0. ABSTRACT
이 논문은 언어 모델의 제로샷 학습 능력을 향상시키는 간단한 방법을 탐구한다.
이 논문은 instruction tuning(지시문 튜닝) — 즉, 여러 데이터셋을지시문을 통해 파인튜닝하는 방식 — 이 보지 못한 과제들에 대한 제로샷 성능을 크게 향상시킨다는 것을 보여준다.
- 모델: 137B 파라미터 언어 모델
- 데이터: 60개 이상의 NLP 데이터셋
- 튜닝 방식: 각 데이터셋을 “자연어 지시문 템플릿” 형태로 변환
- 결과 모델: FLAN
25개 평가 데이터셋 중 20개에서 GPT-3(175B)보다 높은 제로샷 성능을 가짐.
추가적인 실험 결과, 성공의 핵심 요인은 다음 세 가지임이 밝혀졌다:
1️⃣ 미세조정에 사용된 데이터셋의 다양성과 수,
2️⃣ 모델의 규모,
3️⃣ 그리고 자연어 형태의 지시문 사용.
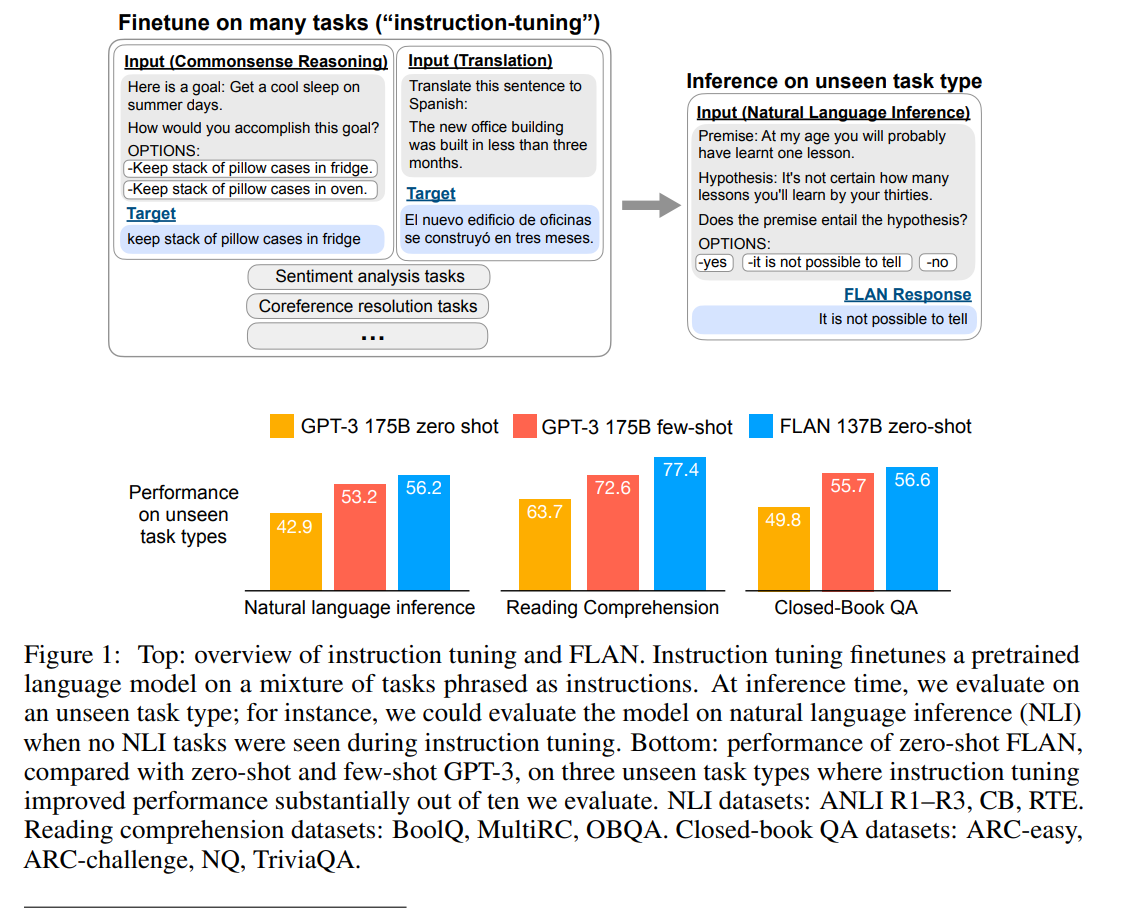
Figure 1.
여러 NLP 과제를 모두 자연어 지시문 형태로 변환해 학습함.
예시:
- "Get a cool sleep on summer days. How would you accomplish this goal?"
- "Translate this sentence to Spanish."
이런 식으로, 각 과제마다 사람이 말하듯 문장 형태로 문제를 제시함.
이를 통해 추론 과정에서는 학습에서 한 번도 본 적 없는 새로운 유형의 과제에 대해 모델이 지시문만 보고 답을 생성함.
→ 예: “Does the premise entail the hypothesis?” → It is not possible to tell.
즉, 여러 과제를 자연어로 학습시키면, 새로운 과제도 자연스럽게 이해해 풀 수 있는 모델이 된다는 걸 보여줌. 또한 FLAN이 GPT-3보다 작음(137B vs 175B)에도 불구하고 모든 항목에서 제로샷 기준으로 GPT-3을 능가한다는 것을 보여준다.
INTRODUCTION
GPT-3와 같은 대규모 언어모델은 few-shot learning에서는 높은 성능을 보이나 제로샷에서는 그만큼의 성능을 내지 못한다.
그 이유 중 하나는, few-shot 예시가 주어지지 않으면 모델이 사전학습 데이터의 형식과 유사하지 않은 프롬프트에 대해 제대로 작동하기 어렵기 때문일 수 있다.
따라서 본 논문에서는 제로샷 성능을 높이기 위한 방법으로 '지시문 튜닝'을 활용했다.
Instruction tuning은 pretrain–finetune 방식과 prompting 방식의 장점을 결합한 간단한 방법이다.
이는 파인튜닝을 통해 언어 모델이 추론 시점의 텍스트 입력에 더 잘 반응하도록 만든다.
이는 언어 모델이 순수히 자연어 지시문만으로 주어진 과제를 수행할 수 있는 잠재력을 보여준다.
또한 추가적인 실험 결과,
- instruction tuning에 포함되는 과제의 다양성을 늘릴수록 보지 못한 과제에서의 성능이 향상되며,
- instruction tuning의 효과는 충분히 큰 모델 규모에서만 나타난다는 점이 밝혀졌다.
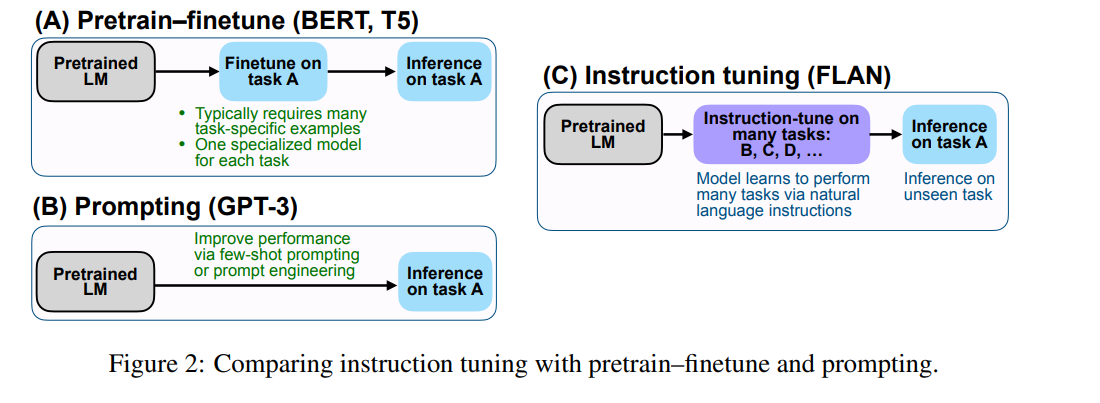
| 방식 | 예시 모델 | 특징 | 한계 |
|---|---|---|---|
| (A) Pretrain–Finetune | BERT, T5 | 각 과제별로 따로 파인튜닝 | 과제마다 모델 따로 필요 |
| (B) Prompting | GPT-3 | 예시나 프롬프트로 직접 유도 | 제로샷에 약함, 프롬프트 민감 |
| (C) Instruction Tuning | FLAN | 여러 과제를 지시문으로 학습 → 새로운 과제도 수행 | 대형 모델 필요 |
2 FLAN: INSTRUCTION TUNING IMPROVES ZERO-SHOT LEARNING
지시문 튜닝의 목적은 언어 모델이 NLP 지시문을 더 잘 이해하고 따르게 만드는 것이다. 여러 과제를 지시문 형태로 학습시키면, 모델이 보지 못한 과제도 지시문만 보고 수행할 수 있게 된다.
이를 평가하기 위해 과제 유형별로 데이터를 묶고, 한 클러스터를 제외한 나머지로 학습해 성능을 검증했다.
2.1 TASKS & TEMPLATES
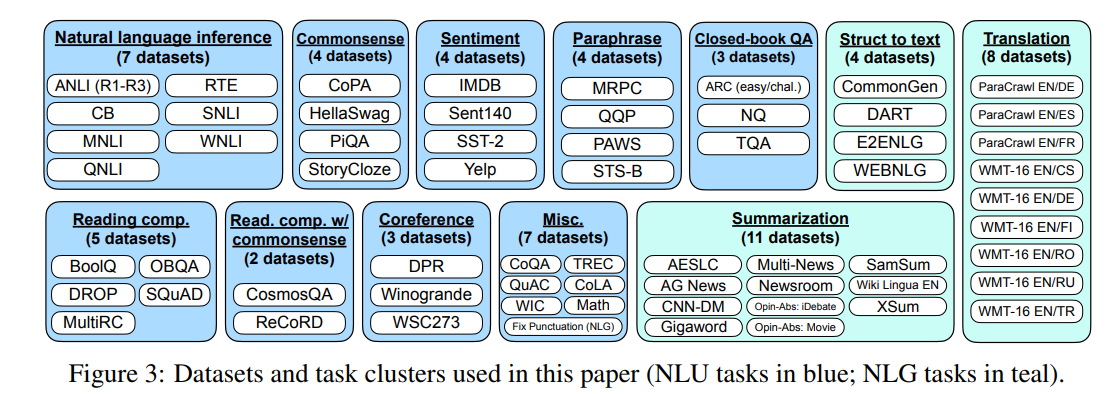
다양한 과제를 포함한 지시문 튜닝용 데이터셋을 처음부터 새로 만드는 것은 많은 자원과 시간이 필요하기 때문에, 본 논문에서는이미 공개된 기존 데이터셋들을 지시문 형식으로 변환하였다.
이를 위해 TensorFlow Datasets에 공개되어 있는 62개의 텍스트 데이터셋을 수집하여, language understanding와 language generation 과제를 모두 포함하는 하나의 혼합 데이터셋으로 통합하였다.
각 데이터셋은 12개의 과제 클러스터 중 하나에 속하며 같은 클러스터 내의 데이터셋들은 동일한 과제 유형을 가진다.
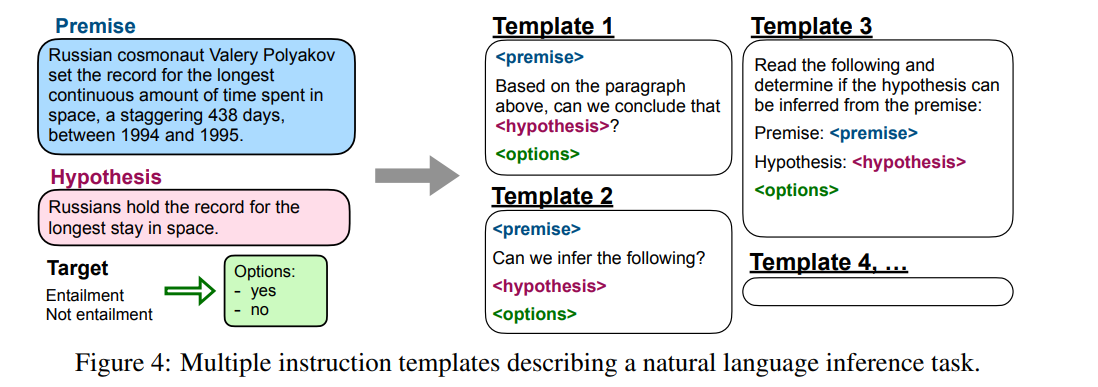
Figure 4: 하나의 과제를 여러 문장 템플릿으로 다양하게 표현
각 데이터셋마다, 해당 과제를 지시문으로 설명하는 10개의 고유한 템플릿 을 직접 작성하였다.
| 종류 | 예시 |
|---|---|
| 원래 문장 | “이 리뷰의 감정은 긍정인가 부정인가?” |
| 템플릿 1 | “이 문장의 감정이 어떤지 말해줘.” |
| 템플릿 2 | “이 리뷰가 긍정적인지 부정적인지 판단해봐.” |
| 템플릿 3 | “이 영화 리뷰는 좋았을까, 나빴을까?” |
| 템플릿 4 | “긍정인지 부정인지 한 단어로 대답해.” |
| … | (이런 식으로 10개) |
10개의 템플릿 중 대부분은 원래의 과제를 그대로 설명하지만, 다양성을 높이기 위해, 각 데이터셋마다 최대 3개의 “반전된 형태의 템플릿” 도 포함시켰다.
ex)
- 원래 과제: “이 리뷰는 긍정인가 부정인가?”
- 반전 템플릿: “긍정적인 영화 리뷰를 하나 써봐.”
모든 과제를 하나로 합친 통합 데이터셋으로 모델을 지시문 튜닝했고, 각 데이터셋 예시는 매번 랜덤한 지시문 템플릿을 골라서 모델이 다양한 표현의 명령을 이해하도록 학습시켰다.
2.2 EVALUATION SPLITS
FLAN이 지시문 튜닝에서 unseen 과제에 대해 얼마나 잘 수행하는지는 중요한데, 이때 무엇을 unseen 과제로 설정할 것인지가 중요하다.
기존에는 같은 데이터셋이 학습에 포함되지 않으면 그걸 unseen task로 간주하였는데 FLAN 방식은 좀 더 보수적으로 어떤 과제가 속한 클러스터 전체가 학습에서 빠져야 한다고 설정한다.
예를 들어, 데이터셋 D가 자연어 추론 과제라면,지시문 튜닝에는 어떤 자연어 추론 데이터셋도 포함되지 않고, 대신 다른 모든 클러스터(예: 감정분석, 번역, 요약 등)만 사용해 학습한다.
따라서, c개의 과제 클러스터에 대해 제로샷 성능을 평가하려면,각 클러스터를 하나씩 제외하고 학습한 c개의 서로 다른 모델을 각각 학습시켜 평가해야 한다.
2.3 CLASSIFICATION WITH OPTIONS
FLAN은 디코더 전용 언어 모델 을 지시문 튜닝한 버전이기 때문에,자연스럽게 자유 형식의 텍스트 로 응답을 생성한다. 따라서 생성 과제에는 추가적인 수정이 필요하지 않다.
한편, 분류 과제의 경우, 이전 연구에서는 순위 분류 방식을 사용했다.
예: 가능한 답이 “yes” / “no” 두 가지일 때
→ 모델이 각 단어에 부여한 확률 중 더 높은 쪽을 예측 결과로 선택
하지만 이 방식에는 “yes”를 표현할 수 있는 다양한 단어들(예: yeah, yep, sure) 때문에 정답의 확률이 여러 단어로 분산되어 낮게 계산될 수 있다는 한계가 있다.
따라서 이에 대한 해결책으로 options suffix 를 추가했다.
즉, 분류 과제를 모델에 입력할 때, 문장 끝에 OPTIONS라는 토큰과 함께 가능한 정답 후보 목록을 명시적으로 붙인다.
이 방식은 모델이 어떤 답변 형태를 선택해야 하는지를 명확히 인식하도록 돕는다.

2.4 TRAINING DETAILS
1) 모델 구조 (Model Architecture & Pretraining)
- 기반 모델: LaMDA-PT
→ 137B(1,370억) 파라미터를 가진 디코더 전용 트랜스포머 언어 모델
-
사전학습 데이터:
웹 문서
대화 데이터(dialog data)
위키피디아(Wikipedia) -
토크나이징:
SentencePiece
2.49조(BPE) 토큰, 어휘 수 32k
비영어 데이터: 약 10% 포함
2). 지시문 튜닝 (Instruction Tuning Procedure)
- 튜닝 대상: LaMDA-PT
모든 데이터셋을 무작위로 섞어 학습
데이터셋별 최대 30,000개 예시만 사용
데이터 크기 비율에 따라 혼합 — 최대 mixing rate 3k
3. RESULTS
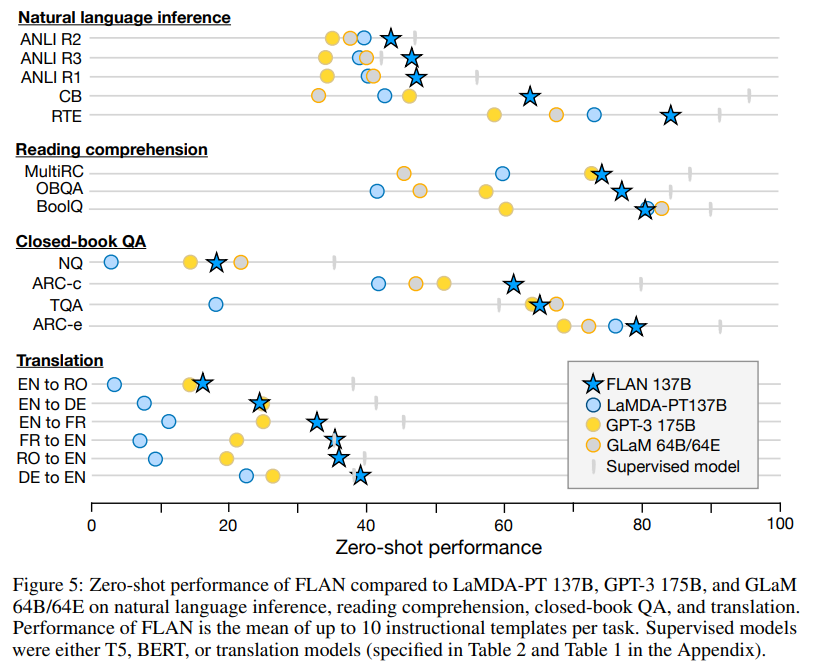
FLAN은 다음 7가지 과제 유형 에서 성능을 평가함:
- 자연어 추론 (NLI)
- 독해 (Reading Comprehension)
- 비문맥 질의응답 (Closed-book QA)
- 번역 (Translation)
- 상식 추론 (Commonsense Reasoning)
- 지시어 해석 (Coreference Resolution)
- 구조→문장 생성 (Struct-to-Text)
평가 시, 각 과제 유형을 하나씩 제외 하여 unseen task 성능을 측정.
전반적 결과 요약
| 비교 대상 | 결과 요약 |
|---|---|
| LaMDA-PT vs FLAN | Instruction tuning 후 대부분의 데이터셋에서 성능 대폭 향상 |
| GPT-3 (175B) | 25개 중 20개 데이터셋에서 GPT-3 제로샷보다 우수 10개에서는 GPT-3 few-shot도 능가 |
| GLaM (64B/64E) | 19개 중 13개 제로샷 성능 우수 19개 중 11개에서는 원샷(one-shot) GLaM 초과 |
Instruction tuning은 특히 지시문 형태로 표현 가능한 과제(NLI, QA, Translation 등) 에서 매우 효과적이었다.
반면, 문장 완성형 과제(Commonsense Reasoning, Coreference Resolution)에서는 효과가 제한적이었다.
과제별 주요 결과
자연어 추론 (NLI)
- 전제(premise)와 가설(hypothesis) 간의 의미 관계를 판단하는 과제.
- FLAN은 GPT-3, LaMDA-PT 등 모든 기준 모델을 큰 폭으로 능가.
- NLI 문장을 “Does
<premise>mean that<hypothesis>?”처럼
자연스러운 질문 형태로 표현하여 성능 향상.
독해 (Reading Comprehension)
- 주어진 지문을 읽고 질문에 답하는 과제.
- MultiRC, OBQA에서 기준 모델보다 우수.
- BoolQ에서도 GPT-3보다 훨씬 높은 성능.
(LaMDA-PT도 강했지만 FLAN이 더 뛰어남)
비문맥 질의응답 (Closed-book QA)
-
외부 문서 없이 세계 지식만으로 질문에 답함.
-
GPT-3보다 4개 데이터셋 모두에서 성능 우위.
-
GLaM과 비교 시:
- ARC-e, ARC-c에서 더 좋음
- NQ, TQA에서는 약간 낮음
번역 (Translation)
-
학습 데이터의 90%가 영어, 일부 다국어 포함.
-
WMT’14 (Fr-En), WMT’16 (De-En, Ro-En) 기준 평가.
-
결과:
- 6개 제로샷 평가 모두에서 GPT-3보다 우수
- few-shot GPT-3보다는 다소 낮음
- 영어→타언어 번역은 상대적으로 약함
추가 과제 (Additional Tasks)
-
Commonsense Reasoning, Coreference Resolution:
- 7개 중 3개만 LaMDA-PT 초과 → 효과 미미
- 이유: 이미 언어모델의 기본 학습 목표(문장 완성)와 유사하기 때문
-
Sentiment Analysis, Paraphrase Detection, Struct-to-Text 등
→ 대부분 zero-shot FLAN이 zero-shot LaMDA-PT보다 우수,
few-shot 성능과도 비슷하거나 더 좋음.
결론 요약
🔹 Instruction tuning은 “지시문 형태로 표현 가능한 과제”에서 탁월한 효과를 보였으며,
🔹 NLI, QA, 번역, 요약 등 고차원적 언어 이해 과제에서 특히 강력하다.
🔹 반면 언어모델링 기반 과제(상식추론, 대명사 해석) 에서는 효과가 제한적이다.
4 ABLATION STUDIES & FURTHER ANALYSIS
4.1 NUMBER OF INSTRUCTION TUNING CLUSTERS
지시문 튜닝에 사용된 과제(cluster) 의 개수가 많아질수록
모델의 제로샷 성능이 어떻게 달라지는지 확인하는 실험.
실험설정
- 자연어 추론(NLI), 비문맥 질의응답(Closed-book QA), 그리고 상식 추론(Commonsense Reasoning) 을 평가용 클러스터로 남겨둠
- 나머지 7개 클러스터를 지시문 튜닝에 사용
- 1개에서 7개까지의 클러스터를 순차적으로 추가하면서 결과를 확인
- 클러스터는 각 클러스터 내 task의 개수가 많은 순서대로 추가되었다.
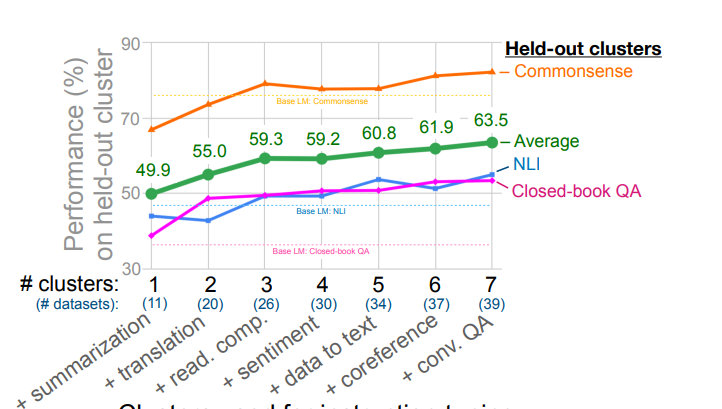
평가용으로 제외된 3개 클러스터(NLI, Closed-book QA, Commonsense) 에 대한 평균 성능은 지시문 튜닝에 포함된 클러스터와 과제의 수가 늘어날수록 향상되었다.
이는 제안된 지시문 튜닝 방법이 새로운 과제에서 제로샷 성능을 향상시키는 데 실질적인 효과가 있음을 확인시켜준다.
또한 7개의 클러스터를 모두 사용했을 때도 성능이 아직 포화되지 않았다는 것이다. 즉, 더 많은 클러스터를 추가하면 성능이 더 향상될 가능성이 있음을 시사한다.
다만, 어떤 클러스터가 각 평가 클러스터의 성능 향상에 가장 크게 기여했는가에 대해서는 알 수 없다.
단, 감정 분석 클러스터는 추가적인 이점이 거의 없었다는 점은 확인되었다.
4.2 SCALING LAWS
모델의 규모(파라미터 수) 에 따라 지시문 튜닝의 효과가 어떻게 달라지는지 확인.
이전 절(4.1)의 클러스터 분할과 동일한 설정을 사용하여,
422M, 2B, 8B, 68B, 137B 파라미터 크기의 모델들에 대해 instruction tuning의 영향을 평가.
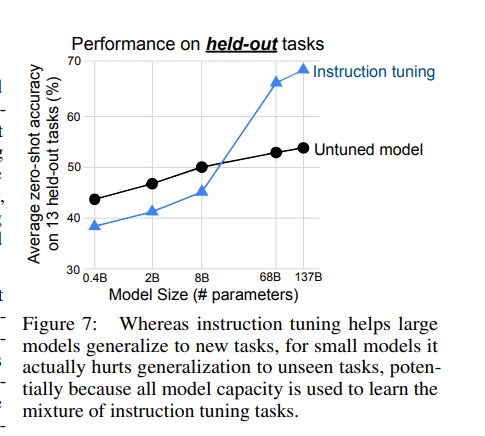
그 결과 100B 규모(즉, 68B 및 137B 모델)의 경우, instruction tuning이 보지 못한 과제에 대한 성능을 크게 향상시켰다.
하지만 8B 이하의 작은 모델들에서는 instruction tuning이 오히려 성능을 떨어뜨렸다.
이러한 현상이 나타나는 이유는 작은 모델의 경우, instruction tuning에서 사용된 약 40개의 과제를 학습하는 것만으로도 모델의 전체 용량이 가득 차 버린다.
즉, 이 모델들은 새로운 과제를 수행할 여유 용량이 남지 않아 오히려 일반화 성능이 저하된다는 것이다.
반면, 대규모 모델의 경우 instruction tuning이 모델의 일부 용량을 사용하긴 하지만, 그 과정에서 지시문을 이해하고 따르는 능력을 학습하게 된다.
따라서 남은 용량으로는 여전히 새로운 과제에 대한 일반화를 수행할 수 있게 된다.
4.3 ROLE OF INSTRUCTIONS
instruction 자체가 진짜 효과의 원인인지, 아니면 그냥 여러 과제를 동시에 학습한 멀티태스크 학습 덕분인지를 실험으로 구분
지시문이 없는 두 가지 파인튜닝 설정
-
No template 설정:
입력과 출력만 모델에 제공
예를 들어 번역 과제에서는
입력:
"The dog runs."
출력:"Le chien court."즉, 지시문이나 설명 없이 단순히 문장 쌍만 학습시켰다.
-
Dataset name 설정:
각 입력 앞에 과제 이름과 데이터셋 이름을 붙였다.예를 들어 프랑스어 번역 과제의 경우
입력:
"[Translation: WMT’14 to French] The dog runs."
출력:"Le chien court."
이 두 가지 설정을 FLAN의 방식과 비교했다.
FLAN의 경우 예시
“Please translate this sentence to French: ‘The dog runs.’”
→ “Le chien court.”

평가는 4개의 보지 못한 과제 클러스터 를 기준으로 수행했다.
-
No template 설정의 경우,
모델이 어떤 과제를 수행해야 하는지 알 수 없기 때문에,
제로샷 추론 시에는 FLAN의 지시문을 추가로 사용했다. -
Dataset name 설정의 경우,
제로샷 추론 시 두 가지 버전 모두 평가했다 —
FLAN 지시문을 사용하는 경우와, 데이터셋 이름만 사용하는 경우.
이 두 가지 설정은 모두 FLAN 방식보다 성능이 크게 낮았다.
즉, 학습 단계에서 실제 지시문을 함께 사용하는 것이, 새로운 과제에 대한 제로샷 성능 향상에 결정적으로 중요하다는 것이 확인되었다.
4.4 INSTRUCTIONS WITH FEW-SHOT EXEMPLARS
추론 시 few-shot 예시가 주어졌을 때 instruction tuning이 어떻게 작동하는지
실험은 이전과 동일한 태스크 분할 및 평가 절차를 사용했다.
즉, unseen 과제에 대해서는, inference 시에만 few-shot 예시를 추가했다.
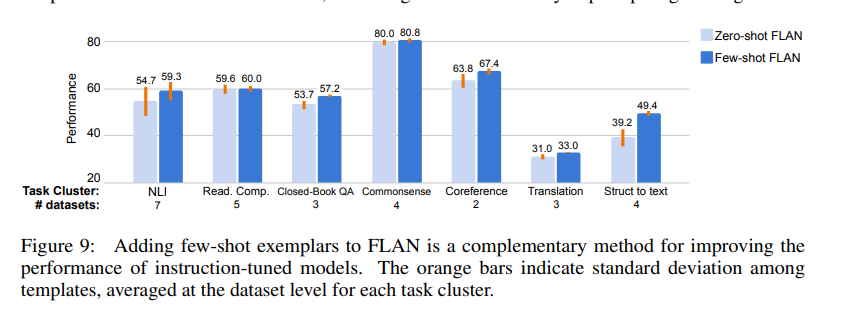
Figure 9에 나타난 결과를 보면, few-shot 예시를 추가했을 때 모든 과제 클러스터에서 성능이 향상되었다. 이는 zero-shot FLAN보다 항상 우수한 결과를 보여준다.
특히 출력 공간이 크거나 복잡한 과제들 —Struct-to-Text,번역, Closed-book QA
같은 과제에서는 few-shot 예시의 효과가 훨씬 두드러졌다.
이는 예시가 있으면 모델이 출력 형식을 더 명확히 이해할 수 있기 때문이다.
추가로 모든 과제 클러스터에서, few-shot FLAN의 템플릿 간 표준편차가 zero-shot FLAN보다 낮게 나타났다.
즉, few-shot 예시를 사용하면 모델이 프롬프트 문구(templates)에 덜 민감해지고, 프롬프트 엔지니어링에 덜 의존하게 된다.
4.5 INSTRUCTION TUNING FACILITATES PROMPT TUNING
지시문 튜닝이 된 모델은 소프트 프롬프트 튜닝도 더 잘 된다”는 걸 증명하는 실험
Instruction tuning은 모델이 사람의 지시문에 더 잘 반응하도록 훈련하는 방법이다. 그렇다면, 이렇게 지시문에 잘 반응하는 모델(FLAN)은 soft promp 를 사용할 때도 더 좋은 성능을 낼 수 있을까?
Soft Prompt: 모델 입력 앞에 연속 벡터를 붙이고 학습시키는 방식. (텍스트 명령 대신 벡터로 과제 정보를 전달함)
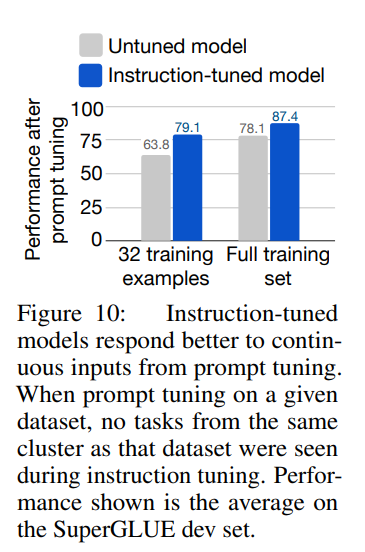
두 가지 환경에서 실험
- 충분한 데이터
- 적은 데이터
모든 경우에서 결과는 일관적으로 FLAN이 LaMDA-PT보다 프롬프트 튜닝 성능이 더 좋았다.
특히 데이터가 적은 환경에서는 FLAN이 LaMDA-PT보다 10% 이상 성능 향상
이는 Instruction tuning을 거친 모델은 지시문을 잘 따르는 것뿐만 아니라, 다른 방식의 학습에도 더 잘 적응하는 좋은 초기 상태가 된다는 것을 보여준다.
5. RELATED WORK
| 구분 | 기존 연구 | FLAN의 차별점 |
|---|---|---|
| QA 기반 학습 | NLP 과제를 질문–답변 형태로 통합 (주로 multi-task 초점) | 자연어 지시문 기반으로 제로샷 일반화 향상 |
| Instruction-following 연구 | 지시문 학습은 있었지만 모델 규모 작음(≤11B) | 137B 대규모 모델에 instruction tuning 적용 |
| 학습 방식 | 대부분 단순 fine-tuning | 60개 이상의 지시문 데이터셋 혼합 튜닝 |
| 결과 | few-shot 성능 위주 개선 | zero-shot + few-shot 둘 다 향상, GPT-3 능가 |
6 DISCUSSION
⚠️ Limitations
-
클러스터 분류의 주관성
과제를 12개 클러스터로 나누는 과정에서 일부 분류가 연구자 판단에 의존했음. -
짧은 명령어만 사용
대부분의 instruction이 한 문장짜리 간단한 형태였음.
(실제 사용자 지시처럼 긴 문장은 다루지 않음) -
데이터 중복 가능성
평가 예시 일부가 모델의 사전학습 데이터(web text)에
포함되어 있을 가능성이 있음. 하지만 사후 분석 결과, 큰 영향은 없는 것으로 확인됨. -
모델 규모 문제
FLAN-137B는 너무 커서 실제 서비스 운영에는 비용이 큼.
향후 연구 제안 (Future Work)
- 더 다양한 과제 클러스터 수 확장
- 다국어 instruction tuning 실험
- FLAN을 이용해 새로운 데이터 생성 및 다른 모델 학습 보조
- 편향,공정성 개선을 위한 미세조정 연구
