
🔩 Level. 1 : 데이터 전처리
광고 캠페인 성과 데이터(CTR, CPC, ROAS, conversion_rate 등)를 불러오고,
성과 분석에 앞서 필수적인 전처리 작업 및 파생 지표 생성을 수행합니다.
[결측치 처리]
날짜별 클릭률 (CTR) : 1.0(=100%) 이상 수치는 결측치로 간주하고 NaN으로 대체합니다.
클릭 당 비용 (CPC) : 빈칸으로 표시된 것은 결측치로 간주하고 평균값으로 대체합니다.
문제 1-1 : 데이터 전처리 (첫 번째 라이브 세션)
- 요구 사항 = CSV 파일 읽기 및 데이터 기본 확인
1). CSV 파일을 읽어 DataFrame(df) 을 생성합니다.
# 1) CSV 파일을 읽어 DataFrame 생성 (Data는 manu)
df = pd.read_csv('Data/marketing_campaign_data.csv')
df➡️ df = DataFrame(데이터 프레임)
➡️ pd.read_csv = pandas 라이브러리에서 csv파일을 읽어오기
➡️ ('Data/marketing_campaign_data.csv') = ('데이터 저장 위치 / 데이터 파일 이름.csv')
✅ pandas 라이브러리에서 data에 저장 되어 있는 marketing_campaign.csv파일을 읽어와 df(데이터 프레임)을 만든다.
[결과 값]
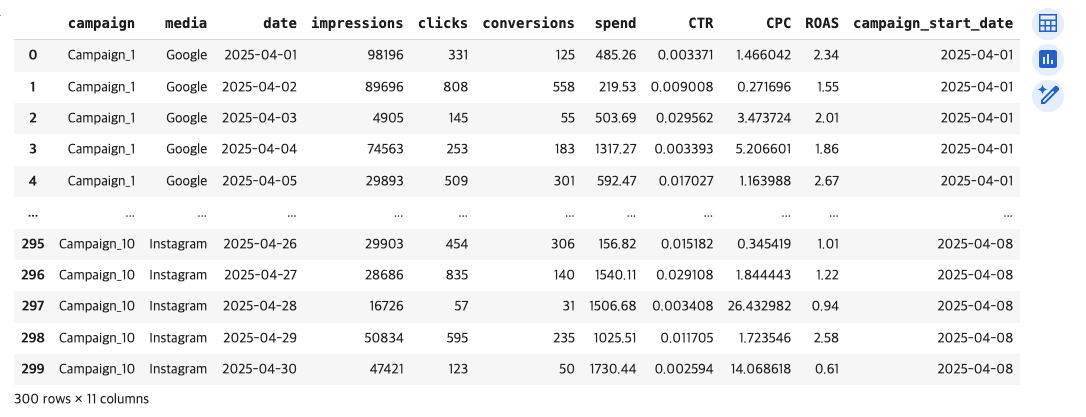
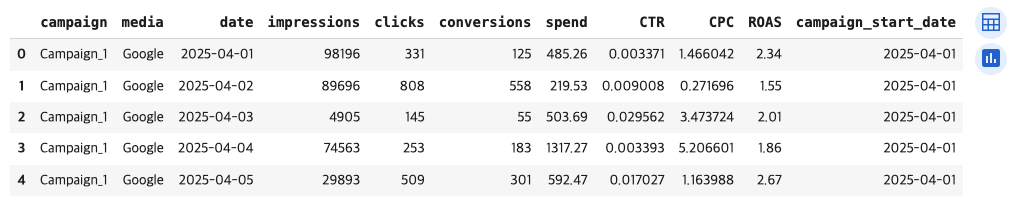
2). 데이터셋 미리보기 : df의 상위 5개 행을 출력하세요.
# 2) df의 상위 5개 행을 확인하고 출력
df.head()➡️ head() = 상위 데이터 5개 행을 확인하고 출력하는 매써드
[결과 값]
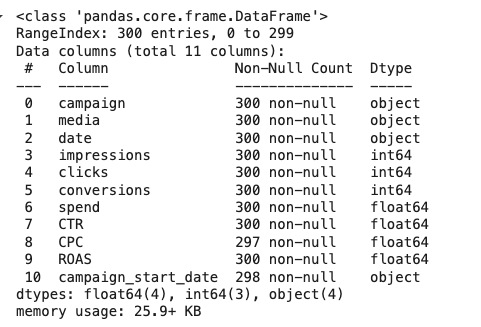
3). 데이터 정보 : 컬럼명, 데이터 타입, 결측치 등 기본 정보를 출력하세요.
# 3) df의 기본 정보(컬럼명, 데이터 타입, etc.) 출력
df.info()➡️ info()
- 총 행 수와 컬럼 수
- 각 컬럼의 데이터 타입
- 결측치(null) 개수
- 메모리 사용량
[결과 값]
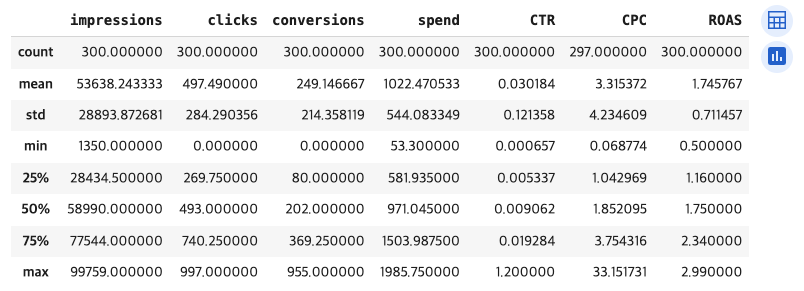
4). 기술 통계 : 평균, 표준편차, 최소/최대값 등 기술 통계를 출력하세요.
# 4) df의 기술 통계(평균, 표준편차 등) 출력
df.describe()➡️ describe() = 숫자형 데이터의 기본 통계를 확인
[결과 값]
5). 결측값 개수 : 각 열별로 결측값이 몇 개인지 출력하세요.
# 5) df의 컬럼별 결측값 개수 출력
df.isnull().sum()➡️ isnull() = isna()
- 결측값(NaN)을 찾을 때 사용
- 결측값(NaN)인지 아닌지를 True/False로 판별해주는
함수
❓왜 함수라고 부를까? 왜매써드가 아닐까?❓
⭕️ 튜터님의 조언 ⭕️
클래스 안에 함수를 만들면 그 함수가 그 클래스의 매써드(Method)가 된다.
즉, 함수와 매써드는 같은 의미이다.
우리가 만든 프로그램에(예시: 계산기 = 파이썬 내장 함수를 이용해서 만듦) 함수를 쓰면 그건 함수라고 부른다.
하지만 외부에서 가져다 쓰는 라이브러리 같은 곳에서 쓰는 함수를 매써드라고 얘기하는 것이 더 정확하다.
객체. 함수() = 객체. 매써드()
같은 의미이지만 외부 라이브러리를 썼을 때 지칭하는 것은 매써드가 더 정확하다.➡️ sum() = 결과가 여러 개(series)일 때 값의 총 합을 구하기 위한 함수
[결과 값]

6). 중복 행이 몇 개인지 출력하세요
# 6) df의 중복 행이 몇 개인지 출력 #sum()은 앞의 결과가 여러개(series)일 때 값의 총합을 구하기 위해서
df.duplicated().sum()➡️ duplicated()= 중복된 행(또는 값)을 True로 표시해주는 매써드 ▶︎ mysql 기준 유사한 함수 = DISTINCT
[결과 값]

문제 1-2 : 결측치 처리
1) CTR 열에 이상치로 추정되는 1.0 이상의 값을 발견했습니다.
이는 100%를 넘는 수로 결측치로 구분됩니다. 이를 NaN(결측치)로 대체해야 합니다.
# 1) CTR 열에서 1.0 이상인 값을 NaN으로 대체
import numpy as np
df.loc[df['CTR'] >= 1.0, 'CTR'] = np.nan➡️ numpy란? = Numerical Python의 줄임말
➡️ import numpy as np란?= numpy를 호출하고 별칭이 np라는 의미
➡️ df.loc[] → df.loc[조건, '열이름'] = 새로운 값
➡️ df['CTR'] >= 1.0 → CTR 열에서 1.0 이상인 값을 찾는 조건
➡️ 'CTR' = '열 이름'
➡️ np.nan → 해당 조건을 만족하는 CTR 값을 NaN으로 바꿈
[결과 값]
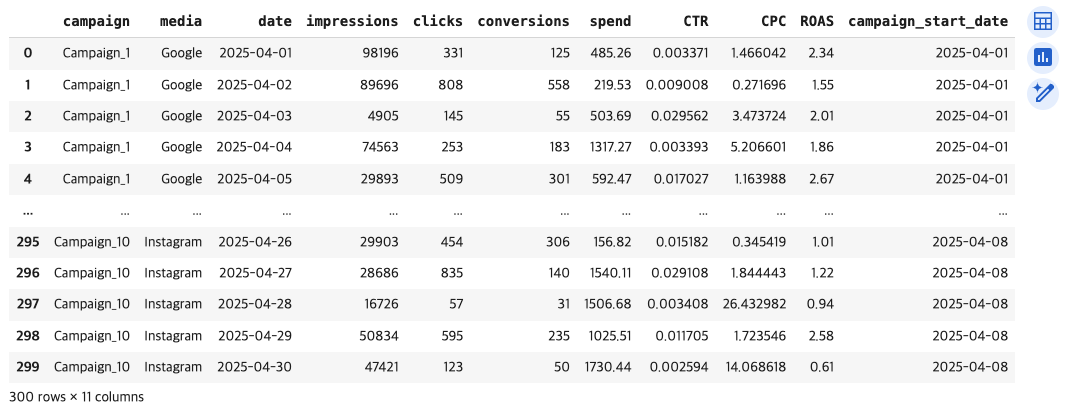
❓결과 값은 나왔는데 df.head(50), df.tail(50)을 써도 이상치가 감지 되지 않았다. 어떻게 해야할까?❓
⭕️ 튜터님의 조언 ⭕️
⭐️ 디 버 깅 작 업 ⭐️ → 나에게 있어서 취약점
1️⃣ 전체 데이터에서 실제 1.0 이상인 데이터가 있는지 확인한다.
#디버깅 작업 #ctr 컬럼에서 값이 1.0이상인 값 출력
df[df['CTR'] >= 1.0][결과 값]

➡️ 이상치 값 3개 확인
2️⃣ 데이터를 Nan으로 변환
import numpy as np
df.loc[df['CTR'] >= 1.0, 'CTR'] = np.nan3️⃣ 결과 값이 Nan으로 확인하기
#내가 푼 방법
df['CTR'].isnull().sum() [결과 값]
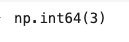
➡️ Nan 값이 3개인 것 확인
➡️ .sum( ) 메써드를 사용하면 개수를 셀수 있지만 개별 값이 나오지 않음
➡️ Nan 값이 많을 때는 head( ),tail( ) 하거나 sum( ) 사용하는게 유용
#튜터님께서 알려주신 방법
df[df['CTR'].isna()] [결과 값]

➡️ 아까 디버깅했을 때 나왔던 값들이 Nan으로 바뀐 것을 확인 할 수 있음
➡️ isna() 메써드는 Nan인 값만 필터링 해줄 수 있음
➡️ Nan 값이 적을 때는 직접 필터링하는게 유용
➡️ 두 매써드는 같음 ▶︎ isnull( ) = isna ( )
오늘의 인사이트
⭐️ 디 버 깅 작 업 ⭐️ → 나에게 있어서 취약점
문제 풀 때 디버깅 작업 꼭꼭 하기
