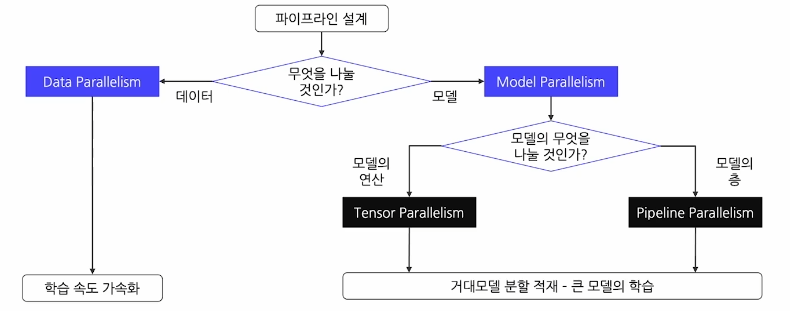
1. Distributed Training
- 모델을 여러개의 GPU로 분산시켜 GPU에 한번에 들어가지 않는 큰 모델도 학습 가능하도록 한다.
- 핵심 원리를 여러 GPU 간에 데이터를 분할하거나 모델 자체를 분할하여 여러 GPU에 걸쳐 훈련 프로세스를 병렬(Parallelism)화 하는 학습 기법
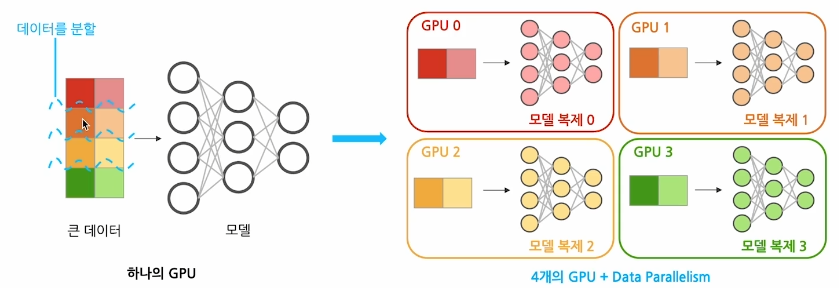
1.1 Data Parallelism
- 큰 데이터를 여러 GPU에 분할하여 동시에 처리해 학습 속도를 향상
- GPU간의 출력값들을 바탕으로 복제된 모델들을 동일하게 업데이트 해주는 과정이 필요하다.
`
이러한 방법은 사실 학습 시간은 절감되나, 전체 메모리 사용량 자체는 증가한다. 왜냐하면 모든 GPU로 모델을 복제해야 하기 때문에 메모리 사용량 자체는 증가하기 때문이다.
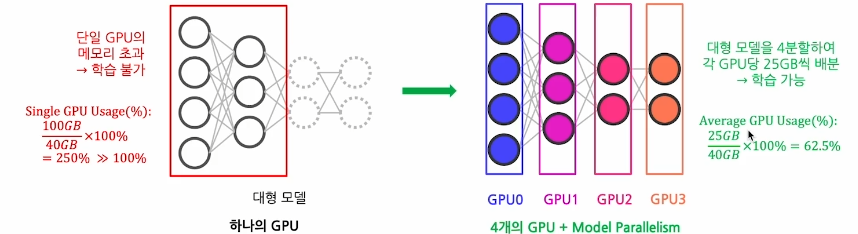
1.2 Model Parallelism
- 큰 모델을 여러 GPU에 분할하여 하나의 GPU로는 처리할 수 없는 대형 모델도 처리할 수 있도록 한다.
- 두가지로 나눌 수 있다.
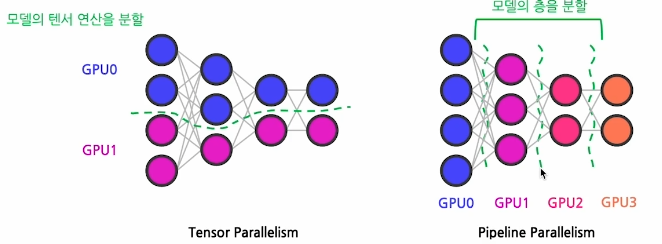
- Tensor Parallelism
모델을 텐서 연산 단위로 여러 GPU에 나누어 계산하는 방식 - Pipeline Parallelism
모델을 층 단위로 GPU에 할당하여 순차적으로 처리하는 방식
- Tensor Parallelism
- 두가지로 나눌 수 있다.
- 모델 병렬화는 단일 GPU 메모리 제약조건을 해결하면서 평균 GPU 메모리 사용량도 최적화 할수 있따.
- 단, GPU는 다른 GPU로부터 이전 레이어 결과값을 이어받아야 하기에 GPU 통신 간에 오버헤드로 인한 계산 부하가 생길 수 있음
| 방법 | 데이터 병렬처리 | 모델 병렬처리 |
|---|---|---|
| 병렬처리 대상 | 데이터 샘플 | 모델 파라미터 |
| 목표 | 학습 속도 가속화 | 거대모델 분할 적재 (초거대모델 학습) |
| 학습 속도 | GPU 개수에 비례 | 병목으로 인해 속도 저하 |
| 구현 난이도 | 비교적 쉬움 | 구현 및 관리가 어려움 |
- 결국 Distributed Training은 무엇을 나누어 GPU에 배분하는가의 문제이다.
2. Data Parallelism
단계별 설명
1. Initialization
모델을 모든 GPU에 복제하고, 데이터셋을 미니배치 단위로 나누어 각각 할당한다.
- 데이터셋을 미니배치 단위로 나누고
- GPU 개수에 맞춰 나눔
- Master GPU가 각 GPU에 모델 전달
- 각 GPU는 동일한 weights를 지님
- Forward Pass
각 GPU들은 할당받은 데이터에 대한 각 연산을 병렬적으로 수행
- 각 GPU는 전달받은 데이터의 logit값을 계산한다.
- 각 GPU는 이때 고유 logits를 가지고 있음
- 이후 Master GPU가 모든 logits 값을 취합하고
- Master GPU가 전체 logits들에 대한 loss 값을 계산하게 된다.
- Backward Pass
- Master GPU는 계산한 Loss에 대해서 각 GPU에 정송하고
- 각 GPU에서는 넘겨받은 Loss를 통해서 gradients를 계산한 뒤에
- Initialization에서 주어진 데이터셋에 대한 고유 gradients 값을 가진다.
- 다시 master GPU가 모든 gradient를 취합하고
- 다시 master GPU가 넘겨받아 모델 weights를 업데이트 한다.
- 이후에 다시 Initialization Step의 내용을 반복한다.
DP Workflow
정리하자면 데이터 병렬화의 워크플로우에서 핵심은
1. Backward Pass에서 master GPU가
2. 모든 GPU들에서 계산된 gradient들을 모아서
3. 모델 복제본을 업데이트 하고,
4. Forward Pass에서 모든 GPU들이
5.master GPU의 업데이트된 모델을 복사하여 훈련하는 것이다.
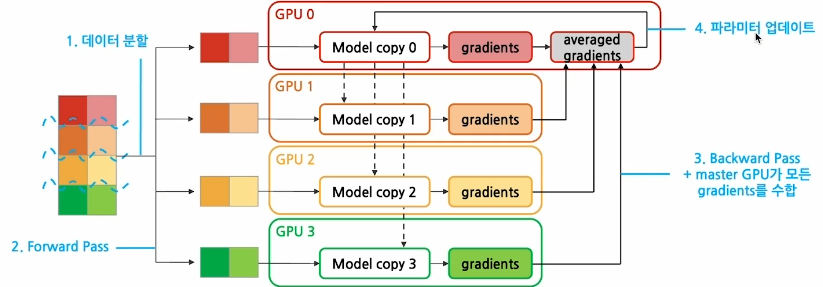
DP Workflow의 문제는
Master Node에서의 병목이다. 마스터 노드 GPU가 너무 과로하는 것이다.그래서 나온 해결방안: DDP
3. Distributed Data Parallelism(DDP)
- 병목의 주요 원인인 마스터 노드를 없애고 각자 알아서 모델 업데이트를 해보죠!
- 대신 모델 업데이트에 필요한 값들은 서로 공유하자!
- 대표적으로 AllReduce의 Ring 알고리즘이 존재
AllReduce Operation
- 여러 디바이스에 흩어져 있는 데이터를 서로 동시에 주고 받기 위한 Collective Operation 중 하나이다.
- 여러 디바이스에 있는 데이터를 모두 모아 하나의 값으로 줄인 다음 (sum, max, min, average 등) 그 결과를 모든 디바이스에 정송한다.
DDP Workflow
Backward Pass에서 AllReduce 연산을 사용하여 모든 GPU들에서 계산된 gradient들을 동기화한 후에 각 GPU에서 독립적으로 모델 weights를 업데이트하여 모델을 훈련시킨다.
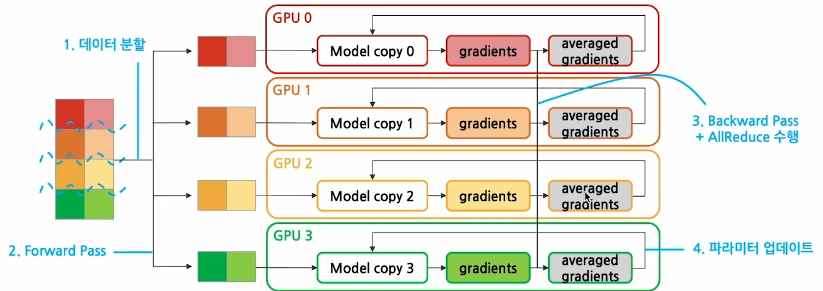
- 어찌 보면 비효율적이라고 볼 수도 있는데, 이게 마스터 노드 하나에서 병목생기는 것 보다 훨씬 효율적임
단계적으로 DDP를 설명하자면 아래와 같음
- Initialization
기존DP방식과 Initialization 단계 자체는 동일함.
데이터 셋을 미니배치 단위로 나누고
모델을 모든 GPU에 복제함 >> 각 GPU는 이때 같은 모델을 복제한 상태이므로, weights들은 모두 동기화된 상태임
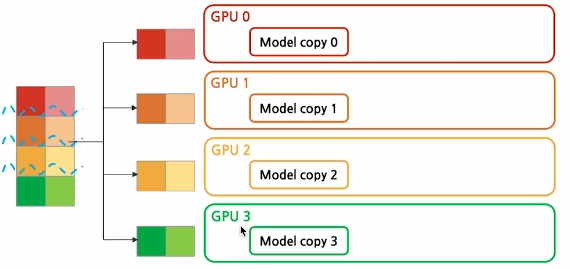
- Forward Pass
DP의 경우에 각각에 대한 Forward Pass 연산을 진행하고 그 도출된 Logits 값들을 마스터 노드에서 통합하여 Loss를 계산한 뒤에 다시 각 노드들에 나눠줬다면,DDP에서는 모델에 대한 카피 후에 나온 각 독립적인 Logits들을 알아서 각각의 노드에서 계산하게 됨.
과정을 다시 요약하자면 아래와 같음
- 각 GPU는 데이터와 복제된 모델을 통해 독립적인 logits들을 계산하여 각 GPU는 저마다의 Logits들을 가지게 됨.
- 각 GPU는 저마다의 Logits들을 가지고 Loss를 계산
바로 이 지점이 DP와 다른 점, 마스터 GPU가 Logits들을 모으는 과정이 없음
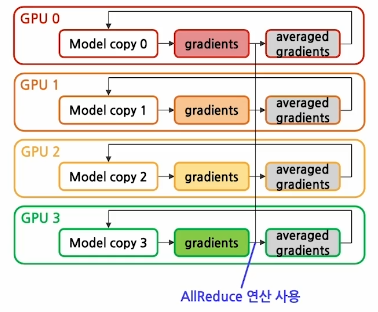
- Backward Pass
- 각 GPU들은 backpropagation을 통하여 gradients들을 계산하고 이때 각 GPU는 저마다의 데이터셋에 대해서 각기 다른 gradients 값을 가지게 된다.
- 각 GPU들이 가지고 있는 local gradients들은 앞서 말한
AllReduce연산을 거쳐 averaged gradients 값을 구하는 데에 사용되고
이때 모든 GPU가 똑같은 averaged gradients 값을 구하는 데에 사용된다.
이 과정에서 모든 GPU는 똑같은 averaged gradients 값을 가지게 되고 synchronized gradients 즉, 각 GPU의 가중치가 이때 다시 동기화가 된다 - 각 GPU는 이 averaged gradients를 가지고 저마다의 모델 weights들을 업데이트한다. 이때 각 GPU는 다시 동일한 모델을 가지게 되고, 이미 동일한 모델을 가지게 된 바, 다음 iteration에서 forward pass를 거칠때 굳이 모델을 새로 복제할 필요가 없게 된다.
(Local gradients>>AllReduce 연산>>averaged gradients(synchronized gradients) >> 이 gradients를 가지고 저마다 GPU에서 처음에 initialized 된 모델에 대해weights 업데이트실시>> 동일한 wieghts로 업데이트가 된 바,이미 모델 또한 synchronized 되었다.)
| 라이브러리 | DP (DataParallel) | DDP (DistributedDataParallel) |
|---|---|---|
| Gradient 동기화 | master GPU가 모두 모아 평균내어 모델을 업데이트 | AllReduce 연산을 사용하여 모든 GPU가 동시에 업데이트 |
| 모델 복제 | master GPU의 모델을 매 iteration마다 복제 | 모든 GPU가 Initialization 단계에서 한 번만 복제 |
| 통신 오버헤드 | master GPU에 리소스가 몰려 통신비용 매우 높음 | master GPU가 없어 통신비용 낮음 |
| 장점 | 구현이 쉬움 | 효율적인 통신으로 학습 속도 증가 |
| 단점 | 병목 현상 가능성 | 구현이 상대적으로 복잡 |
4. DDP Code Walkthrough
- Concept(예시를 통한 설명)
- 2대의 서버 머신(host)에는 각각 2대의 GPU가 있다.
이때 사용할 수 있는 GPU는 총 4개로, Distributed Trianing의 프로세스는 4개로 나누어지게 된다.
- 2대의 서버 머신(host)에는 각각 2대의 GPU가 있다.
- Rank는 Distributed Training에 참여하는 각 프로세스에 할당된 고유한 식별자를 의미하며(
global) - Local_rank는 각 서버 머신 내에서 프로세스를 구별해주기 위해 사용되는 것 (
서버내에서 구별) - 결국 연산이 이루어지는 곳은 GPU 이다.
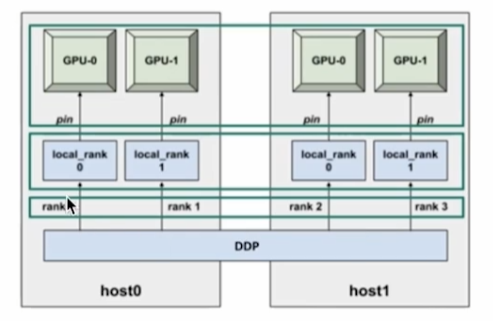
| Host | GPU | Local Rank | Rank |
|---|---|---|---|
| host0 | GPU-0 | 0 | 0 |
| host0 | GPU-1 | 1 | 1 |
| host1 | GPU-0 | 0 | 2 |
| host1 | GPU-1 | 1 | 3 |
이 표는 두 개의 호스트와 각각 두 개의 GPU를 가진 분산 데이터 병렬(DDP) 설정을 나타낸다.
각 GPU는 분산 시스템 내에서의 위치를 나타내는 로컬 순위 및 글로벌 순위를 할당받는다.
4.1 Initialization
-
ddp_setup 함수 추가
- world_size, rank 지정 및 device 정의
- init_process_group(): 프로세스 그룹을 초기화
import torch import torch.multiprocessing as mp from torch.utils.data.distributed import DistributedSampler from torch.nn.parallel import DistributedDataParallel as DDP from torch.distributed import init_process_group, destroy_process_group def ddp_setup(rank, world_size, gpu_list): os.environ["MASTER_ADDR"] = "localhost" os.environ["MASTER_PORT"] = "12355" torch.cuda.set_device(gpu_list[rank]) init_process_group(backend="nccl", rank=rank, world_size=world_size)
4.2 Prepare Model & Dataset: 과정 동일
4.3 Data Splitting
DistributedSampler()를 사용하여 기존 DataLoader를 교체한다
이는 각 GPU에 다른 데이터가 들어가도록 분배하는 과정에 해당한다.
데이터를 GPU에 균등하게 나누는 작업으로써 이 샘플러 클래스가 해당 작업을 수행해준다.
셔플링 같은걸 할때 순서가 꼬일 수 있는데 그걸 방지할 수 있도록 Random Seed를 설정해서 데이터 순서를 동기화하거나, 각 GPU들을 동기화 하여 각 프로세스가 자기할당된 데이터만 처리를 하고 서로 다른 프로세스 안에서는 데이터중복이 일어나지 않도록 보장하는 역할을 이
DistributedSampler()가 수행해줌.
single_gpu.py
def prepare_dataloader(dataset: Dataset, batch_size: int):
return DataLoader(
dataset,
batch_size=batch_size,
pin_memory=True if torch.cuda.is_available() else False,
shuffle=True
)multi_gpu.py
def prepare_dataloader(dataset: Dataset, batch_size: int):
return DataLoader(
dataset,
batch_size=batch_size,
pin_memory=True if torch.cuda.is_available() else False,
shuffle=False,
sampler=DistributedSampler(datset)
)4.4 Trainer Class
각 GPU에서 계산된 gradients들을 동기화하기 위해 모델을 DDP로 wrapping 해줌
- train_data.sampler.set_epoch(): DistributedSampler를 위한 epoch 세팅
single_gpu.py
class Trainer:
def __init__(self, model, train_data, optimizer, gpu_id):
self.model = model.to(gpu_id)multi_gpu.py
class Trainer:
def __init__(self, model, train_data, optimizer, gpu_id, gpu_list):
self.model = DDP(model, device_ids = [gpu_id] # wrapmodel with DDP
def _run_epoch(self, epoch, max_epochs):
self.train_data_sampler.set_epoch(epoch) # set epoch for DistributedSampler4.5 main() function & execution code
- destroy_process_group():
프로세스 그룹을 종료 - mp.spawn():
여러 개의 GPU들을 다루기 위해multiprocessing spawn추가
spawn이 멀티프로세싱을 만들어주는 역할을 한다고 보면 됨
single_gpu.py:
def main(device, total_epochs, batch_size):
dataset, model, optimizer = load_train_objs()
train_data = prepare_dataloader(dataset, batch_size)
trainer = Trainer(model, train_data, optimizer, device)
trainer.train(total_epochs)
trainer.plot_loss()multi_gpu.py
def main(rank, world_size, total_epochs, batch_size, selected_gpus):
actual_gpu_id = selected_gpus[rank]
ddp_setup(rank, world_size, selected_gpus)
dataset, model, optimizer = load_train_objs()
train_data = prepare_dataloader(dataset, batch_size)
trainer = Trainer(model, train_data, optimizer, actual_gpu_id, selected_gpus)
trainer.train(total_epochs)
destroy_process_group()
multi_gpu.py (2)
if __name__ == "__main__":
# Determine which GPUs to use
if args.gpus is not None:
available_gpus = torch.cuda.device_count()
for gpu in args.gpus:
if gpu >= available_gpus:
raise ValueError(f"GPU {gpu} is not available. Only {available_gpus} GPUs are present.")
gpu_list = args.gpus # Set gpu_list to specified GPUs
world_size = len(args.gpus)
else:
# Use all available GPUs
gpu_list = list(range(torch.cuda.device_count()))
world_size = len(gpu_list)
mp.spawn(
main,
nprocs=world_size,
args=(world_size, args.total_epochs, args.batch_size, gpu_list),
join=True
)-
추가적으로
argument addiction으로 사용하려는 특정 GPU들을 지정할 수 있도록 파서를 받을 수 있다.parser.add_argument('--gpus', nargs='+', type=int, default=None, help='Specific GPU IDs to use. If not specified, uses all available GPUs.')
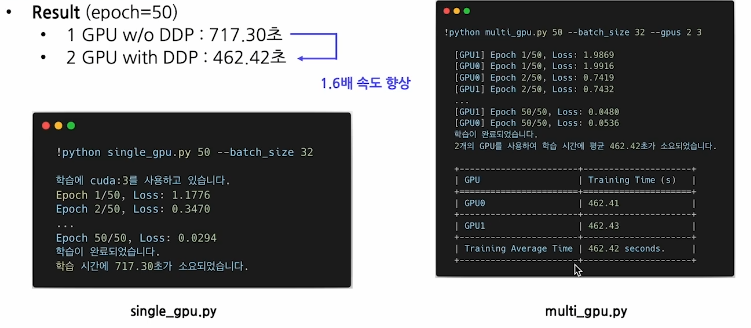
4.6 결과 확인
5. 요약
분산 학습 (Distributed Training)
여러 GPU간에 데이터를 분할하거나 모델 자체를 분할하여 여러 GPU에 걸쳐 훈련 프로세스를 병렬(Parallelism)화하는 학습 기법
주요 병렬화 방식:
- Data Parallelism: 큰 데이터를 여러 GPU들에 분할하여 동시에 처리함으로써 학습 속도를 높임
- Model Parallelism: 큰 모델을 여러 GPU들에 분할함으로써 하나의 GPU로는 처리할 수 없는 대형 모델도 처리 가능
- Tensor Parallelism
- Pipeline Parallelism
Data Parallelism
일반적인 Data Parallelism (DP)
- GPU간의 출력값들을 바탕으로 복제된 모델들을 동일하게 업데이트하는 과정
- Backward Pass: master GPU와 다른 GPU들에서 계산된 gradient들을 모아 모델 복제본을 업데이트
- Forward Pass: 모든 GPU들이 master GPU의 업데이트된 모델을 복사하여 훈련
Distributed Data Parallelism (DDP)
- DP에서 마스터 GPU를 없애고 모든 GPU들이 각자 알아서 모델 업데이트를 수행
