
📖 Introduction
-
프로젝트 개요 : 비지도 학습으로 강남구 내 특정 위치의 시설 밀집도를 분석하여 부동산과 도시개발에 대한 인사이트를 제공하고자 함.
-
기간 : 2023.06.30 – 2023.07.26
-
수행 역할 :
- Selenium, BeautifulSoup으로 담당 편의점 매장정보 데이터 크롤링
- Pandas로 담당 인허가 시설, 편의점 매장정보 데이터 전처리
- Folium으로 강남구 내 모든 시설별 분포 지도 시각화
- KMeans로 군집화 진행, 최적의 클러스터 선정
- 강남구 내 밀도 레벨별 지리적 특성 분석, 세부 정의
-
배운 점 :
① EDA 과정에서 전체 분석 방향에 대한 인사이트를 얻는 것에 대한 중요성을 체감.
② 머신러닝 학습을 수행하기 위해 학습이 가능한 형태로 데이터 수집, 전처리하는 과정에서 부단히 고민하여 유의미한 결과를 도출해낼 수 있었음.
③ 비지도 학습으로 더욱 정교한 분석 결과를 도출하기 위해서 EDA, 지도 학습 등 다양한 방법을 강구하였음.
🔧 Problem definition
- 목표 : 비지도 학습으로 강남구 시설 밀집도를 분석하여 부동산과 도시개발에 대한 인사이트 제공
📝 Result
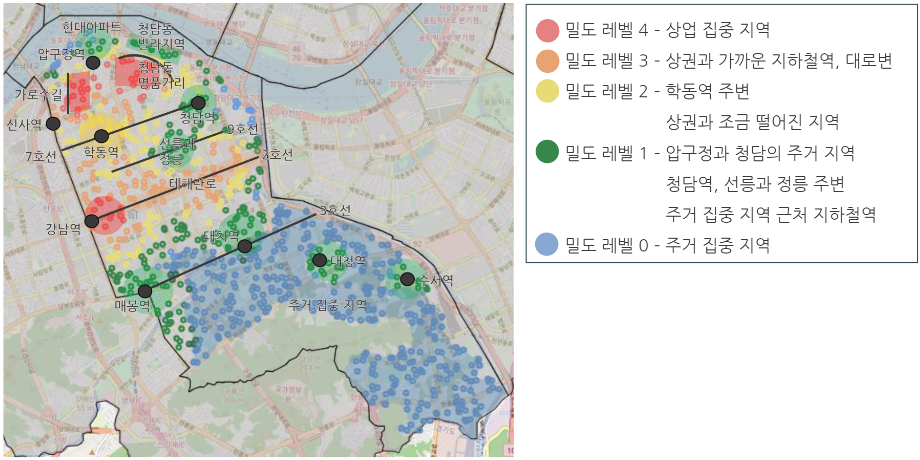
- 밀도 레벨을 구분하여 시설 밀집도가 높은 곳과 낮은 곳을 다섯 단계로 구분.
🤖 Modeling
(1) 폴리곤 바운더리 활용하여 강남구 내 랜덤 좌표 추출
- 강남구 내 850개에서 950개의 랜덤 좌표를 사용
- 폴리곤 바운더리로 랜덤 좌표 중 강, 산 부분을 제외
(2) 랜덤 좌표 기준 반경 500m 내 시설별 개수 추출, 전처리
- 랜덤 좌표를 기준으로 반경 500m 내 편의시설별 개수를 추출
- 위경도를 제외한 좌표별 시설 개수를 피처로 사용
(3) 군집화(KMeans)
- 클러스터 5개로 나누었을 때가 가장 적절하다 판단.
(4) 클러스터별 밀도 레벨 구분 – 평균값, 중위값 활용
- 평균값과 중위값을 기준으로 밀도가 높은 클러스터를 선별
💡 EDA & Insight
(1) 밀도 레벨별 특성
(2) 강남구 인구 대비 시설 수의 군집화
- 강남역 주변: 밀도 감소
- 수서역 주변: 밀도 증가
(3) 지하철역의 밀도 레벨과 주변 시설, 승객 수
- 지하철역 승객 수가 높을 수록 밀도 레벨이 높은 경향
🪅 Toy service
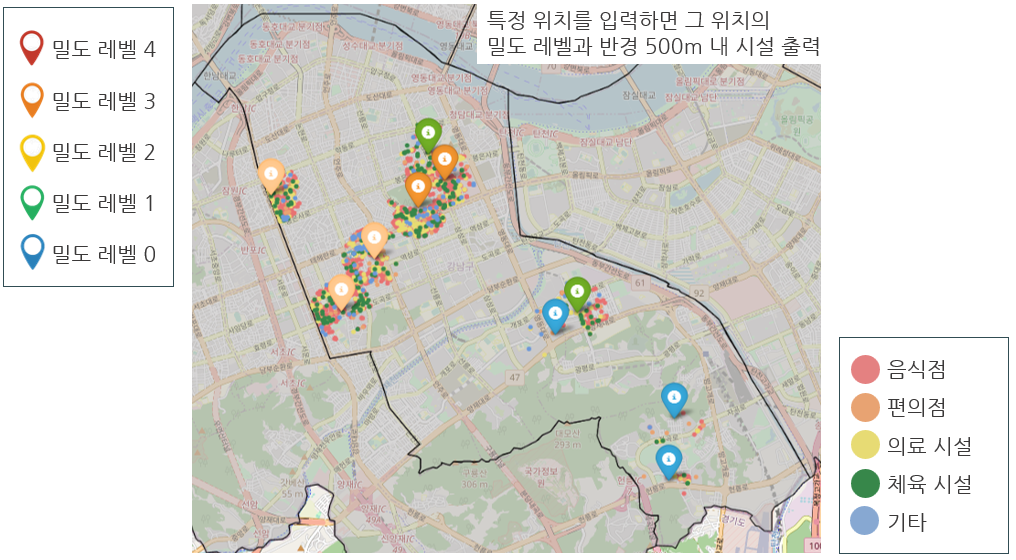
(1) 특정 좌표 입력하면 밀도 레벨과 근거리 시설 출력
(2) 지하철역 주변 밀도 레벨과 근거리 시설 출력
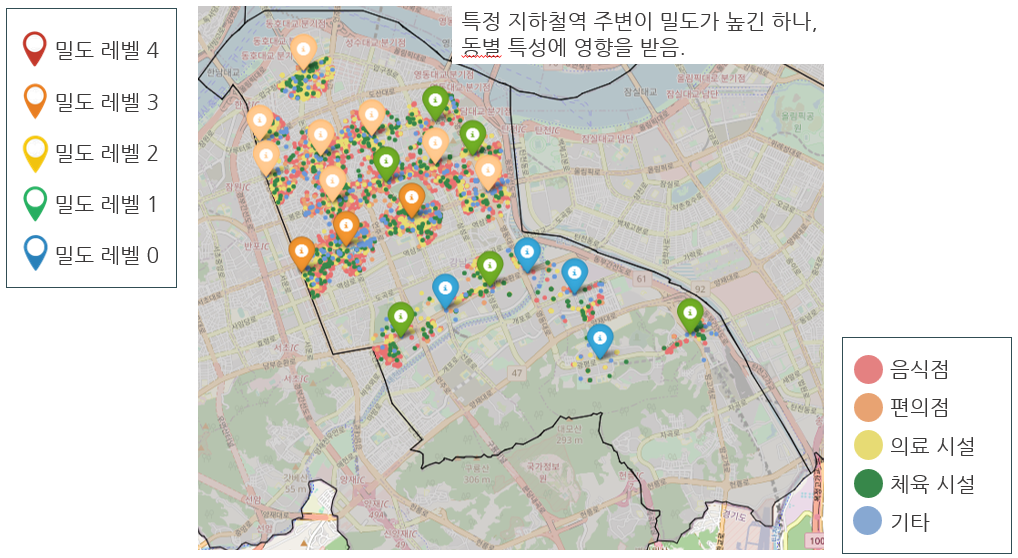
➡️ 특정 좌표와 지하철역 주변 밀도 레벨과 시설 수로 부동산, 도시 개발을 위한 정보 제공

데이터 꿈나물