✔ 라우팅 알고리즘이란 송신 측에서부터 수신 측 라우터의 네트워크를 통과하는 최적의 경로를 결정하는 알고리즘이다.
Datagram case: 데이터를 전송하기 전에 set-up과정을 하지 않고 패킷을 독립적으로 전송한다.
Virtual circuit case: 데이터를 전송하기 전에 set-up과정을 하여 처음 패킷으로 최적의 경로를 탐색하고 그 경로를 통해서 패킷을 전송한다.
📌라우팅 알고리즘의 바람직한 특성
- Correctness(정확성)
- Simplicity(단순성)
- Robustness(견고성)
: 일부 라우터가 충돌할 때마다 모든 호스트의 모든 작업을 중단하고 네트워크를 재부팅하지 않고도 토폴로지 및 트래픽 변경에 대처하기 위해 - Stability(안정성)
- Fairness(공정성)
- Optimality(최적화)
: To minimize number of hops (최소화)
: To reduce the amount of bandwidth consumed (감소)
: To improve throughput as well and delay (개선)
하지만 공정성과 최적화 사이에는 갈등이 존재한다.
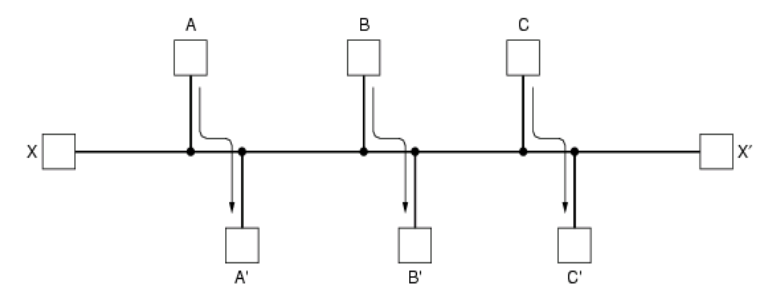 공정성 우선시: 1초에 X보내고, 1초에 A,B,C를 보내면 각각 한번씩 보내기에 공정하지만 2초에 4개, 즉 1초에 2개를 보내는 것만 가능하다.
공정성 우선시: 1초에 X보내고, 1초에 A,B,C를 보내면 각각 한번씩 보내기에 공정하지만 2초에 4개, 즉 1초에 2개를 보내는 것만 가능하다.
최적화 우선시: X를 보내지 않고 막으면 1초에 A,B,C를 보낼수 있음으로 1초에 3개를 보내는 것이 가능하다.
📌라우팅 알고리즘의 2가지 유형
-
정적 라우팅 알고리즘(Nonadaptive, Static) : 라우팅 테이블에 경로를 수동으로 추가해야하는 프로세스이다. 항상 같은 경로로만 패킷 라우팅 경로를 설정하고 유지한다.
● 장점: 관리자의 의도대로 제어가능, 경로 정보를 주고 받을 필요가 없어 효율이 높음
● 단점: 경로를 설정하고 유지하는데 공수가 듬, 적절한 경로 구현을 위해 관리자의 이해도가 필요, 네트워크 규모가 커지면 힘듬 -
동적 라우팅 알고리즘(Adaptive, Dynamic) : 인접한 라우터들 사이에서 라우팅 프로토콜을 이용하여 네트워크 정보를 상호교환하며, 라우팅 테이블을 상시 자동적으로 생성하고 유지하는 라우팅 방식이다. ex) RIP, OSPF, EIGRP
● 장점: 관리자의 설정유지를 위한 작업이 적음, 경로의 특성에 대한 정보를 주고 받아 상황에 따라 적합한 경로를 선택할 수 있음
● 단점: CPU, 메모리, 링크 대역폭등 자원을 사용 ->여러 정보를 가지게 되어 데이터 전송 속도가 느려짐
📌 라우팅 정보를 취하는 범위에 따른 2가지 유형
- 분산 라우팅 알고리즘: 이웃 노드와 정보를 교환하여 반복적이고 분산된 방식으로 수행하다.
거리 벡터 알고리즘 (Bellman-Ford)
- 글로벌 라우팅 알고리즘: 네트워크 전체에 대한 완벽한 정보가 필요하다.
링크 상태 알고리즘 (Dijkstra)
📌Optimality Principle
- optimality principle: 만약 라우터J가 라우터I에서 라우터K까지 가는 최적의 경로상에 존재한다면 라우터J에서 라우터K까지 가는 최적의 경로 또한 같은 루트이다.
- Sink tree: 모든 source에서 주어진 destination까지의 최적의 길을 세팅해둔 트리이다. 이는 Loop를 포함하면 안된다!

전공 소개