Pytorch로 Data 분산학습하기
모델이 크면 클 수록 좋은 성능을 보이는 딥러닝 학습에서 데이터 분산처리는 필수적인 과정이다. (특히나 자연어처리는 더더욱...) pytorch에서 기본으로 제공하는 Data Paralellism 모듈 DataPrallel과 DistributedDataParallel 작동원리, 장단점에 대해 정리하겠다.
DataParallel
- 코드 한줄 추가해 Data Parallelism 적용가능
- 싱글프로세스 멀티쓰레드 (싱글머신에서만 가능)
- 학습시 메모리 불균형 초래함
DataParallel은 pytorch에서 적용하기 가장 간단한 모듈로 준비된 모델을 감싸는 라인 한 줄을 추가하면 완성할 수 있다.
...
model = nn.DataParallel(model)
...싱글 프로세스에 멀티쓰레드들로 모델을 복사하여 데이터를 나눠 처리한 후 하나의 gpu에서 결과를 총합하는 것이 대략적인 흐름이다. 자세한 동작 방식은 아래와 같다.
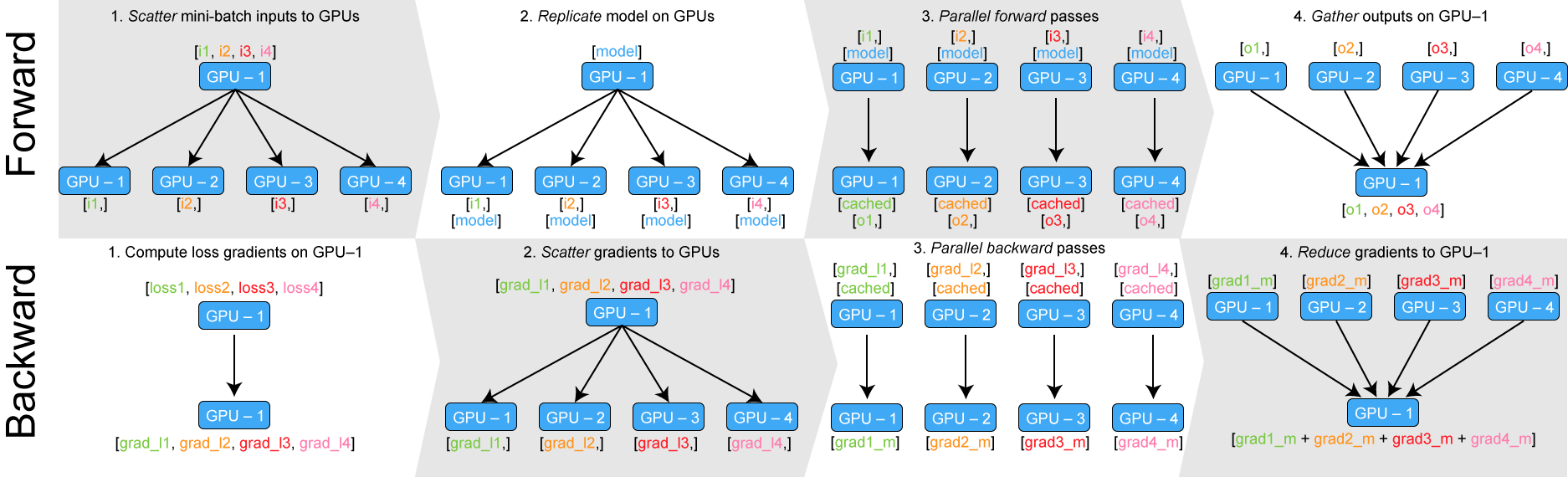
forward 단계에서 데이터를 각 gpu로 쪼개어 나눈다음 모델을 복제시켜 병렬적으로 각 loss를 계산한다. 그리고 그에 대한 결과를 다시 gpu-1으로 모아 gradient를 계산한 후 gpu들로 다시 분산시키켜 backward 과정을 진행한다. 여러모델에서의 결과를 gpu-1으로 모아 계산하기 때문에 모으는 과정마다 gpu-1의 메모리 사용량이 많아진다.
이처럼 한 곳에서 다른 gpu들이 작업한 것들을 총정리하여 분산학습이 진행되기 때문에 메모리 불균형이 발생할 수 밖에 없는 모듈이기 때문에 대용량의 데이터와 큰 모델들을 사용하다보면 gpu 자원 1%가 매우 소중하기 때문에 이와같은 메모리 불균형은 DataParallel의 치명적인 단점임이 분명하다. 또한 싱글 프로세스 위에서 돌아가기 때문에 멀티쓰레드 사용에 걸리는 GIL 제약 때문에 속도가 느리며 Model Parallelism과 함께 적용할 수 없다는 점도 고려해야한다. (모델의 크기는 점점 커지고 가진 자원은 한정적이고... inference조차 힘든 모델을 학습가능하게 도와주는 Model Parallelism도 조만간 정리할 예정)
DistributedDataParallel
- 멀티프로세스 Data Parallelism (멀티머신으로 학습가능)
- 멀티프로세스에 모델 각각 띄워 내부적으로 모델 공유
- 메모리 불균형 없지만 학습코드를 멀티프로세스 돌게끔 짜야해서 DP보다 복잡함
DDP(DistriutedDataParallel)는 멀티프로세스 하나하나에 모델을 띄운 후 데이터를 분산시켜 모델을 학습하고 내부에서 모델 메모리를 공유하며 학습시키는 모듈로 보다 자세히 설명하면, pytorch의 multiprocess 모듈로 모델을 프로세스 마다 띄워 각 모듈을 해당 rank(gpu 노드)에 위치시킨 후 여러 프로세스(gpu)들에 데이터를 적절히 나누는 Datasampler를 사용해 분산학습시킨다.
data Parallel과 다르게 각 프로세스 결과를 한 노드에 모아 학습시키지 않고 backward 과정에서 내부적으로 통신하는 trigger를 작동시켜 gradient를 동기화하기 때문에 메모리 불균형을 일으키지도 않으며, 또한 멀티프로세스로 돌기때문에 분리된 컴퓨터 노드를 연결해 학습시킬 수 있으며 Model Parallelism과 함께 사용할 수 있다.
Pytorch DDP tutorial (https://pytorch.org/tutorials/intermediate/ddp_tutorial.html) 에 소개된 간단한 예제로 분산처리 과정을 정리해 보면...
import os
import sys
import tempfile
import torch
import torch.distributed as dist
import torch.nn as nn
import torch.optim as optim
import torch.multiprocessing as mp
from torch.nn.parallel import DistributedDataParallel as DDP
def setup(rank, world_size):
# 각 프로세스가 다른 프로세스들과 통신할 수 있도록 분산환경 설정
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
# initialize the process group
dist.init_process_group("gloo", rank=rank, world_size=world_size)
def cleanup():
dist.destroy_process_group()
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net1 = nn.Linear(10, 10)
self.relu = nn.ReLU()
self.net2 = nn.Linear(10, 5)
def forward(self, x):
return self.net2(self.relu(self.net1(x)))
def demo_basic(rank, world_size):
print(f"Running basic DDP example on rank {rank}.")
# 1. 해당 gpu 프로세스 초기화
setup(rank, world_size)
# 2. 모델 파라미터 해당 gpu 프로세스에 위치시킴
# create model and move it to GPU with id rank
model = ToyModel().to(rank)
# 3. DDP 모듈 적용
ddp_model = DDP(model, device_ids=[rank])
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
optimizer.zero_grad()
outputs = ddp_model(torch.randn(20, 10))
# 4. 처리할 데이터 모델과 같은 프로세스로 옮기기
labels = torch.randn(20, 5).to(rank)
# 5. backward를 진행할 때 DDP 내부적으로 gradient 동기화 통신이 진행된다.
loss_fn(outputs, labels).backward()
optimizer.step()
cleanup()
def run_demo(demo_fn, world_size):
# 0. pytorch multiprocess 모듈사용
mp.spawn(demo_fn,
args=(world_size,),
nprocs=world_size,
join=True정리하면, #0 메인 함수에서 pytorch multiprocess모듈로 각 프로세스에 학습함수를 호출한다. 각 학습함수는 gpu index(process index)와 인자를 넘겨받아 #1 해당 gpu에 분산환경을 설정하고 #2 모델 파라미터를 해당 gpu 옮기고 #3 모델에 DDP 모듈로 waraping 하고 모델 처리 결과를 평가하기 위해 #4 label을 gpu 메모리 위치로 옮겨 loss를 계산하고 #5 backward를 수행해 전체 프로세스들과 gradient를 공유한다.
지금까지 pytorch에서 기본으로 제공하는 두 Data Paralellism, DataParallel과 DistributedDataParallel 작동원리와 장단점, 적용방법을 정리하였다.
다음은 모델 파라미터를 쪼개 여러 gpu에 분산시키는 Model Paralellism에 대해 소개할 예정이다.
Inference
- https://medium.com/huggingface/training-larger-batches-practical-tips-on-1-gpu-multi-gpu-distributed-setups-ec88c3e51255
- https://medium.com/daangn/pytorch-multi-gpu-학습-제대로-하기-27270617936b
- https://github.com/pytorch/examples/blob/master/imagenet/main.py
- https://pytorch.org/tutorials/intermediate/ddp_tutorial.html
