현재 Pytorch는 Tensorflow를 뛰어넘어 가장 많이 사용되는 Deeplearning 프레임워크이다. pytorch가 연구/개발하기에는 여러모로 편리하지만 실제 realtime 서비스에 사용하기엔 추론성능이 좋지 않아 연구는 pytorch 서비스는 tensorflow로 한다는 말이 있을 정도다. 이 포스팅은 개발한 pytorch 모델을 바로 서빙에 사용할 수 있도록 Pytorch로 개발한 모델(using transformers)을 onnx포멧으로 변환하고 모델최적화, 그리고 onnxruntime으로 서빙하는 과정을 소개한다.
ONNX (Open Neural Network eXchange)
AI 서비스은 위해 모델을 개발, 학습하고 추론서비스를 배포하는 과정으로 나뉠 수 있는데 개발자에 따라 선호하는 프레임워크와 추론서비스가 배포되는 하드웨어가 다양해 최적화하는 과정이 복잡하다. 자연어처리분야 AI개발자인 나는 Pytorch로 모델 개발하는 것을 선호하지만 Pytorch로 실시간 추론서비스를 개발하기엔 너무나 느리다;;. ONNX는 선호하는 프레임워크에서 개발한 후에 어느 환경에서나 실행할 수 있게하는 솔루션으로 Tensorflow, Pytorch, Caffe 등 다양한 프레임워크들을 연결시킬 목적으로 만들어졌다.
ONNX Runtime은 ONNX 포멧을 배포하기 위한 엔진으로 Linux, Window, Mac 에서 작동하며 C, Python, Node.js 와 같이 다양한 언어에서 API를 제공하고 있다.
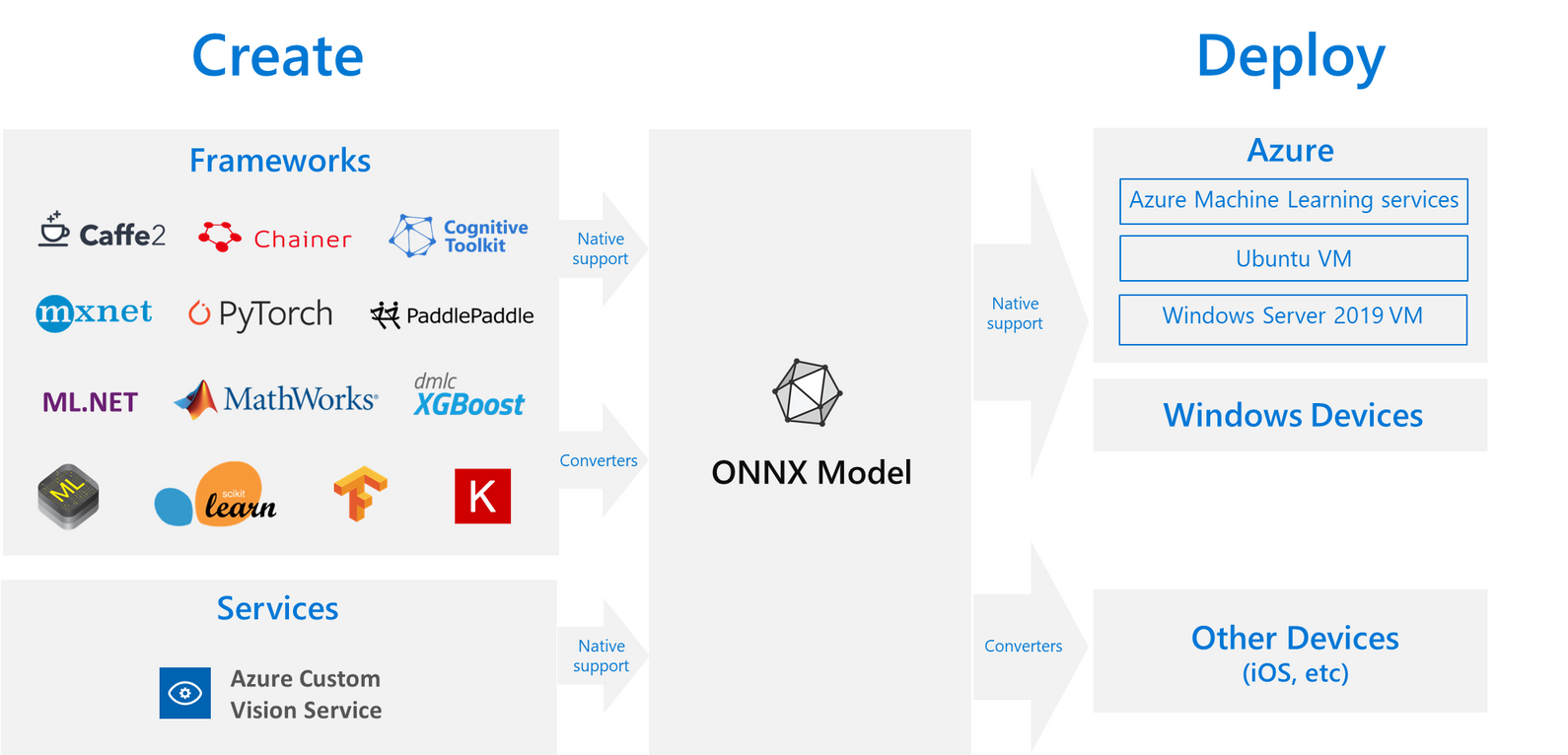
ONNX 오픈소스를 리드한 마이크로소프트 사의 공식 도큐먼트에서 가져온 그림이다. azure로 쓰여있는 것은 마소에서 가져온 그림이라 그렇다.
ONNXRuntime is faster than Pytorch
Numpy와 유사한 Pythonic한 코드, 디버깅 편리성 때문에 pytorch는 AI개발자에게 가장 선호되며 오픈소스 라이브러리들을 가장 많이 보유하고 있는 프레임워크이다. 그러나 위에서 언급했듯이 추론서버를 개발하기에는 속도가 느리다는 단점이 있다. 이를 보완하기 위해 Pytorch 모델을 Onnx으로 변환 후 Onnxruntime을 사용하여 추론엔진을 구축하는 방법이 있다. Onnxruntime은 Pytorch 만으로 추론했을 때 대비 약 2~3배 정도 속도향상을 이룰 수 있다. 별다른 최적화 과정없이 같은 모델로 돌렸음에도 왜 이 정도 차이가 발생할까?
pytorch의 Pythonic한 스타일, 편리한 디버깅은 Dynamic Graph 방식을 사용하기 덕분인데 이는 인터프리터 언어와 컴파일 언어의 차이와 유사하게 모델(코드)에 맞는 최적화가 불가능하다. Onnxruntime Graph는 Static Graph 방식을 사용하기에 준비과정에서 모델의 모든 구조를 보고 모델과 하드워에어에 맞게 최적화한 후 엔진에 로딩하기 때문에 효율적이게 추론할 수 있다.
Pytorch -> ONNX Runtime 변환 과정
이론 설명을 마치고 pytorch를 onnx포멧으로 변환하는 과정을 소개하고 onnxruntime에 올려 pytorch와 추론 성능을 비교한다.
Convert BERT model to ONNX format
- Bert 모델 로딩
 transformers 라이브러리 사용해 pytorch기반 bert 문장분류기를 정의한다.
transformers 라이브러리 사용해 pytorch기반 bert 문장분류기를 정의한다.
- 모델 ONNX 포멧으로 변환하기

torch.onnx.export함수에 model과 필요한 인자들을 넣어 onnx포멧으로 모델을 저장한다.- model: export할 모델 넣는다.
- args: 기본으로 trace방식으로 export하기에 임의의 값을 넣어준다. 이때 주의할 것은 if와 같은 값에따라 가변적인 로직이 들어가 있다면 이때 넣는 임의의 값에 의해 굳어지므로 그부분은 script방식으로 변환해야한다.
- f: 변환한 모델을 저장할 file path를 지정한다.
- input_names: 모델의 input 변수명을 넣어준다.
- output_names: 모델의 output 변수명을 넣어준다.
- dynamic_axes: 변수들 중 동적인 차원들을 넣어준다. 예를 들어 배치값이나 문장의 길이 등이 동적인 부분이므로 미리 알려줘야한다.
Realtime Inferences BERT on Onnxrumtime
 export한 onnx 포멧을 onnxruntime 위에서 돌리기 위해 runtime class를 정의한다. 생성자함수에서 bert tokenizer와 onnxruntime sesstion을 정의해 predict함수에서 text를 받아 input형식으로 변환한 후 onnxruntime에서 결과값을 받아 리턴한다.
export한 onnx 포멧을 onnxruntime 위에서 돌리기 위해 runtime class를 정의한다. 생성자함수에서 bert tokenizer와 onnxruntime sesstion을 정의해 predict함수에서 text를 받아 input형식으로 변환한 후 onnxruntime에서 결과값을 받아 리턴한다.
이때 session option에 graph optimization level을 지정한다. onnxruntime에서는 graph optimization을 Basic, Extended, Layout Optimizations 3단계로 나눠 제공하며 윗 단계를 선택할 시 이전 단계들은 포함된다. 예를 들어 Extended로 설정하면 Basic, Extended가 포함되는 식이다. 자세한 사항은 관련 공식문서를 참고하길 바란다.
 pytorch로 돌렸을 때와 onnxruntime 돌렸을 때를 비교하기 위해 각각 추론 함수를 만들었다.
pytorch로 돌렸을 때와 onnxruntime 돌렸을 때를 비교하기 위해 각각 추론 함수를 만들었다.

정의한 onnxruntime 클래스를 정의하고 테스트 텍스트를 생성하고 100개 정도 복제해서 평균 추론 속도를 구했다. Colab GPU 환경에서 BERT 모델을 추론하는 성능을 비교해보니 onnxruntime이 2~3배 빠른 것을 확인했다.
Onnxruntime Transformer Graph Fusion
onnxruntime 실행시 session option으로 추가하는 Graph Optimization으로 딥러닝 모델을 최적화할 수 있지만 BERT, GPT와 같은 복잡한 구조 모델들을 모두 커버하지 못하여 transformer 기반 모델을 위한 추가적인 기능들이 따로 구성되어있다.
transformer optimizer는 onnxruntime에서 기본적으로 제공되는 graph optimization 3단계와 더불어 모델별 python 코드로 작성되어있는 최적화 함수로 맞춤형 최적화모듈을 제공한다. 함수인자 model_type에 모델 종류를 넣어준다.
(graoh optimization 먼저돌고 다음으로 transformer optimization이 돈다. 또한 모든 모델이 준비되어있지는 않다... bert, gpt 정도)

- input_path: 최적화할 모델 path
- model_type: bert 같은 모델 string으로 작성 (제공되는 모델 정보는 이곳 참고)
- num_head, hidden_size: 0으로 설정하면 모델에서 찾아 준다
- opt_level: onnxruntime이 기본적으로 제공하는 graph optimization level 설정.
- use_gpu: gpu에서 돌릴 때 이를 True로 해야 gpu를 서포팅하는 optization fusion을 사용할 수 있다.
