1. LoRA 실습
# 기존 모델의 학습 가능한 파라미터 고정
for param in model.parameters():
param.requires_grad = False# LoRA를 적용한 모델
low_rank = 2 # 해당 부분으로 lora의 rank size를 조절할 수 있습니다, 해당 부분을 수정하며 학습 가능한 파라미터 수의 변화를 확인해보세요!
lora_config = LoraConfig(
r=low_rank,
lora_alpha=16, # 모델이 빠르게 수렴하도록 돕는 역할 r에 곱해지는 녀석
target_modules=["query", "value"],
lora_dropout=0.1
)
model_with_lora = get_peft_model(model, lora_config)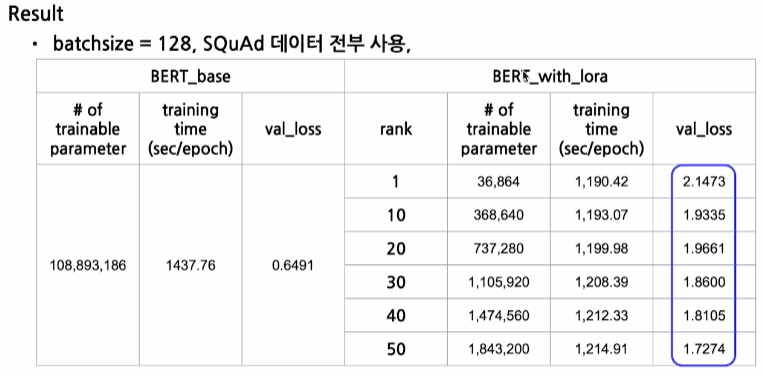
2. Adapter-Fusion
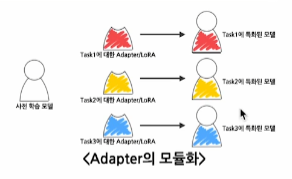
- Adapter를 결합하여 여러 task를 해결하는 모델을 만들자
이러한 모듈들을
통합!
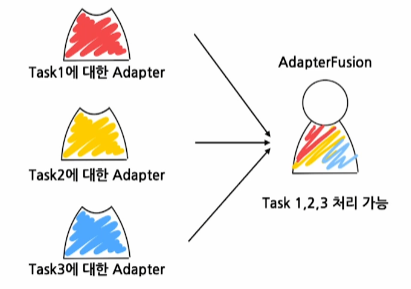
- AdapterFusion
- Adapter의 모듈화
Pre-trained model의 파라미터를 공유한다는 점에서 Adapter만 바꾸면 특정 task에 대한 빠른 전환이 가능하다.- 전환 없이 Adapter를 결합하여 모델이 task를 선택하여 수행
- Adapter의 모듈화
- 2-Stages algorithm
- Knowledge extraction
N개의 Specific task에 대한 N개의 Adapter parameter를 개별적으로 학습 - Knowledge composition
Adapter를 결합하는 단계
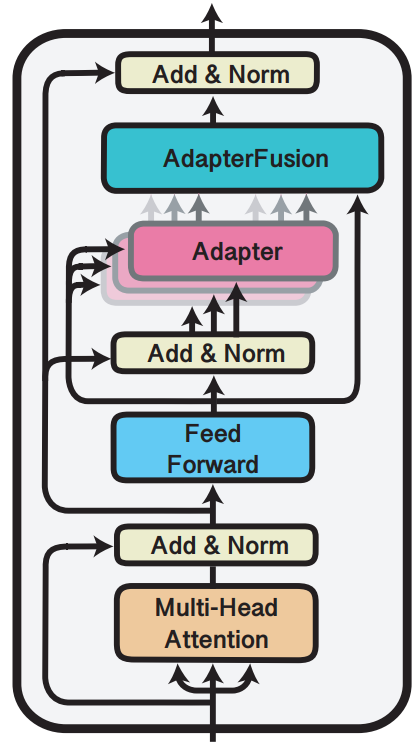
세개의 어댑터를 다 학습시켜 놨다면 그걸 다 집어넣고 취사선택할 수 있게 하는 것
Knowledge composition
입력에 따른 적절한 Adapter 결과를 선택해서 합치는 모듈(어댑터의 가중합이라고 볼 수 있다)
1. 병렬 Adapter 연산
각 Adapter 값의 출력을 구하는 과정
- 전 단계에서 학습된 여러개의 Adapter를 병렬적으로 위치시키고
- 병렬적으로 각 Adapter 값의 출력 값을 구함
출력값: N개의 Adapter의 각 출력값
- Adapter-Attention
각 Adapter 출력을 취합하여 최적의 출력 생성
사용자 입력에 맞는 Adapter의 가중치를 측정하는 Attention 모듈만 재학습
- 학습 시 이미 학습된 Adapter 및 모델의 파라미터는 고정
- 학습 파라미터(Attention)
- Query
사용자 입력의 Hidden state - Value
각 Adapter의 출력 - Key
각 Adapter의 Key
- Query
- 출력값
각 Adapter 출력의 가중합(weighted sum) 출력
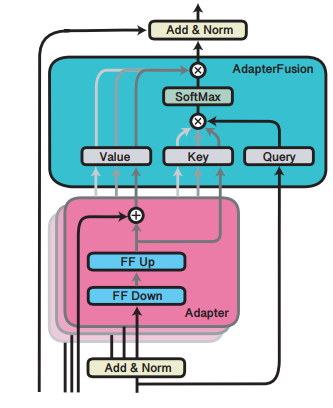
출처 : AdapterFusion: Non-Destructive Task Composition for Transfer Learning
Self-Attention
- Transformer에서는 Self-Attention을 통해 기존 입력의 가중 합을 출력하는 기법을 사용
- Key, Query, Value 3가지 값을 사용하여 Attention 계산
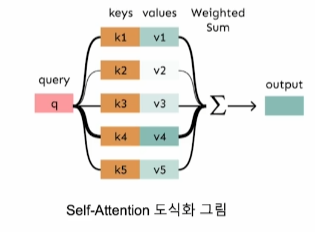
- 결과
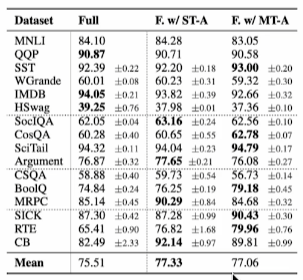
Adapter Fusion은 특정 Task를 위한 Adapter를 사용하는 성능과 비슷한 결과를 낼 수 있음
(ST-A / MT-A 비교)
3. QLoRA
LoRA에 Quantization 기법을 추가활용하여 더 효율적인 PEFT 방법론을 만든 것
-
사전 학습 모델의 가중치에 대해 Quantization 기법을 적용하여 메모리 사용량을 더욱 감소 시킨 것
-
핵심
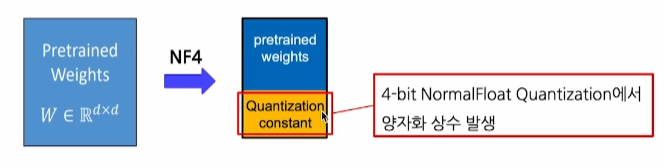
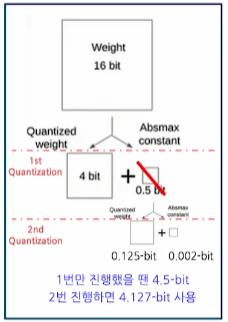
1. 사전 학습 모델에 대해서 Quantization 진행
예컨데, 16bit 가중치를 4bit로 변환한다.
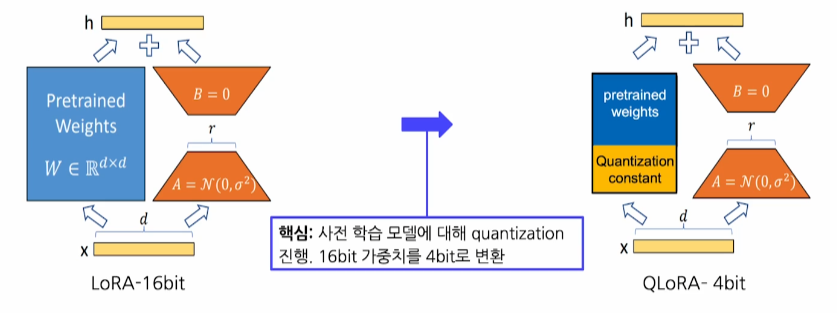
이떄 중요한것은 양자화 상수가 발생한다는 것이다.
-
양자화 상수
de-quantization에서 원본 값 복원에 사용되는 상수로써 이전에 배웠던Scale factor sZero-point z가 이에 해당한다.
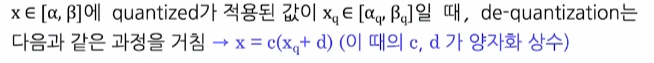
-
이때 양자화 상수 중에서
scalezero-point같은 주요 값들은 높은 precision(bit)로 저장하는데 이는 실제 성능에 큰 영향을 줄 수 있어서 정밀도가 높은 값으로 저장하는 것이 좋기 때문이다.- 그런데 여기서 한 걸음 더 나아가서 상수 저장에 드는 비용을 조금이나마 더 절약하려면, 양자화 상수에 대해서도 다시 Quantization을 진행해서 저장하는 방법이 있다 (
Double Quantization)
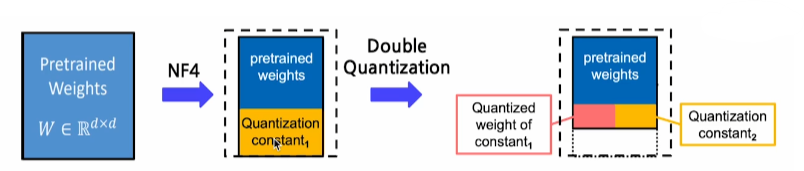
- 그런데 여기서 한 걸음 더 나아가서 상수 저장에 드는 비용을 조금이나마 더 절약하려면, 양자화 상수에 대해서도 다시 Quantization을 진행해서 저장하는 방법이 있다 (
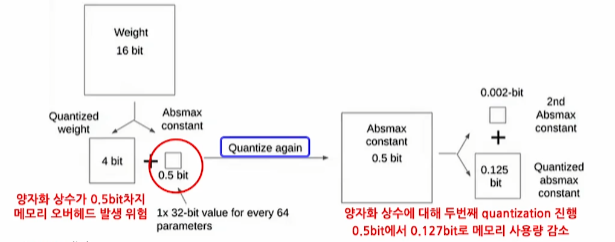
2. QLoRA: 발생한 양자화 상수 역시 메모리 차지 요소 -> Double Quantization을 적용
Q-LoRA의 경우 Double Quantization을 이용하는데
이는 사전 학습 모델의 가중치에 대해서 양자화를 진행했을 때 양자화 상수가 함께 저장되고
이러한 양자화 상수에 의한 메모리 오버헤드 발생 가능성을 다시 한번 양자화 상수에 대해서 Quantization을 진행하여 또 한번 메모리를 절약함으로 수행된다.
4. 요약
- AdapterFusion
Adapter의 특징(높은 parameter 공유 정도)을 이용하여 특정 task에 대한 성능을 극대화 하는 기법- Knowledge extraction
N개의 specific task에 대한 N개의 Adapter parameter를 학습 - Knowledge composition
AdapterFusion을 이용해서 특정 task에 특화된 Adapter들을 결합하여 Fusion Layer에 대해 최적화를 진행
- Knowledge extraction
- QLoRA
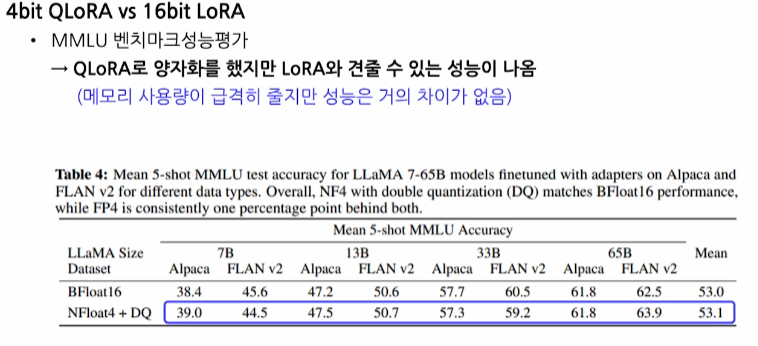
LoRA에 Quantization을 적용하여 메모리 사용의 효율성을 높인 모델- NF4(4-bit Normal FLoat)
16비트의 weight과 input을 4-bit로 quantization하여 연산 - Double Quantization
양자화 상수에 대한 quantization을 다시 한 번 더 진행하여 메모리 사용량 감소
- NF4(4-bit Normal FLoat)
