Overview
Instruction-following 모델:
단순히 다음 단어 예측이 아니라, 사람의 의도를 파악하려고 학습됨.
예: “이 문장을 한국어로 번역해줘” → 번역 결과를 출력.
즉, 사람의 지시를 task로 이해하고 수행.
instruction-following 모델(ex: GPT-3.5, ChatGPT, Claude, Bing Cha)은 점점 발전중이며 많은 사람들이 사용중. 그러나 여전히
1) 거짓 정보를 생성하거나,
2) 사회적 고정관념을 퍼뜨리거나,
3) 유해 언어를 만들어낼 수 있는
등의 한계 존재.
이러한 한계점을 개선하기 위해 나온 모델이 Alphaca
📌 기반 모델: Meta의 LLaMA 7B
📌 학습 데이터: text-davinci-003을 활용해 self-instruct 방식으로 생성한 52K 지시 시연 데이터
📌 특징: 작은 규모이지만, OpenAI text-davinci-003과 유사한 성능을 보임
📌 장점: 재현이 쉽고 비용이 저렴
Alpaca는 학술 연구 전용으로만 사용 가능하다.
Training recipe
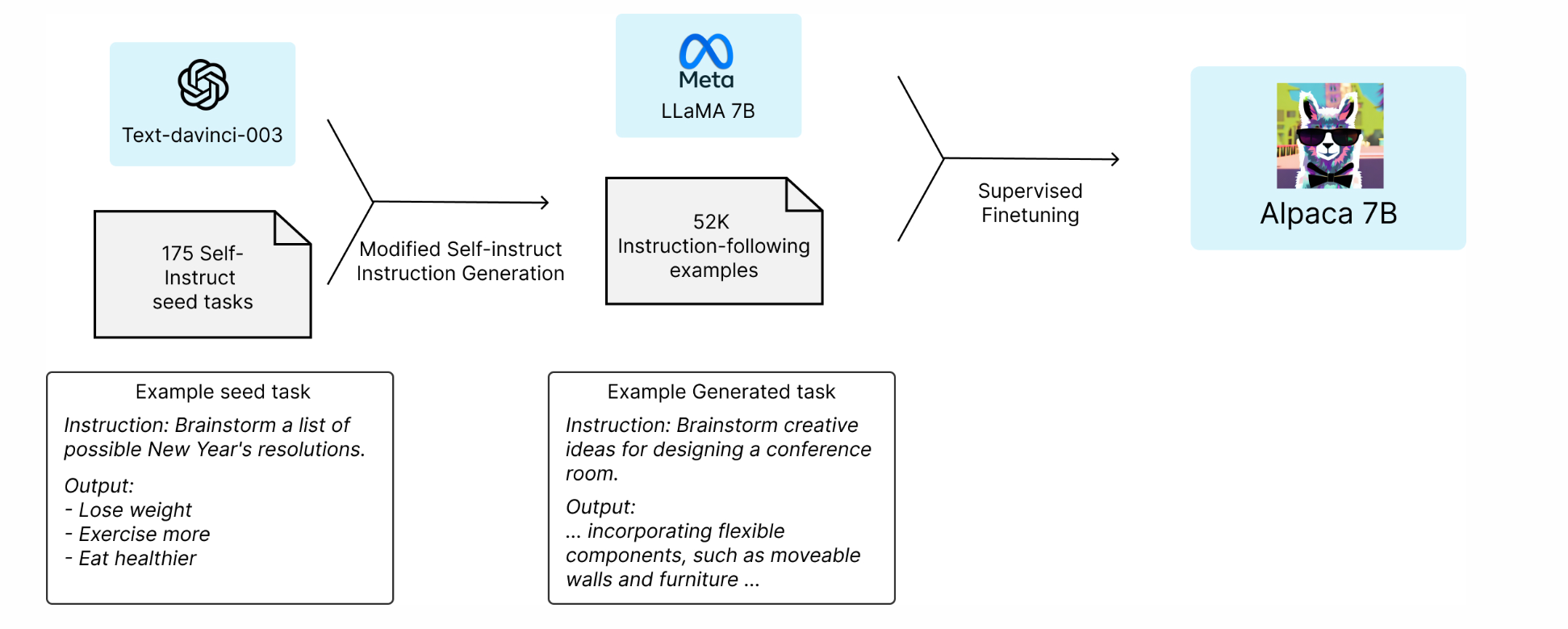
1). OpenAI의 text-davinci-003 모델을 활용해서 학습 데이터셋을 생성
- 시작점은 175개의 Self-Instruct seed tasks (즉, 초기 예시 과제들).
2). 데이터 증강: Modified Self-Instruct 방식
175개만으론 부족하니까, text-davinci-003에게 이 seed를 바탕으로 instruction-following 예제들을 대량 생성시킴.
그 결과 → 52,000개의 instruction-following examples 확보.3). 학습 모델: Meta LLaMA 7B
Meta가 공개한 기본 모델 LLaMA 7B를 사용.
이 모델은 원래는 instruction following을 못하는데, 위에서 만든 52K 예제 데이터로 학습시킨 것.Supervised Finetuning 과정을 거쳐서, LLaMA 7B가 사람 지시를 잘 따르도록 만듦.
4). 완성된 모델이 바로 Alpaca 7B.
고품질의 instruction-following 모델을 학술 예산 안에서 학습시키려면 두 가지 중요한 과제가 있다.
1). 강력한 사전학습 언어 모델
-> 최근 Meta에서 공개한 새로운 LLaMA 모델로 해결
2). 고품질 instruction-following 데이터
-> self-instruct
Self-Instruct 방법
- 기존에 사람이 만든 175개의 instruction-output 쌍(seed set)을 준비.
- 이걸 in-context 예시로 넣고 OpenAI text-davinci-003에게 “비슷한 instruction 더 만들어줘!”라고 시킴.
- 데이터 생성 파이프라인을 단순화 → 비용 절감.
최종 결과:
- 52K 고유 instruction-output 쌍 확보
- 생성 비용: 500달러 미만 (OpenAI API 기준)
모델 학습 (Fine-tuning)
확보한 52K 데이터를 활용해 LLaMA 7B 모델을 파인튜닝.
활용 기술:
FSDP: 모델 파라미터를 GPU 여러 개에 쪼개 담아 메모리 효율적으로 학습.
Mixed Precision: FP16 + FP32 혼합으로 빠르고 가볍게 학습.
학습 세부사항:
- GPU: 8 × 80GB A100
- 시간: 약 3시간
- 비용: 100달러 미만 (클라우드 기준)
Preliminary evaluation
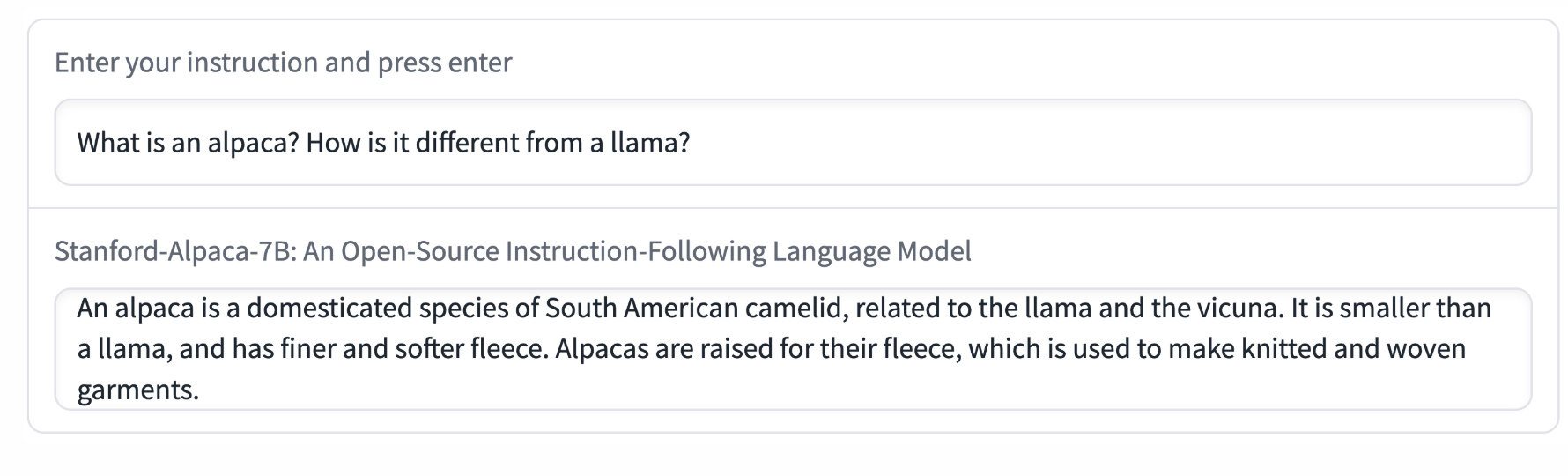
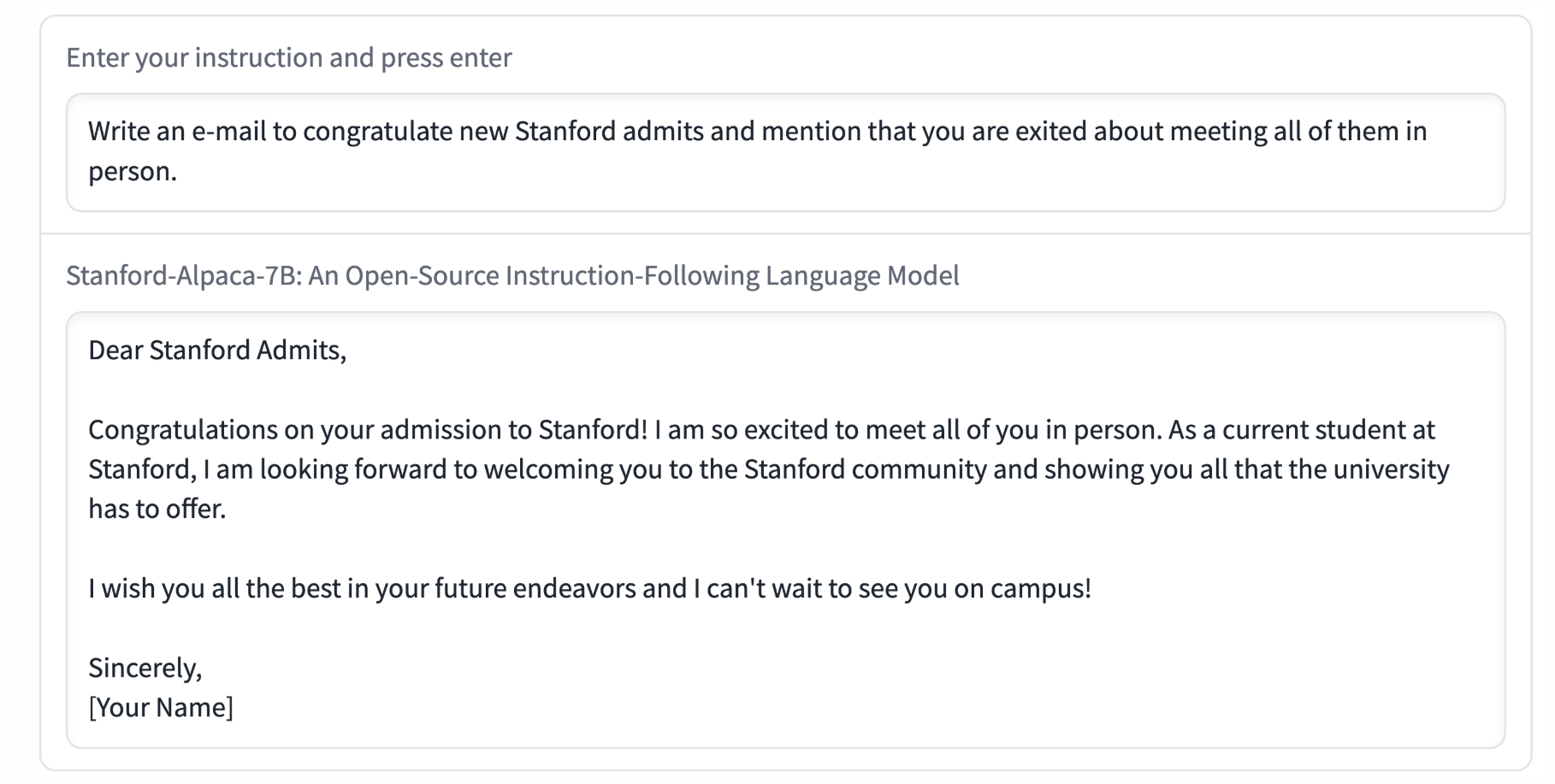
논문 저자인 학생 5명이 self-instruct 평가 세트의 입력을 대상으로 평가 진행
(이메일 작성, 소셜 미디어, 생산성 도구 등 포함)
text-davinci-003과 Alpaca 7B를 대상으로 블라인드 쌍별 비교 수행
-> Alpaca가 text-davinci-003에 대해 90 대 89로 승리
Alpaca는 작은 모델 크기(7B) + 52K instruction 데이터만 사용했음에도 불구하고 GPT-3.5에 가까운 결과 달성
1. 탄탄한 기반: LLaMA 7B
Alpaca의 바탕은 Meta의 LLaMA 7B.
LLaMA 자체가 같은 크기 모델 중 성능 최상급으로 설계되어 있음
즉, 작은 파라미터 수에도 불구하고 언어 이해와 추론 능력이 이미 강력2. 데이터 품질
52K 데이터는 그냥 크롤링 텍스트가 아니라, OpenAI text-davinci-003(GPT-3.5)이 직접 생성한 고품질 instruction-output 쌍
데이터의 질이 수량 부족을 보완
3. Instruction-tuning 효과
원래 LLaMA는 그냥 언어모델이라서 “다음 단어 예측”만 잘함.
Alpaca는 instruction-following 데이터로 파인튜닝했기 때문에
→ 사람의 지시(질문, 명령)에 맞게 반응하도록 바로 적응.4. 효율적인 학습 기법
FSDP + Mixed Precision Training 덕분에 짧은 시간, 저비용에도 안정적으로 학습 가능.
출력은 전반적으로 깔끔하고 잘 작성됨.다만, 데이터셋 스타일을 그대로 반영하기 때문에 답변이 ChatGPT보다 짧음
이는 text-davinci-003의 짧은 출력 스타일을 따른 것.
연구팀은 정적 평가 세트 외에도 Alpaca 모델을 상호작용적으로 테스트했다. 그 결과, Alpaca가 여러 입력 집합에서 text-davinci-003과 유사하게 동작한다는 것을 확인했다.
다만, 이번 평가가 규모와 다양성 면에서 한계가 있다는 점을 인정하고, 이를 보완하기 위해 Alpaca interactive demo를 공개하여 사용자가 직접 모델을 시험해보고 피드백을 제공할 수 있도록 했다.
Known Limitations
Alpaca도 다른 언어모델들과 마찬가지로 여러 한계를 보임.
(환각,고정관념 등..)
특히, 환각은 text-davinci-003보다 더 자주 나타나는 대표적 실패 사례로 꼽힘.
ex)
탄자니아 수도 오류
Alpaca는 수도를 Dar es Salaam이라고 답했지만, 실제 수도는 Dodoma.
Alpaca는 글 자체는 유창하게 쓰지만, 때때로 잘못된 사실을 자연스럽게 전달해버린다.
그럼에도 불구하고 Alpaca는 여전히 의미 있음. 비교적 가벼운 모델로, 언어모델의 중요한 결함을 연구할 수 있는 기초 자료 제공.
이는 사용자 피드백(웹 데모에서 오류 신고)을 통해 새로운 실패 유형을 발견하고 개선 가능하다.
