MRC(RAG) 프로젝트 Wrap-up report
1. 프로젝트 개요
- 주제 : Open-Domain Question Answering
- 사전에 구축되어있는 Knowledge resource(Wikipedia 데이터셋)에서
① 질문에 대답할 수 있는 알맞은 문서를 Retriever를 활용하여 추출하고
② Reader를 통해 추출한 문서에서 정답을 찾거나 생성하는
Retriever-Reader two-stage 모델을 구현하는 프로젝트 - 평가 지표로 EM, 참고용 지표로 F1 Score를 사용
- EM(Exact Match): 모델이 예측한 값과 실제 답이 정확히 일치한 비율
- 단, 두 값을 모두 정규화한 후에 일치하는지 확인하며 (ex. 띄어쓰기, 문장부호 등)
- 답이 여러 개인 경우도 있고, 그 경우 정답 중 하나만 일치해도 정답으로 간주 - F1 Score: 정밀도(Precision)와 재현율(Recall)의 조화평균
- EM과 다르게 예측값이 답과 어느정도 겹치는 부분이 있다면 부분점수를 받을 수 있음
- 그러나 리더보드 등수에는 EM만 반영되며, F1 Score는 참고를 위한 지표로만 사용됨
- 데이터 구성
| 분류 | 샘플 수 | 용도 | 공개여부 |
|---|---|---|---|
| Wikipedia | 57k | Retriever 학습용 | 모든 정보 공개(text, corpus_source, url, domain, title, author, html, document_id) |
| Train | 3952 | Reader 학습용 | 모든 정보 공개(id, question, context, answers, document_id, title) |
| Validation | 240 | ||
| Test | 240 (Public) | 제출용 | id, question만 공개 |
| 360 (Private) |
- 개발 환경
| 개발 환경 | 서버 | AI Stages GPU (Tesla V100-SXM2) * 4EA |
|---|---|---|
| 기술 스택 | Python, Transformers, PyTorch, Pandas, WandB, Hugging Face, Matplotlib | |
| 운영체제 | Linux | |
| 협업도구 | Github | 코드 공유 및 버전 관리, Issue로 진행 중인 Task 공유 |
| Notion | 회의 내용 공유, 프로젝트 일정 관리, 실험 기록 | |
| Slack | Github 및 WandB 봇을 활용한 협업, 의견 공유, 회의 | |
| Zoom | 실시간 소통을 통한 의견 공유 및 회의 |
2. 팀 구성 및 역할
| 팀원 | 역할 |
|---|---|
| 박준성 | 협업 관리(이슈/PR 템플릿 추가), 코드 리팩토링(베이스라인 코드 재작성, Config 클래스), EDA 서버 개설 및 관리(Page 시스템, 훈련용 데이터셋 EDA 페이지), Cross Encoder 구현, Retrieval 성능 측정 EDA(TF-IDF, BM25), 앙상블 구현(soft voting), 모델 파이프라인 병합(Retriever-Reader 연결), 데이터 증강(KorQuad) |
| 이재백 | Dense Retriever 구현, Negative Sampling 구현(In-batch, random, Hard negative sampling), 모델 조사 및 실험 |
| 강신욱 | 모델 탐색 및 실험, 기능 향상 시도( 가중치를 활용한 sparse와 dense 리트리버 결합, GPT를 활용한 dense retrieval의 네거티브 샘플링 생성) |
| 홍성균 | Sparse Retrieval 구현(BM25), 코드 리팩토링(main.py 병합, CPU병렬처리, Reader/Retrieval Tokenizer 분리 적용), EDA서버 증축(DataEDA, TokenizerEDA), 실험 편의성 개선(WandB 적용), Bug Fix(하이퍼 파라미터 미적용 수정, Argumentparser 미적용 수정), 데이터 증강(KorQuAD와의 병합) |
| 백승우 | Generation-based Reader 모델 구현,PEFT(Parameter Efficient Fine-Tuning) 기법 중 LoRA(Low-Rank Adaptation) 구현, Generation-based 모델 조사 및 실험 |
| 김정석 | 한자 등 각 유니코드 블록에 해당하는 문자를 제거하는 전처리 함수 작성 및 EDA |
3. 프로젝트 파일 구조
project/
│
├── notebooks/ # EDA 결과, 임시 코드를 위한 Jupyter 노트북 디렉토리
│ └── (EDA 결과 또는 임시 코드) # 실제 노트북 파일들
│
├── src/ # 소스 코드의 메인 디렉토리
│ ├── QuestionAnswering/ # 질문 답변 관련 모듈 디렉토리
│ │ ├── tokenizer_wrapper.py # 토크나이저 래퍼 클래스/함수
│ │ ├── trainer.py # 모델 훈련 관련 클래스/함수
│ │ └── utils.py # QA 관련 유틸리티 함수
│ │
│ ├── Retrieval/ # 검색 관련 모듈 디렉토리
│ │ ├── cross_encoder.py # Cross-encoder 모델 관련 코드
│ │ ├── dense_retrieval.py # 밀집 검색 관련 코드
│ │ ├── sparse_retrieval.py # 희소 검색 관련 코드
│ │ ├── hybrid_retrieval.py # 하이브리드 검색 관련 코드
│ │ ├── NegativeSampler.py # 일반 네거티브 샘플링 클래스
│ │ └── SparseNegativeSampler.py # 희소 검색 기반 네거티브 샘플링 클래스
│ │
│ ├── server/ # Streamlit 서버 관련 코드 디렉토리
│ │ ├── page/ # 페이지 구현 클래스 디렉토리
│ │ │ ├── DataEDA.py # 데이터 EDA 페이지 구현
│ │ │ ├── HomePage.py # 홈페이지 구현
│ │ │ ├── TokenizerEDA.py # 토크나이저 분석 페이지 구현
│ │ │ └── trainingDatasetQA.py # QA 데이터셋 분석 페이지 구현
│ │ │
│ │ └── utils/ # 서버 유틸리티 디렉토리
│ │ ├── data_loader.py # 데이터 로딩 관련 함수
│ │ └── Page.py # 페이지 관리 클래스
│ │
│ ├── config.py # 설정 파일 로드 및 파싱
│ ├── index.py # Streamlit 앱의 메인 엔트리 포인트
│ ├── main.py # 전체 모델 훈련 및 검증 관리
│ └── preprocess.py # 텍스트 전처리 함수
│
├── config.yaml # 기본 모델 및 데이터 경로 설정
└── dense_encoder_config.yaml # Dense Encoder 모델 설정4. 프로젝트 수행 절차 및 방법
4.1 그라운드 룰
4.1.1 팀 Notion에 있는 서버 현황판 활용하기

4.1.2 Git 관련
- Github Issue 활용하여 수행 중인 작업 공유하기
- commit convention 사용
- branch naming convention
`{name}-issue-{issue 번호}`로 브랜치의 이름을 정해 브랜치별로 작업 중인 팀원과 작업 내용을 공유
4.1.3 소통 관련
- 상호 존중
- 한 작업에 복수 인력이 투입될 때 따로 모여서 실시간으로 대화하며 협업하기
- 일일 제출 횟수 제한을 감안하여 슬랙/줌에서 회의 후 최종 결과물 제출
- 데일리 스크럼/피어 세션 때 남아 있는 Issue & PR 처리하기
4.2 전체 프로젝트 수행 과정 및 상세 설명
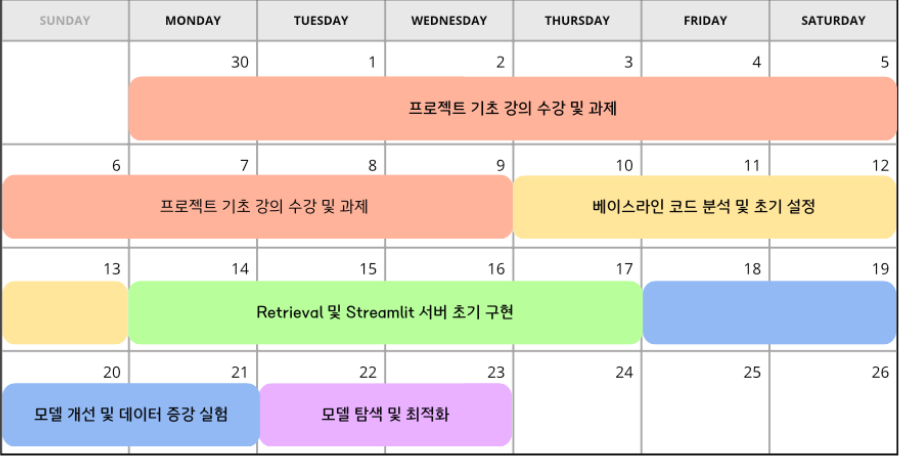
4.2.1 프로젝트 기초 강의 수강
- 기간 : 09/30 ~ 10/09
- 내용
- Embedding 관련 기본개념 정립 및 기계독해 프로세스와 그에 사용되는 데이터셋에 대한 이해
- Extraction/Generation Based MRC 구현 및 Base 모델 설명(BERT, T5)
- Retrieval 관련 Sparse, Dense 장점과 단점 분석
- FAISS를 활용한 문서검색 프로세스 이해
4.2.2 베이스라인 코드 분석 및 초기 설정
- 기간 : 10/10 ~ 10/11
- 내용 :
- 피어세션 전까지 baseline 코드 이해 및 해설 준비
- 코드 분석 방안 논의 (각자 분담 vs 전체 파일 분석)

4.2.3 Retrieval 및 Streamlit 서버 초기 구현
- 기간 : 10/14 ~ 10/17
- 내용
- Streamlit 서버 구현 및 대시보드 개발 시작
- BM25 구현 완료 및 테스트 정상 작동
- Dense Retrieval의 성능 저조 현상 확인, Random Negative Sampling의 문제 발견
- Sparse Retrieval을 통한 Hard Negative Sampling 구현
- Hybrid Retrieval 초기 설계 (Sparse + Dense)
- Generation-based MRC 구현 완료 (mt5 모델)
- UNK 토큰 처리 및 데이터 전처리 시작
- 데이터 EDA
4.2.4 모델 개선 및 데이터 증강 실험
- 기간 : 10/18 ~ 10/21
- 내용
- Generation-based MRC 성능 개선 (t5-based 모델 및 KorQuAD 데이터셋 fine-tuning)
- Dense 및 Sparse Retrieval 성능 비교 실험
- BM25와 Cross-Encoder 비교 및 Hybrid Retrieval 실험 진행
- WandB 연동 및 대시보드 시각화 기능 개발
- 전처리 함수 보완 (특수문자 및 UNK 토큰 처리)
- KorQuAD v1 활용하여 데이터셋 증강
4.2.5 모델 탐색 및 최적화
- 기간 : 10/22 ~ 10/23
- 내용
- DeBERTa, RoBERTa 모델 탐색 및 실험
- Large model 활용을 위해 LoRA 적용 및 코드 수정
- Retrieval 모델 성능 개선 및 Negative Sampling 적용
- Hybrid Retrieval의 최종 구현 및 실험 진행
- 앙상블을 활용한 모델 성능 향상
5. 프로젝트 결과
| 분류 | 순위 | EM | F1 |
|---|---|---|---|
| private (최종 순위) | 5🥉 | 67.22 | 77.88 |
| public (중간 순위) | 12 | 64.17 | 74.89 |
6. 자체 평가: 팀 회고
6.1 프로젝트 개괄
6.1.1 협업 툴
-
Notion
- Notion을 활용하여 실험 진행 현황과 서버 사용 현황, 프로젝트 일정 정리 및 실험 기록 정리를 효과적으로 할 수 있었다. 다만 프로젝트 후반부로 갈수록 복잡해지는 실험의 구성 탓에 제대로 기록을 해두지 못해 아쉬웠다.
-
Git
- branch name과 commit message의 convention을 정하고 issue 기능을 적극적으로 활용해 각자 무슨 일을 하고있는지 서로가 알기 쉽게 할 수 있어 좋았다. Release 기능을 활용해 버전 관리도 시도해보았다. 하지만 각자 자유롭게 issue를 업데이트하고 기능을 추가하는 워크플로우로 프로젝트를 진행했기에 세부적인 버전 관리는 쉽지 않았다.
-
Zoom
- 매일 모여 데일리 스크럼(10:00 am~)부터 피어세션(~17:00 pm)까지 줌에 접속해 원활한 소통이 가능했다.
6.1.2 파일 구조
-
초기버전과 이후 변화양상
- 초기에는 config.yaml 제외 모든 파일을 src폴더에 넣은 후 해당 폴더에서 Retrieval 과 QuestionAnswering 폴더로 다시 구분하여 관리하였다.
- 이후 버전 업그레이드 및 EDA server가 추가됨에 따라 src 폴더에 server 폴더를 추가 개설하였으며, inference.py와 train.py를 통합하여 main.py를 구축하고 Retrieval 관련하여서는 추가되는 Densce Embedding, Cross-Encoder 등은 해당 폴더에 넣어 관리하였다.
-
개선할 점
- 더욱 객체지향적이게 파일구조를 관리했으면 어땠을까 생각한다. train.py와 inference.py를 통합하여
관리하기 편하게 만들려고 했던 초기 취지의 main.py가 프로젝트를 진행하며 각종 기능들이 추가되며 상당히 긴 코드가 되었는데, 이점이 조금 아쉽다. - 또한 Retrieval, QuestionAnswering 폴더 관련하여서도 소프트웨어 설계의 기본 원칙인 \<모듈성>, \<응집도>, \<결합도>를 고려하여 좀 더 클래스들을 객체지향적으로 관리하였으면 좋았을 것 같다. 추가된 기능들에 비해서 파일 세분화정도가 낮은 편이기에 후반에 가서 코드를 수정하고 Git에 PR날리는 것이 Merge하는 데 부담이 되어 그냥 각자 수정하는 경우도 많았었다.
- 더욱 객체지향적이게 파일구조를 관리했으면 어땠을까 생각한다. train.py와 inference.py를 통합하여
6.1.3 버전관리
-
목적
- 이전 STS 프로젝트에서 기능들의 추가 과정을 빠르게 TraceBack 할 수 있도록 버전 관리를 통해 프로젝트를 보다 체계적으로 관리하자는 피드백이 있었고, 본 프로젝트에서 해당 피드백을 수용하여 GitHub의 Release Tag를 활용하여 버전을 관리하게 되었다.
- 사용한 결과 파일구조의 변경이 있는 경우 또는 기능의 추가/제거가 있을 때에 보다 편리하게 해당 프로젝트의 버전을 관리하고 체계화 할 수 있어서 좋았으며, 특히 GitHub가 관련한 PR과 이슈들을 자동으로 기록, 통합해줘서 해당 버전의 ReadMe에 반영할 수 있어 좋았다.
-
개선할 점
- 버전관리의 초기 목적은 나름 달성한 것 같으나, 본 프로젝트에서 사실 기능추가와 실험성능 측정 등에 밀려
버전 관리를 더 자주 활용하지 못했다. 초기 버전을 1.0.0 으로 두고 시작한 데에 비해 사실은 맨 앞자리 수에 변동을 줬을 뿐 프로젝트의 버전들을 세세하게 관리하지 못했고 굵직한 변화만 따라가기 바빴다. 그리고 버전 Tag를 달 때에 팀 논의를 통하여 변동된 코드들을 정확히 짚고 전체가 인지한 상태로 이후 프로젝트를 진행했다면 보다 더 좋은 프로젝트 관리가 되지 않았을까 싶다.
- 버전관리의 초기 목적은 나름 달성한 것 같으나, 본 프로젝트에서 사실 기능추가와 실험성능 측정 등에 밀려
6.2 데이터 EDA
6.2.1 Streamlit 서버를 활용하여 EDA 결과 배포
- train 데이터셋이 이전 프로젝트와 다르게 pyarrow라는 이진파일로 주어졌기 때문에, 어떤 데이터가 있는지 확인하려면 코드를 작성해야 한다는 부담과 피로가 존재했다.
- 따라서 팀원 모두가 용이하게 훈련용 데이터셋을 확인해볼 수 있도록 주어진 GPU 서버에 streamlit 서버를 띄워 개인의 로컬 환경에서도 EDA를 진행할 수 있도록 하고자 하였다.
- 확장성을 위해 streamlit에 띄어지는 페이지를 하나의 객체라고 생각하여,
Pages/폴더 아래에 띄우고 싶은 페이지 클래스를 모아놓으면 자동으로 import하여 페이지 계층 구조를 만들고 sidebar를 이용하여 다른 페이지로 이동할 수 있도록 하였다. - 결과적으로 train 데이터셋을 쉽게 확인하기 위해, train 데이터셋의 질문과 Context 전문을 보여주는 페이지를 만들었다. 추가적으로 질문에 따른 정답을 확인하기 위해 버튼을 누르면 Context에서 정답에 해당하는 부분을 강조하는 기능과 현재 설정된 tokenizer를 사용할 때 어떤 부분이 UNK 토큰인지 강조하는 기능을 추가하였다.
6.2.3 데이터 증강 및 전처리
-
Stream 서버를 활용하여 Context의 어느 부분이 주로 UNK 토큰이 되는지 확인해보았고, 그 결과 한국어가 아닌 다른 국가의 언어(특히, 한자), \n과 같은 이스케이프 문자, 한글로 적혀있는 외국어(ex. 이름: 퓌헤레노르) 등이 UNK 토큰으로 식별하고 있다는 걸 알 수 있었다.
-
따라서 한자와 같은 문자를 Context에서 제거하는 전처리를 시도하려고 하였으나, test dataset의 예측 결과에 “박준성(朴俊性)”과 같이 한자를 함께 정답으로 인식하는 케이스도 발견하여 최종 예측에 노이즈가 섞이게 될 수도 있다고 판단하에 실행하지 않았다.
-
한편 기존에 제공된 Trian Dataset 외에 KorQuAD를 활용하여 데이터셋을 증강하였다. 그리고 해당 증강된 데이터에 대하여 특수문자 및 연속 공백 등을 제거하는 등의 전처리를 진행하였으나, 해당 전처리 결과의 효과는 미미하여 본 프로젝트 최종에는 반영하지 않았다.
6.3 기능 개발 상세
6.3.1 Retrieval
-
Sparse Embedding
- 기존 Base-Line 상에 설정되어 있었던 TF-IDF 대신 BM25를 적용하였다. 왜냐하면 TF-IDF의 경우에는 구조가 단순하여 빠르게 계산이 가능하다는 장점이 있었지만, 문서 길이와 같은 요소가 고려되지 않아 보다 정확한 Embedding이 불가능했기 때문이다.
- 구체적으로 rank_bm25 라이브러리를 활용하여 SparseRetrieval.py 코드 내부에 추가하였고, Top_k의 적용을 받게 하여 bm25.get_scores를 통하여 추출된 doc_scores와 doc_indices를 Reader에 넘겨주었고 해당 bm25_emebdding 데이터에 관해 피클로 관리하여 이미 계산된 적 있는 값이라면 언제든 불러올 수 있도록 편의성도 고려하였다.
-
Dense Embedding
- Query Encoder와 Passage Encoder의 Bi-Encoder 모델을 기반으로 Dense Retriever를 구현했다.
- Query 의 CLS 토큰과 Passage Encoder를 통해 구축한 Knowledge resource(Wikipedia 데이터셋)의 Passage Embedding간의 내적을 통해 높은 내적값을 갖는 문서를 불러오도록 하였다.
- 학습 시에는 관련 없는 Passage와의 내적값을 줄이기 위해 Negative Sampling을 진행하였는데, 초기에는 Random Sampling을 활용해 Negative Sampling을 진행하였다. 하지만 훈련시 Loss값이 0에 가까운 값들을 얻게 되고, 실제 Retrieval 성능은 높지 않은 결과를 얻게되어 Random Sampling으로는 적절한 학습이 되고 있지 않다는 결론을 얻게 되었다.
- 따라서 미리 구현된 Sparse Retriever를 활용해 연관이 있어보이지만 사실은 무관한 Passage들을 불러오는 Hard Negative Sampling 방식으로 개선하였고 성능의 향상을 얻을 수 있었다.
- 다만 BM25 알고리즘을 활용한 Sparse Retriever와 그를 기반으로 한 Cross Encoder의 높은 성능으로 인해 최종 모델 구축에는 채택하지 않았다.
-
Cross Encoder
- Dense Embedding 방식은 Query와 Passage 사이의 어텐션 값이 계산되지 않으므로, [CLS] Context [SEP] Question [SEP]과 같은 형식으로 입력을 넣어 Positive Sample이라면 [CLS]의 값이 1에 가까워지도록, Negative Sample이라면 0에 가까워지도록 학습하면 Query와 Passage 사이의 어텐션 값이 계산되어 예측에 도움되리라 생각하여 Cross Encoder 방식의 Reranker 방식을 시도해보고자 했다.
- 학습은 Dense Embedding과 마찬가지로 BM25로 추출된 Hard Negative Sample을 이용하였다. 추론시에도 BM25를 이용하여 질문과 비슷한 Context을 일정 개수(=25개)만큼 고른 후, 질문과 각 Context를 함께 Cross Encoder에 넣어 그 중 점수가 가장 높은 top-k(=5)개의 Context를 반환하는 식으로 구현했다.
- Recall@5가 약 90% 정도로 BM25의 Recall@5가 약 82% 정도인 것에 비해 큰 성능 향상을 얻을 수 있었다.
- 다만 Cross Encoder가 모든 문서에 대한 유사도 랭킹을 직접 평가할 수 없고 BM25로 먼저 한 번 필터링한 문서에 대한 유사도 랭킹을 구하는 것이므로, 결국 Cross Encoder의 고점은 Sparse Embedding인 BM25과 같다는 점에서 아쉬웠다. 또한 BM25의 inference 시간이 1분도 걸리지 않는 것에 비해 Cross Encoder는 3~5분 정도 걸리는 것 또한 개선할 여지가 있다고 생각한다.
6.3.2 Reader
-
Extraction-Based Reader
- 입력 Query를 받아 주어진 Passage에서 정답 Span을 찾도록 한 모델. 베이스라인 코드의 모델을 큰 수정 없이 사용하였다. 팀원간 역할의 구분 없이 자유롭게 모델을 구현하고 개선하였기 때문에 너무 Data EDA와 Retriever 모델의 개선에만 집중해 Reader 모델의 구현과 개선에는 관심을 갖지 못해 아쉬웠다.
-
Generation-Based Reader
- Encoder-Decoder 구조를 갖추고, Text-to-Text 형식으로 사전 학습된 생성형 언어모델을 기반으로 Generation-based Reader 모델을 구현했다. 이 모델은 입력으로 질문(Query)과 문맥(Passage)을 받아 답변(Answer)을 생성하는 방식으로 작동한다.
- Generation-based Reader를 구현한 이유는 기존의 Extraction-based Reader 모델과의 성능 차이를 탐구하기 위해서였다. 추출형(Extraction-based) 모델은 주어진 문맥에서 답을 추출하는 방식이기 때문에, 문맥에 답이 없거나 Retrieval 단계에서 문맥이 부정확하게 추출된 경우에는 답변을 도출하지 못하는 한계가 있다.
- 반면, 생성형(Generation-based) 모델은 주어진 질문만으로도 문맥이 불완전하거나 누락된 상황에서 어느 정도 답을 유추해낼 수 있을 것이라고 판단했다.
- 또한, 대규모 모델의 경우, 현재 서버 환경에서 구동하기 어려운 문제를 해결하기 위해 LoRA(Low-Rank Adaptation) 기법을 적용하여 모델을 효율적으로 훈련할 수 있도록 하였다. 이를 통해 더 작은 메모리와 연산 자원을 활용하면서도 성능 저하를 최소화할 수 있었다.
6.4 모델 분석
6.4.1 BERT-base, ELECTRA-base
- 기존 base_line에 있던 모델로, BERT-base 모델의 경우에는 양방향 문맥 이해 능력이 뛰어나 MRC Task에 적합한 면이 있었으나, 모델 자체가 0.11B 정도의 매개변수를 갖추었기에 복잡한 문장에 대한 이해가 부족했고, BERT와 같은 매개변수를 가지고도 더 효율적이게 연산을 수행하는 ELECTRA-base 모델로도 이는 극복이 불가능 하였다. 따라서 더욱 큰 매개변수를 지닌 모델을 선정하기로 결정.
사용된 모델: klue/bert-base, monologg/koelectra-base-v3-discriminator
6.4.2 DeBERTa-base
- 기존 BERT 모델의 한계를 극복하기 위해 개발된 모델로 disentangled attention과 absolute + relative position encoding을 활용해 문맥 이해능력이 더 향상된 모델로써 약 0.14B 정도의 매개변수를 가지며 문장 내에서 각 단어가 가지는 위치 정보에 관해 더 효과적으로 처리할 수 있기에 문맥 이해 정밀도가 이전 모델보다 높다. 다만, 해당 모델을 베이스로 가지는 `timpal0l/mdeberta-v3-base-squad2`의 경우 한국어 특화가 아닌 다국어로 학습된 일반 모델이라 토크나이저 성능이 원활하지 않아 Mecab으로 postprocessing을 진행하였다. 실제 본 프로젝트에서 활용하였을 시에 BERT-base 보다 성능이 개선되었다.
사용된 모델: timpal0l/mdeberta-v3-base-squad2, kakaobank/kf-deberta-base
6.4.3 RoBERTa-base
- BERT를 기반으로 하여 학습 방법을 개선시킨 모델이다. 0.125B정도의 매개변수를 가졌으며, 이는 BERT 보다는 조금 더 큰 크기이다. 학습에 있어서 더 큰 배치 크기, 긴 학습시간, 더 많은 데이터가 사용되어 BERT의 한계를 극복하고자 한 모델이기에 다양한 문맥과 큰 데이터셋에 좋은 성능을 보인다.
본 프로젝트에서는 제공된 자원의 한계와 학습시간상 XLM-RoBERTa를 베이스로 하는 매개변수 0.355B의 Dongjin-kr/ko-reranker를 Retrieval로 사용하였고, Reader로는 매개변수 약 0.125B의 RoBERTa-base의 hongzoh/roberta-large-qa-korquad-v1를 활용해 보았다. 해당 Reader의 실제 성능은 BERT-base 보다는 좋았으나 DeBERTa 시리즈 보다는 좋지 못했다.
사용된 모델: Dongjin-kr/ko-reranker, hongzoh/roberta-large-qa-korquad-v1
6.5 앙상블
-
처음 앙상블을 진행하였을 때에는 Bert-base 및 DeBERTa-base 모델로 여러차례 실험을 진행하였으나, 퍼블릭에서 기대 만큼 좋은 성능을 보이지는 못했다. 그러던 중에 마스터님께서 말씀하셨던 “Public 점수 뿐 아니라, Validation 점수 또한 중시해라”라는 조언이 떠올라서 단순히 Public 점수만을 높히기 위함이 아닌 모델 자체의 일반화 성능을 높히기 위해 RoBERTa-base의 모델들을 앙상블에 추가하여 테스트한 결과 성능이 Private에서 크게 향상 된 것을 확인할 수 있었다.
-
성능이 향상된 구체적인 사유로는 앙상블의 요지가 좋은 모델을 섞는 것이 아니라, 다양한 관점의 모델들을 섞는 것에 있기 때문이라고 판단된다. 단순히 성능이 좋은 모델들을 나열하여 앙상블 한다면, 이는 결국 같은 base의 모델의 나열일 뿐이고, 해당 결과값들의 앙상블은 강점뿐 아닌 약점 또한 두드러질 것이기 때문이다.
따라서 본 프로젝트의 앙상블에서 단순히 public 스코어에 따른 좋은 모델을 나열해 앙상블 한 것이 아닌, validation에 중점을 두어 다양한 based를 가진 모델들을 섞은 것이 유효하게 작용했다고 판단된다.
7. 개인 회고
1. 프로젝트에 임하며 설정한 목표
-
‘경쟁’이 아닌 ‘성장’을 목표로 하자
대회 내내 public 스코어가 제공되었지만, 우리 팀은 그것을 상대적 ‘경쟁’지표로 삼는 것이 아닌, ‘절대적’ 성장 지표로 삼기로 하였다. 따라서 각자가 본 기계독해 프로젝트의 강의에서 배운 Retrieval, Reader 파트에 있어서 적용하고 싶었던 것들을 적용해 보기로 하였고 그 외에도 Data-centric한 의사결정을 하기 위해 실시간으로 데이터를 확인할 수 있는 EDA 서버에 관해 논의해보기도 하였다.
또한 단순히 Branch 생성, Issue 및 PR Request 제안 등을 위해 Git을 활용하는 것이 아니라, 프로젝트 자체의 버전 관리를 위해 Git 을 활용해 보자는 제안이 있었으며 따라서 본 프로젝트에서는 Release Tag를 활용하여 프로젝트의 버전관리 까지 신경을 써보기로 하였다
2. 구체적으로 프로젝트에 기여한 점
-
Retrieval에서의 BM25의 적용
기존에 Sparse Retrieval로 적용되었던 TF-IDF는 ‘문서 길이’에 관한 변수 고려가 전혀 되고 있지 않던 바, 더 정밀한 분석을 위해 BM25(Best Matching 25)를 적용하여 문서 길이와 빈도에 관해 TF-IDF 보다 더 정확하게 모델에 반영할 수 있었다.
실제 프로젝트의 결과에 있어서도 모델 성능에 public Score 기준 10%정도의 향상이 있었다.
-
실험 편의성을 위한 파일 재구조화
제공된 Base Line 코드에는 inference.py와 train.py가 분리되어 있는 등 실험 편의적인 측면에서 CLI에서 매번 직접 명령어를 수정해줘야 하는 불편이 존재하였기에, 기능이 분리되었던 두 파일에 관해 중첩되는 블록과 재사용성이 있는 부분을 고려하여 main.py라는 통합된 파일로 병합하였고, 해당 파일에서 argumnet parser를 활용하여 train, inference 기능을 수행할 수 있도록 파일을 재구조화 하였다.
해당 변경된 구조는 마지막까지 지속되어 main.py에서 모델의 훈련, 평가, inference 등을 진행하였다.
-
Data-centric 의사결정을 위한 EDA-server 증축
Streamlit을 활용하여 EDA 결과를 실시간으로 주고 받고 또 확인할 수 있는 서버를 구현하기로 하였으며, 그렇게 구축된 EDA server에서 DataEDA, TokenizerEDA 등의 페이지를 구축하였다.
특히 TokneizerEDA 페이지에서는 모델에 사용되는 토크나이저를 문자로 입력만 해준다면, 해당 토크나이저에 의해 UNK 처리되는 부분이 어떤 것인지 그리고 전체 데이터셋에서 UNK 토큰의 비율이 얼마인지 실시간으로 확인하여 팀원들이 해당 결과를 공유할 수 있도록 처리하여 팀이 데이터 중심의 의사결정을 할 수 있도록 도왔다.
3. 마주한 한계
-
3.1 PM의 부재: 데드라인, 프로토콜 미정
이전 프로젝트까지 팀 내에서 PM의 필요성에 관해 구체적으로 느끼지 못해서 본 프로젝트에서도 별 다른 의견 없이 PM은 공석인 채로 진행하였는데, 이것이 ‘협업’ 그 자체에 있어서는 좋지 않았던 것 같다. 일정을 조율해 주고 데드라인 및 코드작성에 있어서의 프로토콜 같은 것들을 더 깊게 나눌 수 있도록 PM을 정하여 프로젝트 전반을 관리할 수 있도록 하여야 했는데 그러지 못했다. 해당 문제점은 프로젝트 초반에는 드러나지 않았지만, 후반에 이르러 코드가 더 복잡해질수록 변수명 하나를 설정하더라도 일관되지 못하게 각자의 방식으로 진행하여 개인이 수행한 부분 외의 코드에 관해 이해하는데 시간이 너무 오래 걸렸다.
-
3.2 버전 관리 미흡: Git Release의 미흡한 활용
Git Release Tag를 활용하여 버전관리를 하고자 하였으나, 실제 구상한 바와 다르게 Semantic Versioning에서 1.0.0, 2.0.0, 3.0.0 과 같은 ‘주’ 버전 관리에만 신경썼고 그 외 세부적인 ‘부’, ‘수’ 버전 관리는 하지 못했다. 아무래도 프로젝트 기간 자체가 그다지 여유롭지 못했어서 그런 면도 있겠지만, Git에서 Merge 되는 순간에 해당 버전을 ‘주’ 단위로 업그레이드 시킬 것인지 ‘부’ 또는 ‘수’ 단위로 업그레이드 시킬 것인지에 관해 구체적으로 합의되지 못한 영향도 큰 것 같다.
4. 한계를 바탕으로 다음 프로젝트에서 시도해볼 것
-
Tableau를 활용하여 프로젝트 전반을 관리하는 Dash Board 구현
결국 전반적으로 프로젝트 상세(EDA, 모델 분석, 실험 가설 검증)를 기록할 Dash Board가 부재했던 것이 한계점들의 공통점 이라고 생각되었다. 구체적인 코드에 관한 사항들은 Git을 이용하여 버전을 관리할 수 있다고 하더라도, 해당 버전에 관해 가설 검증 및 구체적인 실험들은 ReadMe에 전부 녹여낼 수 없을 것이기에, 이를 따로 관리할 Dash Board가 필요하다고 생각한다. 다음 프로젝트에서는 앞서 언급한 한계점들을 구체적으로 반영할 Dash Board를 구현함과 함께 PM으로서의 역할을 수행해 보고 싶다.
