
📖 Introduction
- 프로젝트 개요 : 최근 편의점, 무인점포 내 범죄행위 건수의 증가에 따라 RNN 계열 딥러닝을 활용한 실내 절도행위 탐지 모델을 개발하여 범죄 예방에 기여하고자 하였음.
-
기간 : 2023.08.14 – 2023.09.06
-
수행 역할 :
- MoviePy로 raw 데이터 전처리 (영상 추출 및 병합)
- OpenCV, MediaPipe로 영상 데이터의 Skeleton 전처리
- PyTorch로 학습된 모델 최적화
- 다양한 조건으로 학습 실험 후 최종 모델 선정
-
배운 점 :
① 컴퓨터 비전 분야 프레임워크로 이상탐지를 위한 LSTM 모델을 개발하며 RNN 계열 딥러닝에 대한 이해도를 높임.
② Pytorch를 통해 pretrained YOLOv5 모델을 객체탐지에 활용.
🔧 문제 정의
-
문제 인식 : 편의점, 무인점포 내 범죄행위가 해를 거듭할수록 증가.
-
목표 : 실내(편의점, 무인점포) 절도행위 탐지 모델을 개발하여 범죄 예방에 기여.
📎 데이터 소개와 전처리
-
AI-Hub의 실내(편의점, 매장) 사람 이상행동 데이터에서 절도행위만 선별하여 사용.
-
전처리 과정
-
Clip 추출

➡️ 1분(180fps)의 영상에서 정상행동과 이상행동을 50:50 비율로 10초(30fps) Clip 추출.
➡️ 각 Clip은 시퀀스별 학습에 사용. -
Clip 병합
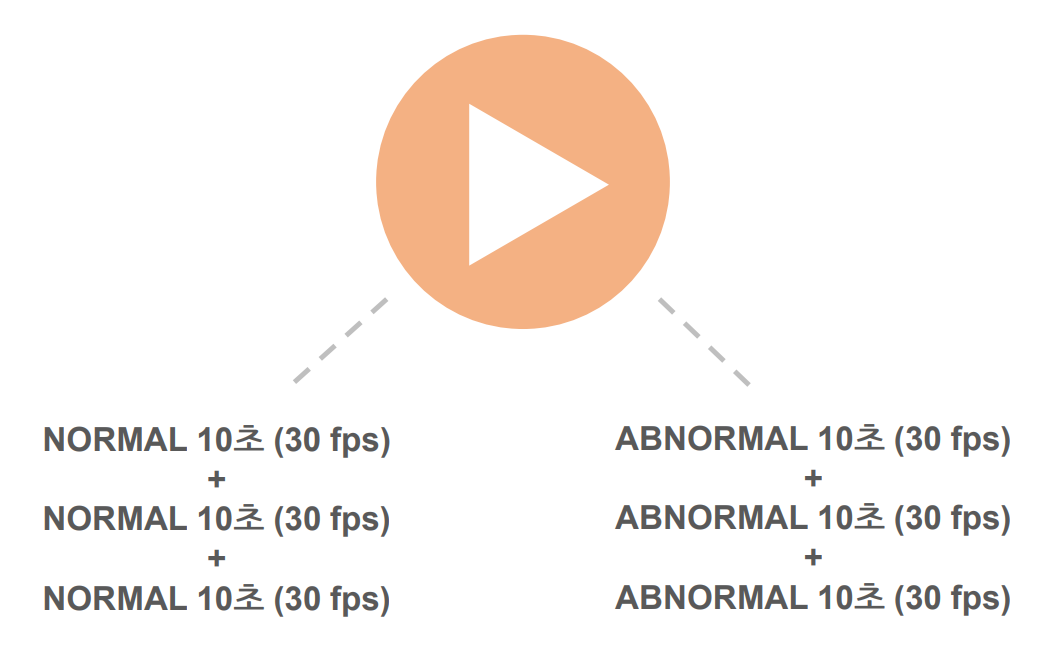
➡️ 추출한 각 클립을 병합하여 정상행동, 이상행동만 반복해서 나타나는 병합 Clip을 생성.
➡️ 시퀀스 묶음별 학습에 사용. -
MediaPipe
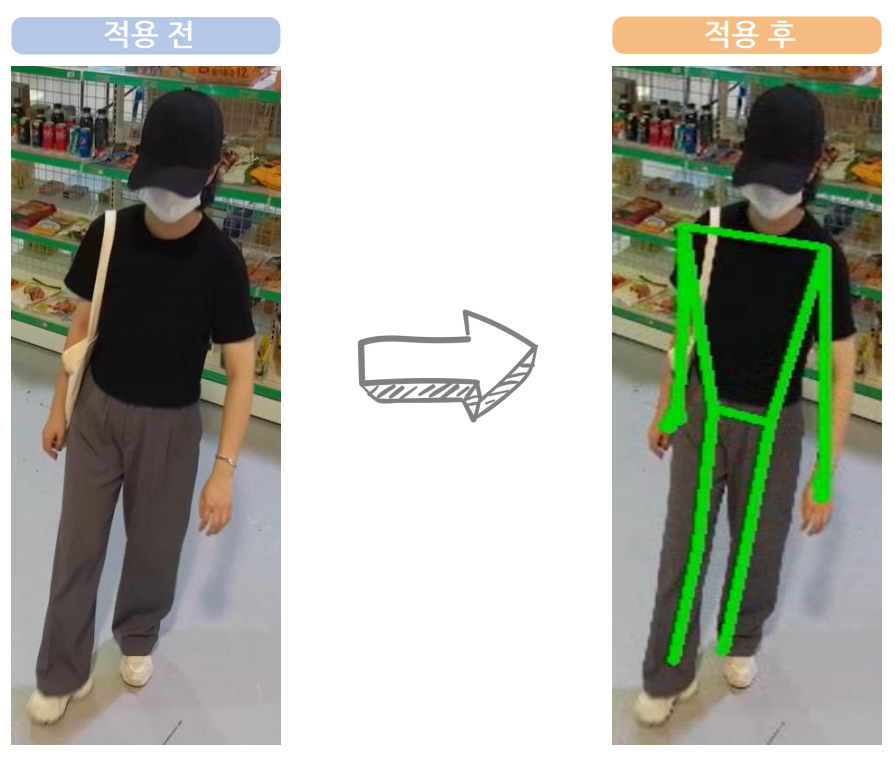
➡️ Google의 MediaPipe 활용하여 얼굴과 몸에 해당하는 Landmark의 x, y 좌표를 추출.
➡️ Landmark의 행동 패턴을 모델에 학습.
🤖 모델링
- 사용한 프레임워크
- 사용환경 : Colab, Visual Studio
- 딥러닝 프레임워크 : MediaPipe, Pytorch, YOLOv5, OpenCV
-
모델 선정 - LSTM
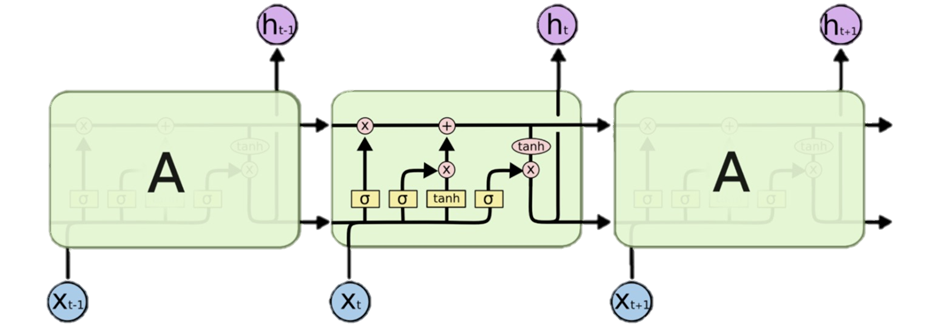
➡️ Simple RNN에서 Cell state를 추가하여 Time step을 가로지르며 셀 상태가 보존됨. 기존의 장기 의존성(Long term depency)를 효과적으로 해결.
➡️ 시간 흐름에 따른 행동 패턴을 학습하기에 적절한 모델로 생각하여 LSTM 모델을 최종 선정하였음. -
단계별 비교 분석
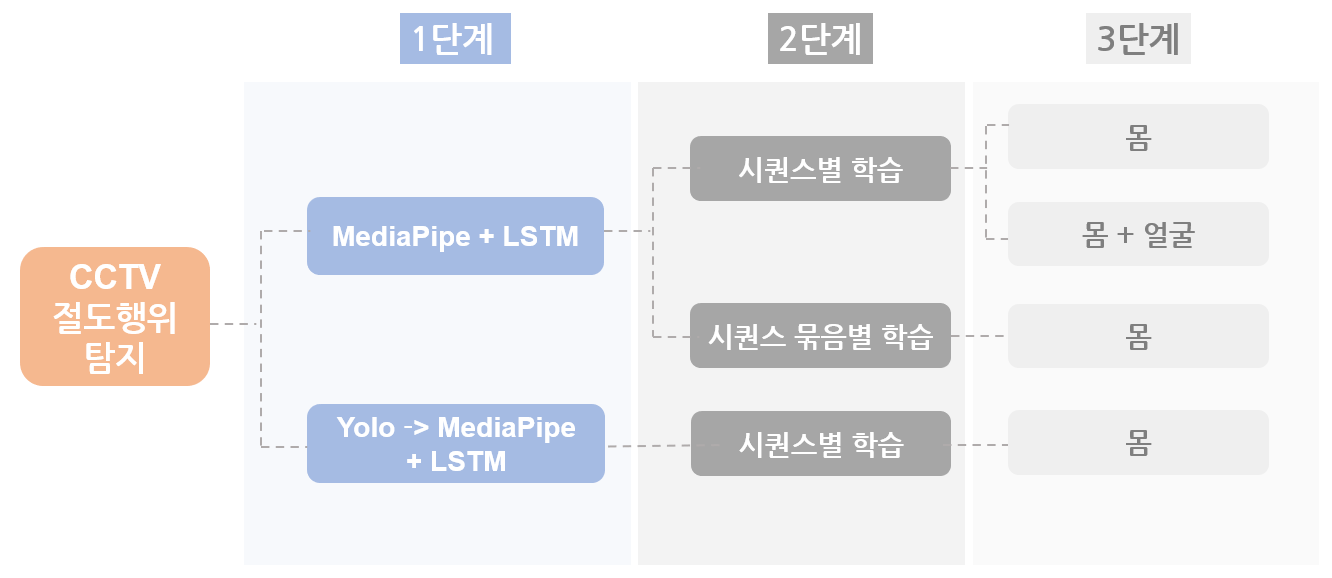
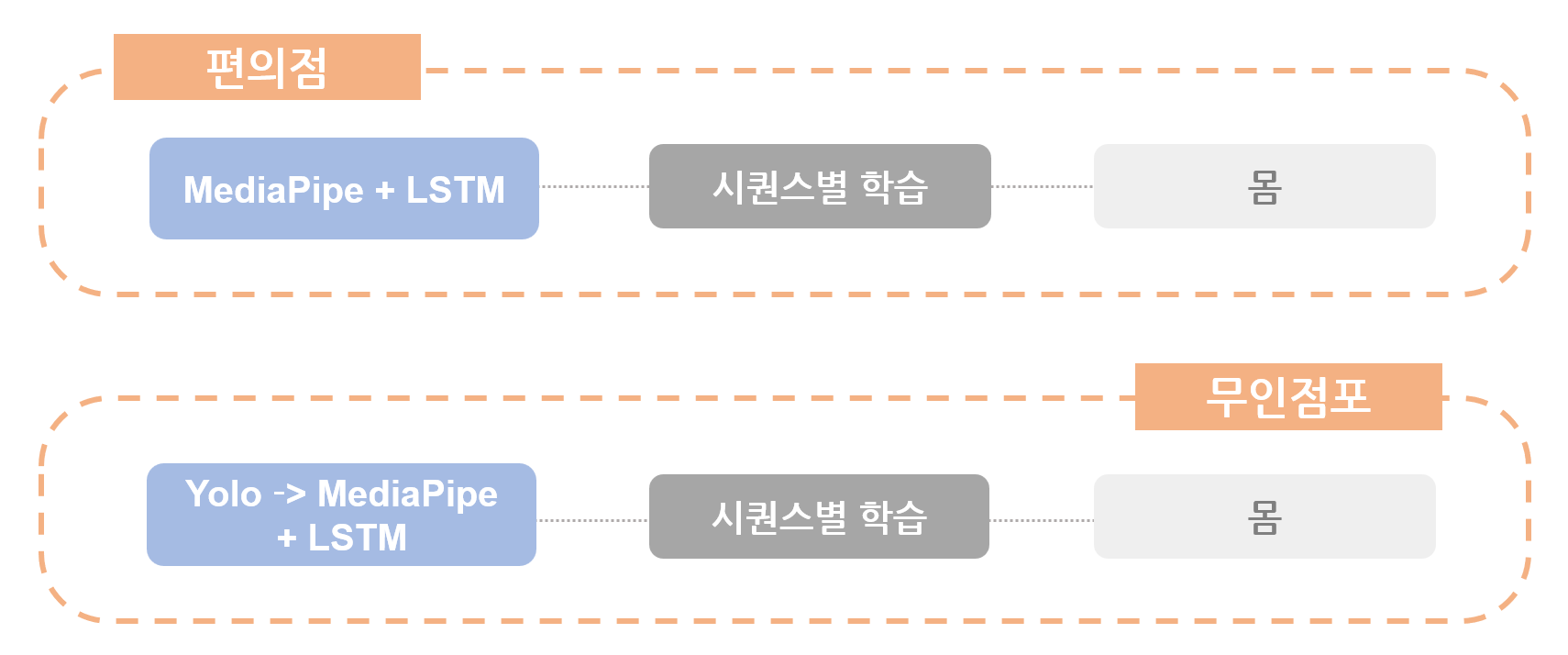
- 1단계: MediaPipe의 패턴에서 바로 이상탐지를 한 경우와 YOLOv5로 객체탐지 후 패턴의 이상탐지를 한 경우의 결과 비교.

🤔 문제점: YOLO를 미적용했을 때 MediaPipe가 사람이 아닌 사물을 잘못 인지하는 경우가 발생
💡 해결: YOLO로 객체탐지를 우선적으로 하고 그 범위 내에서 MediaPipe가 Landmark 형성
➡️ 그러나 무인점포가 아닌 편의점 상황에서 YOLO로 객체탐지를 하는 경우, 오히려 다중 객체를 탐지함으로써 모델 학습이 제대로 되지 않는 경우가 발생했음. 하여 최종적으로 YOLO 객체탐지는 무인점포 상황에서만 활용하기로 결정.
- 2단계: 추출한 Clip만으로 시퀀스별 학습을 했을 경우와 Clip을 병합하여 시퀀스 묶음별 학습을 했을 경우의 결과 비교.

➡️ 시퀀스별 학습을 했을 경우 탐지의 정확성이 더 좋음. 시퀀스 묶음별 학습을 했을 경우 오히려 오탐지를 하는 경우 발생. 최종적으로 시퀀스별 학습을 하기로 결정.
- 3단계: MediaPipe로 Landmark를 몸만 했을 경우와, 얼굴+몸을 했을 경우 결과 비교.

➡️ 얼굴 Landmark를 추가했을 때 이상탐지가 더 잘 이루어질 것으로 예상했으나 오히려 결과가 좋지 않았음. 몸 Landmark만 활용하기로 결정.
- 상황별 모델링 최종결과
🪄 기대 효과
-
탐지 자동화로 보안 강화 : 편의점, 무인점포의 CCTV를 통해 범죄행위를 자동 탐지함으로써 보안을 강화할 수 있음.
-
실시간 탐지로 신속한 조치 : 실시간 데이터 스트림을 다루는 데 용이한 LSTM 모델을 활용해 범죄행위 발생 시 사용자가 즉각적으로 조치할 수 있음.
-
보안 인력 최소화로 비용 절감 : 보안을 위한 인적 자원을 배치하지 않음으로써 인력 비용을 절감할 수 있음.
-
매장 이용에 대한 서비스 품질 향상 : 사용자는 보안 시스템 자체보다 매장 운영에 집중함으로써 결과적으로 서비스 품질 향상을 야기할 수 있음.
-
학습량 누적에 따라 탐지 성능 향상 : 딥러닝 모델이 시스템 내에서 다양한 상황과 행동 패턴을 학습할 수 있기 때문에 사용량이 늘어날수록 이상탐지 성능의 향상됨.
+) 추후 개선 방향
단일 객체의 이상행동 데이터를 기준으로 모델링 했기 때문에 다중 객체의 이상행동 탐지에 한계 존재. Multi object detection과 Object tracking을 결합하여 다중 객체에 대한 탐지 성능도 높일 수 있음.
