, 약 37.7% 하락하였다(WER: 9.65% → 10.58%, 9.65% → 15.49%). AAC는 CED-mini는 비슷하였으나 CED-tiny는 약 7.23%이 악화되었다(SPIEr: 0.3111 → 0.3115, 0.3111 → 0.2886). 실험 결과 CED-mini, CED-tiny는 명백한 성능 하락을 보여서 후보에서 최종적으로 제외되었다.
CED-small은 CED-base와 거의 4배가(86M → 22M) 차이나는 파라미터 크기에도 불구하고 더 좋거나 거의 비견되는 성능(ASR: 9.65% → 9.44% , AAC: 0.3111 → 0.3091)을 보여주었다. 또한 CED-base와 비교했을 시에 Inference 속도는 약 0.99% 향상되었고 (0.213 → 0.2109) 메모리 사용량은 약 3.36% 감소하였다(9.1398 Gbytes → 8.8325 Gbytes). 해당 결과로서 CED-small이 최종적인 모듈로서 채택하였다.
4.1.3 LLM 변경
더 낮은 Memory Use와 Inference Time을 가져갈 수 있도록 벤치마크에서 좋은 성능을 보이며, 프로젝트에 적절한 크기라고 판단되는 Llama계열과 Qwen 계열 모델들에서 각각 동일 조건을 갖춘 뒤 언어모델만을 바꿔 A/B test로 실험을 진행하였다.
| 모델(Llama) | ASR (WER) | AAC (SPIDEr) | TTFT | TPOT | Inference time | Memory |
|---|---|---|---|---|---|---|
| Llama-3.2-3B-Instruct | 9.21% | 0.3291 | 0.1748 | 0.0397 | 0.2145 | 8.8994 |
| Qwen2.5-1.5B-Instruct | 9.13% | 0.2508 | 0.1790 | 0.0442 | 0.2232 | 5.7855 |
| Llama-3.2-1B-Instruct | 15.52% | 0.2803 | 0.1565 | 0.0228 | 0.1793 | 5.2051 |
| Qwen2.5-0.5B-Instruct | 10.44% | 0.2487 | 0.166 | 0.0327 | 0.1987 | 3.8272 |
실험 결과를 통해 알 수 있는 바, Llama 계열은 AAC에서, Qwen 계열은 ASR 에서 더 높은 성능을 보인다. 본 프로젝트의 목적은 최적화 및 경량화에 있기에 성능과 Inference time 및 Memory 와의 Trade-off 관계를 고려하여 가장 낮은 메모리 사용량을 지님에도 준수한 성능을 보이는 Qwen2.5-0.5B-Instruct로 LLM을 변경하였다.
4.1.4 모델 구조 변경(Canary)
Canary는 Nvidia에서 제작한 ASR multi-lingual multi-tasking 모델이다.
Canary 모델은 Whisper 모델과 다르게 CNN과 Transformer를 결합한 Conformer 구조를 인코더로 사용한다. 이는 오디오를 하나의 이미지 데이터처럼 인식하여 Convolution을 통해 특정 범위 kernel에 속하는 오디오 끼리 feature를 압축하고, 이를 트랜스포머를 이용하여 Attention을 학습함으로써 전체 오디오의 표현 이해력을 높인다.

또한 Canary를 기본 Conformer에서 최적화 된 FastConformer를 사용한다. Feed Forward 병렬화 및 Linear Attention 등으로 연산 복잡도를 O(N) 수준으로 최적화 하여 기본 트랜스포머 및 Conformer 아키텍처보다 최대 4배 빠른 속도를 자랑한다.
마지막으로 Canary Model은 Whisper V3의 1.5B 모델보다 더 적은 1B의 모델 크기를 가지고 있다. 최종적으로 Huggingface Open ASR Leader board에서 종합 성능 1위를 차지하였으며 그 결과는 다음과 같다.
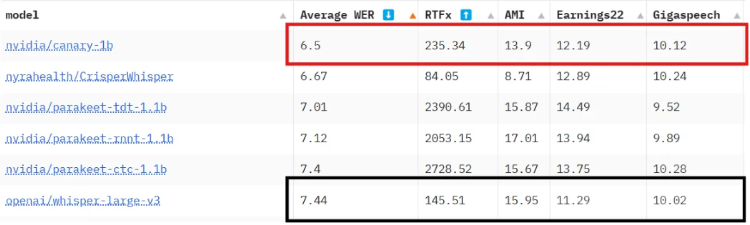
RTFx는 1초에 모델이 추론하는 오디오 데이터셋 개수에 1초에 연산에 필요한 시간으로, 이 값이 크면 더 빠른 추론이 가능하다. 이 지표에 따라 Canary 모델의 일반 성능과 속도에 있어서 모두 Whisper V3 Large 보다 좋은 점수를 내었기 때문에 오디오 인코더 모델을 변경하는 것을 시도하였다.
오디오 인코더 모델만 변경하고 나머지 모델 및 데이터셋을 동일 조건으로 한 결과는 다음과 같다.
| 인코딩 모델 | ASR | AAC | TTFT | TPOT | Inference Time | VRAM(GB) |
|---|---|---|---|---|---|---|
| Canary | 23.13% | 20.31% | 0.1422 | 0.0306 | 0.1728 | 9.06 |
| Whisper V2 | 8.98% | 29.78% | 0.2098 | 0.0427 | 0.2525 | 9.17 |
실험 결과 Latency에서 32%의 속도 향상을 보였고, VRAM에서 110MB 정도의 감량 효과를 볼 수 있었다. 하지만 ASR와 AAC에서 기존 Whisper V2에 비해 매우 낮은 점수를 기록하였다. 실제 Canary 단독으로 ASR에 적용할 경우 나오는 점수는 3%로 매우 낮은데 이런 결과가 나오는 이유는 다음과 같다.
1) Conformer Encoder의 특성이 Window-level Q-Former와 부조화
Conformer의 컨볼루션 층은 kernel과 stride로 윈도우 특징을 추출한다. 이 연산은 해당 윈도우 내 정보만 보존하고, 그 이후의 글로벌 어텐션이 장기 문맥을 모델링합니다. 그러나 Window-level Q-Former가 별도의 추가 윈도우를 적용하면서, Conformer의 Attention이 활용할 수 있는 문맥이 잘린다. 반면, Whisper의 Transformer Encoder는 원래부터 시퀀스 단위 처리를 기반으로 동작하기 때문에, 작은 윈도우로 나누어도 정보 손실이 적다.
이를 해결하기 위해서는 Conformer 전용의 CNNC, Conformer 구조의 Adpater 레이어를 제작하여야 한다. 하지만 이 때 반대로 생각하면 CNNC Adapter 레이어에 의해 BEATs 어쿠스틱 인코딩 모델이 학습이 저하되는 것을 발견하여, 두 방식이 서로 고착되는 문제가 발생했다.
2) Bert-Large 강제화
Whisper V2 모델의 Output Vector는 768로 이는 Q-former가 기본적으로 사용하는 Bert-base 모델의 Input Size와 동일하다.
하지만 실제 Canary 모델의 Output Vector는 1024로 되어 있고, 이것 때문에 Projection을 수행하거나, Q-former의 BERT 모델을 large로 교체해야 한다. 이 때 Projection Layer는 표현 벡터를 투영할 때 파라미터 개수가 너무 빈약하여 실제 Loss가 잘 떨어지지 않으며, 이에 따라 Bert-large를 사용하여 Q-former를 구동해야 했고, 이것은 VRAM 사용량이 더 증가하는 결과를 보였다. 이에 따라 최종적으로 Canary 모델은 사용하지 않는 것으로 결정했다.
| 인코딩 모델 | Base VRAM | Large VRAM |
|---|---|---|
| Canary | 9.06 | 10.37 |
4.1.5 지식증류
본 프로젝트는 최대한 높은 성능을 유지하면서도 모델의 경량화를 극대화하는 것을 목표로 한다. 이를 위해, 고성능의 teacher 모델을 활용하여 성능을 향상시키고, 동일한 파라미터 수 내에서 상대적으로 우수한 성능을 구현할 수 있도록 지식 증류 기법을 적용하는 것이 효과적일 것이라 판단하였다. 실험에 사용된 모든 teacher 모델은, SALMONN에서 직접 학습하여 공개한 vicuna-7b 기반 모델과 NOTA 측에서 학습하여 공개한 LLaMA-3b 기반 모델 사전에 학습된 두 가지의 공개 모델들을 활용하였다.
1) KL divergence per tokens + CE
| 모델 | ASR | AAC |
|---|---|---|
| LLaMA-3.2-3B-Instruct | 8.98% | 0.2978 |
| LLaMA-3.2-3B-Instruct (distilled from vicuna-7b) | 10.37% | 0.2547 |
첫 번째로는 최종 output에 대한 KL divergence와 CE 조합을 통한 Loss 조합을 시도했으며 KL divergence가 과도하게 폭증하는 문제가 있어 초반에 잘못 수렴하는 것을 방지하기 위해서 KL divergence에 0.05의 가중치를, CE에 0.95 가중치를 부여하여 진행하였다.
KL divergence를 적용을 위해 output의 timestamp 차이는 padding 하였고, vocab 사이즈는 nn.Linear로 맞춰 주었다. 후에 완전히 padding value로만 이루어진 행에 대해서는 valid mask를 통해서 Loss 계산 시에 제외하게 하였다.
실험은 두 모델 다 Whisper-large-v2 + BEATs 조합으로 같은 데이터셋(version-1)으로 같은 훈련 조건 하에서 진행되었다. 결론적으로 같은 훈련 시간 후에 비교된 결과, 오히려 distill된 모델이 베이스라인 모델에 비해서 하락하였다.이는 비교를 위한 충분한 훈련 시간이 확보되지 않아 수렴이 이루어지지 않았으며, KL divergence 계산을 위한 차원 변환 과정에서 두 모델 간의 직접적인 비교가 정확히 이루어지지 않았다고 판단하였다.
2) Multi-Level Optimal Transport for Universal Cross-Tokenizer Knowledge Distillation + QFormer(Contrastive Loss) + CE
| 모델 | ASR | AAC |
|---|---|---|
| LLaMA-3.2-1B-Instruct | 11.24% | 0.2752 |
| LLaMA-3.2-1B-Instruct (distilled from LLaMA-3.2-3b-Instruct) | 11.4% | 0.2712 |
두 번째 시도에서는 KL divergence를 위한 차원 변환 과정에서 중요 정보가 누락되어 정확한 비교가 이루어지지 않았을 가능성을 고려하였다. 이를 방지하기 위해, 다양한 토크나이저 및 차원 차이가 존재하는 상황에서도 범용적으로 활용할 수 있도록, 여러 수준(예: 단어, 문장, 문맥 등)에서 OT 기반 정렬 방법론(Cui, X., 2024)과 Encoder 단에서 Contrastive Loss를 활용하여 AAC 성능을 향상시키는 방법론(Xu, X., 2024)을 조합하여 적용하였다. 최종적으로, 각 기법의 가중치는 별도로 설정하지 않고, 단순히 결과를 concat하여 CE(Cross-Entropy) 손실과 함께 활용하였다.
실험은 더 명확한 비교를 기대하여 LLaMA-3.2-1B-Instruct를 사용하였으며, 두 모델 다 Whisper-large-v2 + BEATs 조합으로 같은 데이터셋(version-1)으로 같은 훈련 조건 하에서 진행되었다. 다만 위에서 결과가 별로 좋지 않게 나오지 못한 이유 중 하나를 훈련 시간 부족이라고 가정했기에 이를 확인하기 위해서 Stage-1 만 2 epoch로 늘린 후 진행하였다. 결론적으로 같은 훈련 시간 후에 비교된 결과, distill된 모델이 베이스라인 모델에 비해서 하락하였다.
3) DDAT + QFormer(Contrastive Loss)
| 모델 | ASR | AAC |
|---|---|---|
| LLaMA-3.2-1B-Instruct | 11.24% | 0.2752 |
| LLaMA-3.2-1B-Instruct (distilled from vicuna-7b) | 14.81% | 0.1669 |
세 번째로, 두 번째 시도에서 사용한 다중 수준 OT 기반 정렬 방법론이 충분한 효과를 내지 못하자 KL divergence 방식으로 전환하였다. 그러나 첫 번째 시도처럼 Loss가 과도하게 폭증하는 문제를 방지하기 위해 고정 가중치를 사용하지 않고, 교사 모델의 예측 엔트로피를 활용해 데이터 난이도를 측정한 후 난이도에 따라 학습 가중치를 동적으로 조정하여 CE와 KL divergence의 결합 비율을 결정하는 방법(Zhang, Z. 2019)을 도입하였다. 여기에 추가로 Encoder Contrastive Loss를 결합하여 최종 Loss로 활용하였다.
실험은 더 명확한 비교를 기대하여 LLaMA-3.2-1B-Instruct를 사용하였으며, 두 모델 다 Whisper-large-v2 + BEATs 조합으로 같은 데이터셋(version-1)으로 같은 훈련 조건(Stage-1 2 epoch + Statge-2 1 epoch) 하에서 진행되었다. 해당 방법론으로 눈에 띄는 성능 향상은 볼 수 없었다.
4) DDAT + QFormer(MSE) + BEATs/Whisper(MSE)
| 모델 | ASR |
|---|---|
| LLaMA-3.2-1B-Instruct + Whisper-small | 18.6% |
| LLaMA-3.2-1B-Instruct + Whisper-small (distilled from LLaMA-3.2-3b-Instruct + Whisper-large-v2) with Stage-1 2 epoch | 22.67% |
| LLaMA-3.2-1B-Instruct + Whisper-small (distilled from LLaMA-3.2-3b-Instruct + Whisper-large-v2) with Stage-1 4 epoch | 21.12% |
네 번째로, 이전 실험에서는 모든 인코더를 동일하게 구성한 후, 단지 더 큰 파라미터의 LLM만을 변환하여 적용했지만, 그 결과는 기대에 미치지 못했다. 이에, 상대적으로 작은 인코더 모델이 더 큰 인코더 모델로부터 증류받을 때 성능이 더욱 크게 향상될 것이라는 가정 하에 추가 실험을 진행하였다.
LLM 증류 대신, 작은 인코더 모델이 더 큰 인코더 모델을 사용하는 선생 모델로부터 증류받은 모델과 그렇지 않은 모델을 비교 평가하는 인코더 중심의 지식 증류 방식을 실험으로 계획하였다. 이 실험에서는 QFormer의 output 중 last_hidden_state를 활용하였고, BEATs와 Whisper는 frozen 상태로 직접 가중치 업데이트는 이루어지지 않지만 Loss 계산 시 모델이 참고 지표로 삼을 수 있도록 포함되었다. 또한, 기존 방식과 달리 MSE를 활용한 Loss 계산 방식을 적용하였으며, DDAT에 속하는 KL divergence와 CE를 제외한 나머지 Loss들은 별도의 가중치 없이 단순히 concat하여 최종 Loss를 도출하였다.
실험은 동일한 데이터셋을 사용하여 Stage-1 학습으로 진행되었다. 베이스라인 모델은 Stage-1에서 2 epoch 학습된 모델을 기준으로 하였고, 비교를 위해 증류된 모델 역시 Stage-1 2 epoch 후의 체크포인트에서 측정되었다. 증류 방식의 특성상 증류되지 않은 모델보다 학습 수렴 속도가 상대적으로 느리다는 점을 고려하여, 수렴 CE Loss가 유사한 상태에서 비교하는 것이 적절하다고 판단하였다.
이에 따라, 학습률을 낮춘 추가 체크포인트를 기반으로 추가 2 epoch 학습하여 총 4 epoch 학습한 모델도 실험에 포함시켰으나, 2 epoch 학습된 모델과 마찬가지로 베이스라인 대비 성능 개선이 나타나지 않았다.
결론적으로, 위의 시도들에도 불구하고 눈에 띄는 성능 향상을 얻지 못하였다. 그 원인으로는, 동일한 학습 조건에서의 비교 대신 증류 시 다양한 Loss를 조합하여 사용함에 따라 학습 수렴 속도가 늦어졌고, CE 손실이 유사한 수준으로 수렴한 체크포인트를 기준으로 평가할 필요가 있었으나 이를 수행하지 못한 점(마지막 실험에서도 추가 학습 후 Loss가 0.9와 0.7로 현저한 차이를 보였으나, 제한된 리소스로 인해 추가 실험을 진행하지 못함)과, SALMONN과 같은 다중 통합 모델에서 효과적인 증류 방법을 찾지 못한 점 등이 주요 원인으로 작용한 것으로 판단된다.
4.1.6 LoRA 기반 타겟 모듈 변경
타겟 모듈 변경은 Transformer 아키텍처에서 특정 모듈의 중요성을 재조명하고 이를 최적화하여 성능을 개선하려는 접근법이다. 특히, Projection 계층의 조정은 정보 흐름의 효율성을 높이고, 모델 성능의 균형 잡힌 향상을 가져올 수 있음을 연구에서 시사하였다(Hu et al., 2021).
모델의 성능 향상을 위해 LoRA 기법(Hu et al., 2021)을 기반으로 타겟 모듈을 변경하는 실험을 진행하였다. 구체적으로, 기존 LoRA 설정에서 Gate Projection을 추가하여 선택된 모델 구성(CED-small, Whisper-large-v3-turbo, Qwen-0.5B)을 기준으로 그 효과를 분석하였다.
| 타겟 모듈 | ASR (WER) | AAC (SPIDEr) | TTFT (s) | TPOT (s) | Inference time(s) | Memory (GB) |
|---|---|---|---|---|---|---|
| q_proj, v_proj | 11.33% | 0.251 | 0.168 | 0.0344 | 0.2024 | 3.8272 |
| q_proj, v_proj, gate_proj | 9.14% | 0.2784 | 0.1725 | 0.0381 | 0.2106 | 3.8313 |
실험 결과, Gate Projection을 포함한 LoRA 설정은 두 작업 모두에서 균형 잡힌 성능 향상을 보였다. Gate Projection은 입력 정보의 흐름을 조절하여 어텐션 메커니즘뿐만 아니라 피드포워드 네트워크에서도 효과적으로 작동하였으며, 이를 통해 모델의 정보 전달 및 변환 과정이 최적화되었다.
반면, 일부 모듈(k_proj, o_proj, up_proj 등)은 연산량 증가나 성능 기여도가 낮은 것으로 판단되어 고려 대상에서 제외되었다. 특히, up_proj와 o_proj는 입력 차원을 증가시켜 모델의 계산량과 메모리 사용량을 크게 증가시킬 가능성이 있어 최적의 선택이 아니었다.
결과적으로, Gate Projection은 성능 향상과 효율성(추론 시간 및 메모리 사용량) 간의 균형을 고려했을 때 최적의 선택으로 판단되었으며, 이를 최종 모델 구성에 반영하였다.
4.2 Data Centric
대규모 오디오 데이터셋(161만 7,013개 샘플) 분석 결과, 평균 길이 12.17초의 오디오 파일이 FLAC(40.4%)과 WAV(59.6%) 형식으로 구성되었다. 모든 샘플은 16kHz 샘플링 레이트로 통일되었으며, 대부분 모노(97%) 채널이다. 또한 메타데이터 분석 결과 전체 데이터셋의 오디오 길이 분포가 0초부터 1,069초까지 있었으나, 상당수가 1분 이내로 밀집되어 있었다.
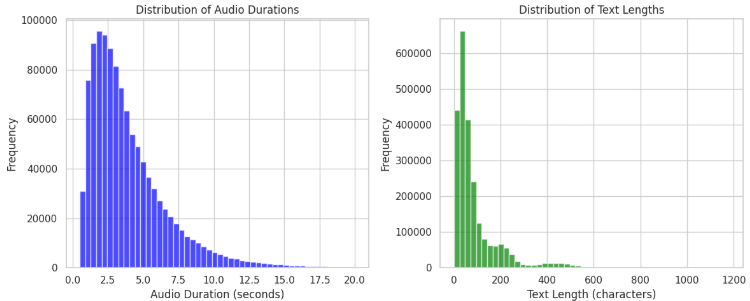
이러한 초기 분석을 바탕으로, 데이터 전처리 및 샘플링 전략의 필요성이 대두된 바, 총 세가지 측면에 중점을 두어 데이터 샘플링을 진행하였다.
먼저 SALMONN에서 적용한 stage-1, stage-2의 구분을 지켜 각각의 stage에서 따로 데이터셋을 추출하였다. 이는 stage-1의 task가 stage-2의 task보다 단조롭고 난이도 낮은 바,
Curriculum Learning 방식을 적용하여 모델이 보다 원활하게 학습할 수 있도록 하기 위함이었다.
다음으로, 원본 데이터셋은 그 오디오 길이 분포 자체가 0초부터 1,069초까지 있는 등 상당히 불균등 하였기에 이에 대하여 오디오 길이 기준 상,하위 5%에 대하여 이상치로 판단하여 제거를 진행하였으며, 이후 task별로 나누어 text 길이 분포 기준 10분위로 나누어 각각의 분위에서 균등하게 데이터셋을 추출하였다.
마지막으로 언어모델이 가지는 고질적 문제인 Catastrophic Forgetting을 완화하기 위하여 stage-1의 데이터와 stage-2의 데이터를 완전 분리하는 것이 아닌, stage-1의 데이터를 stage-2로 일정 부분 포함시켰다. 이는 과거 학습 내용을 현재 학습에서 어느정도 복기하여 모델로 하여금 이전 학습 내용을 잊지 않도록 하기 위함이었다.
위와 같이 데이터셋을 구성하였을 때 동일 모델 기준 단순 랜덤 샘플링으로 진행한 결과 보다 WER이 1.6% 감소하고, AAC가 0.1286 증가하였다.
| 평가지표 | Random Dataset | Custom Dataset | 비고 |
|---|---|---|---|
| WER | 9.64% | 8.04% | 1.6% 감소 |
| SPIDEr | 0.2125 | 0.3411 | 0.1286 증가 |
4.3 최적화
4.3.1. Flash Attention(v1,v2, v3)
Flash Attention은 GPU 메모리 효율성을 극대화한 최적화된 기법으로, 메모리 복잡도를 O(N²)에서 O(N)로 줄인다. 또한 전용 체크포인팅과 CUDA 커널 최적화를 활용하여 긴 시퀀스 처리에서 속도를 향상시키고, GPU 메모리 사용량을 줄인다.
본 프로젝트의 최종 제출물을 Qwen 2.5 0.5B를 사용하기 때문에 큰 모델보다 성능 향상 폭이 적지만 실험을 통해 정확한 Trade-off를 측정하였다.
본 서버 V100에서는 CUDA 버전 문제로 Flash Attention V2를 구동할 수 없어 RTX 4090에서 실험하였다. 동일 모델을 조건으로 evaluate_efficiency_salmonn.py를 3회 구동한 평균을 낸 결과이다.
| 적용 기법 | TTFT | TPOT | Inference Time |
|---|---|---|---|
| None | 0.1113 | 0.0231 | 0.1344 |
| flash attention 2 | 0.1166 | 0.0234 | 0.1399 |
| SDPA | 0.1110 | 0.0229 | 0.1339 |
Flash Attention은 메모리 효율적인 어텐션 연산을 제공하여, 대규모 모델에서의 성능을 향상시킨다. 또한 torch 2.2버전 부터 SDPA 연산에 flash attention v2가 기본으로 탑재되었다. 이에 따라 Flash Attention v2는 이를 적용하지 않는 것 대비 더 빠른 계산 속도와 향상된 메모리 관리를 제공하여 높은 효율성을 보였다.
추가로 Paged Attention은 vLLM을 활용한 메모리 최적화 기법이지만, 모델 크기가 상대적으로 작아 이점이 크지 않았다. 이 기법은 대규모 시퀀스에 대한 동적 페이징 기법을 적용하여 메모리를 절감하지만 ,소규모 모델에서는 어텐션 메모리 사용량 자체가 작아 효과가 크지 않았다.
실험 결과 SDPA가 가장 좋은 성능을 내는 것을 볼 수 있다. 실제 실행 환경이 H100 GPU인 것을 가정한다면, Flash Attention이 IO 최적화를 위해 L2 Cache와 고-메모리 대역폭을 필요로 한다. 이 때 H100 L2 Cache는 적지만, 메모리 대역폭이 3배가 되기 때문에 최종적으로 SDPA를 사용하는 flash attention 2를 선택하였다.
4.3.2. LoRA, QLoRA, DoRA
LoRA는 모델의 일부 가중치만 업데이트하는 방식으로, 적은 연산량으로도 효과적인 미세 조정을 가능하게 한다. 이 때 연산 속도를 향상하거나 VRAM 향상을 위한 다양한 파생 기법을 적용해 보았다.
QLoRA는 4비트 양자화를 적용하여 메모리를 절약하지만, 성능 저하와 가중치 업데이트의 제약이 있었다. 실험 결과, LoRA가 성능 유지와 연산 속도의 균형이 가장 우수한 것으로 나타났다. DoRA는 LoRA의 확장형으로, 더 다양한 방향의 가중치를 학습할 수 있지만 추가적인 계산 비용이 발생한다.
실험 결과는 아래와 같다. 이 때 DoRA의 경우, 직접 학습하지 않았고 논문을 기준으로 점수 상승 폭이 0.6~1.8% 차이임을 인용하여, 실제 ASR, AAC 점수도 이에 대비하여 Trade-off를 측정하였다.
| 적용 기법 | TTFT | TPOT | Inference Time | VRAM(GB) |
|---|---|---|---|---|
| LoRA | 0.1141 | 0.0243 | 0.1384 | 3.831 |
| QLoRA | 0.1109 | 0.0216 | 0.1325 | 4.741 |
| DoRA | 0.1297 | 0.0405 | 0.1703 | 3.831 |
우선 QLoRA의 경우 VRAM을 0.9GB 정도 상승시키고 Inference 속도 5%정도 향상시켰다. 또한 DoRA의 경우 ASR 점수 향상이 -0.1~0.1%로 매우 적으로, 이에 대비되어 Latency가 5% 올라가는 Trade-off가 더 높다고 판단하여, DoRA는 사용하지 않기로 결정하였다.
결론적으로 본 프로젝트의 모델 특징이 굉장히 경량화 되어 최적화에 있어서 Trade-off가 더 큰 것에 있다. 이에 따라 기본 LoRA는 낮은 연산 비용으로도 충분한 성능 향상이 가능하며, DoRA나 QLoRA 대비 최적의 균형을 제공하기 때문에 최종 선정하였다.
5. 결과
Speech Encoder와 Non-Speech Encoder에는 각각 openai/Whisper-large-v3-turbo와 CED-small을 적용 하였으며, LLM은 Qwen/Qwen2.5-0.5B-Instruct를 적용하였다.
최종 결과는 아래와 같다.
| 타겟 모듈 | ASR (WER) | AAC (SPIDEr) | TTFT (s) | TPOT (s) | Inference time(s) | Memory (GB) |
|---|---|---|---|---|---|---|
| q_proj, v_proj, gate_proj | 6.99% | 0.3615 | 0.168 | 0.0344 | 0.2102 | 3.8313 |
6. Reference
- Dinkel, H., Wang, Y., Yan, Z., Zhang, J., & Wang, Y. (2023). CED: Consistent Ensemble Distillation for Audio Tagging. arXiv preprint arXiv:2308.11957.
- Liu, J., Li, G., Zhang, J., Dinkel, H., Wang, Y., Yan, Z., Wang, Y., & Wang, B. (2024). Enhancing Automated Audio Captioning via Large Language Models with Optimized Audio Encoding. arXiv preprint arXiv:2406.13275v2.
- https://github.com/RicherMans/CED/tree/main?tab=readme-ov-file
- Cui, X., Zhu, M., Qin, Y., Xie, L., Zhou, W., & Li, H. (2024). Multi-Level Optimal Transport for Universal Cross-Tokenizer Knowledge Distillation on Language Models. arXiv preprint arXiv:2412.14528.
- Xu, X., Liu, H., Wu, M., Wang, W., & Plumbley, M. D. (2024). Efficient Audio Captioning with Encoder-Level Knowledge Distillation. arXiv preprint arXiv:2407.14329.
- Puvvada, K. C., Żelasko, P., Huang, H., Hrinchuk, O., Koluguri, N. R., Dhawan, K., ... & Ginsburg, B. (2024). Less is more: Accurate speech recognition & translation without web-scale data. arXiv preprint arXiv:2406.19674.
- Dao, T., Fu, D., Ermon, S., Rudra, A., & Ré, C. (2022). Flashattention: Fast and memory-efficient exact attention with io-awareness. Advances in Neural Information Processing Systems, 35, 16344-16359.
- Zhang, Z., Han, J., Coutinho, E., & Schuller, B. (2019). Dynamic Difficulty Awareness Training for Continuous Emotion Prediction. IEEE Transactions on Multimedia, 21(5), 1289–1301.
- Hu, Edward J., Shen, Yelong, Wallis, Patrick, Allen-Zhu, Zeyuan, Li, Yuanzhi, Wang, Saining, Wang, Lu, and Chen, Weizhu. 2021. "LoRA: Low-Rank Adaptation of Large Language Models." arXiv preprint arXiv:2106.09685. https://arxiv.org/abs/2106.09685.
팀회고
Instruction tuning 미흡
현재 적용된 instruction은 NOTA 측에서 제공한 기본 base line의 instruction인데, 보다 좋은 instruction을 줄 수 있었다면 어땠을까 싶은 아쉬움이 남음.
QFormer와 BEATs를 제외한 모델 구조에 대한 실험
SALMONN의 구조를 벗어난 코드를 구현했다면 canary의 적용도 가능했을 것이기에 아쉬움, 더 좋은 모델들이 새로 나온 만큼 구조를 바꿔서 실험했다면 그에 따라 더 좋은 결과도 있었으리라 생각함
지식 증류 적용 실패
한정된 학습 리소스로 인하여 증류 결과를 확인할 만큼의 학습을 진행하지 못했음. SALMONN과 같은 다중 통합 모델에서 효과적인 증류 방법을 찾지 못한 점이 주요 원인으로 작용한 것 같음
실험 변수 관리 미비
프로젝트 초반부에는 아키텍처 내 모듈 변수들을 나름 잘 관리하여 A/B Test를 통해 결과값에 영향을 주는 원인을 나름 명확히 분석할 수 있었으나, 후반부로 갈수록 변수 통제가 원활히 이루어지지 않아 재실험을 하게 되는 경우가 많았다.
개인회고
이번 파이널 프로젝트를 통해 처음 팀장을 맡게 되었고, 그 덕분에 GitHub을 더 많이 활용하게 되었다. NOTA에서 기제공한 코드가 많았지만, 덕분에 처음으로 베이스라인 코드도 작성해보았으며, 브랜치 생성 및 병합, Issue와 Discussion 해결 등 다양한 GitHub 활동을 통하여 어느 때보다도 많은 commit을 하게 되었다.
지나고보니 특히 팀원들에게 감사한 마음이 크다. 팀에 훨씬 나보다 잘하는 팀원이 많아 부족한 면면이 많이 보였을텐데 많은 상황속에서 기다리고 참아준 덕분에 프로젝트를 잘 마칠 수 있었던 것 같다. 이 자리를 빌어 진심으로 감사의 마음을 전하며 비록 부스트 캠프를 마치며 팀활동은 이것이 마지막이지만 언젠가 일터에서 만났을 때에 더 좋은 사람, 더 능력 있는 사람이 되어 내가 받은 존중을 꼭 돌려주고 싶다.
이번 프로젝트 주제는 “오디오 언어 모델의 경량화”였고, 그 안에서도 “멀티 모달”과 “경량화” 두가지는 핵심적인 개념이었다. 개인적으로는 그 두가지 모두 심도있게 탐구하기는 이번이 처음이었는데, AI 엔지니어로서 필수적인 역량을 기를 수 있어 매우 의미 있는 경험이었다.
특히, Q-former의 역할과 구체적인 코드를 살펴보면서 서로 다른 성질의 임베딩이 서로를 향해 교차 가능함을 확인한 점이 매우 인상깊었는데, 이는 추후에 개인적인 프로젝트에서도 사용할 수 있겠다는 생각이 들었다.
기여한 점
팀장으로서 베이스라인 코드를 올린 후, 지속적으로 코드 리팩토링을 실시하고 논의된 Issue와 Discussion을 해결하였다. 자잘한 경로문제와 학습 진행코드 전반을 보강하며 브랜치 통합을 진행했으며, 실험 및 서버 관리에 있어서 Notion API를 활용하여 서버 디스크 사용량과 GPU 사용량을 실시간으로 모니터링하고 이를 관리 페이지에 반영하여 프로젝트 진행의 편의성을 높혔다.
Data EDA 및 최종 구성에도 기여하였다. Curriculum Learning 방식을 유지하면서 Catastrophic Forgetting을 방지하기 위해 stage-1 학습 데이터를 stage-2 학습 데이터에 일부 포함시켰으며 불균등 데이터셋을 균등하게 조정하여 최종 학습 데이터를 구성하였다.
아쉬운 점
peft config를 레이어마다 다르게 구성하여 rank와 alpha 값을 개별적으로 적용하고, Unsloth 라이브러리를 사용해 Memory Use를 감소 시켰지만, inference time과 실제 성능 간 trade-off를 고려하여 해당 방법론은 적용하지 못했다. 또한, Pruning과 관련하여 taylor 1st-order importance를 이용하여 레이어별 중요도를 파악하고 불필요 레이어를 제거하려 하였지만, 프로젝트 후반부에서는 0.5B 모델을 사용하게 되어 개별 레이어의 중요성이 커져 이 방법을 적용하지 않게 되었다. 물론 실제 적용하였더라도 기존 Llama3.2-3B 모델을 통한 실험 결과에서 27개 레이어에서 5개 레이어를 제거한 결과 inference time이 10% 향상한 반면 ASR과 AAC 성능이 각각 최소 10% 이상 하락 한 점으로 미루어 보아 Pruning 이라는 방법론은 정말 최소한의 모델이 존재하지 않는 경우에 사용하는 것이 맞겠다는 생각이 든다.
나아갈 방향
적용 된 부분도, 적용되지 못한 부분도 있지만 본 프로젝트를 통해서 단순히 성능만 좋다고해서 실제 사용할 수 있는 것은 아니라는 점을 배운 바, 이후 프로젝트에서는 실제 사용 가능한 모델과 이를 쉽게 inference 할 수 있도록 배포까지 하는 하나의 사이클을 완성해 봐야겠다고 생각했다. 특히 이번 프로젝트에서 시도한 가지치기와 지식증류에 대해 개별 프로젝트를 통해 자유로이 활용할 수 있도록 익혀두어야 겠다.
