0. ABSTRACT
Chain-of-Thought 프롬프트는 복잡한 추론 문제에서 LLM의 성능을 높이지만, 일반적으로 greedy 디코딩만 사용해 하나의 추론 경로만 생성한다는 한계가 있음.
이를 해결하기 위해 본 논문에서는 Self-Consistency 디코딩 전략을 제안함.
이는 아래와 같은 특징이 있음
- 여러 개의 다양한 추론 경로를 샘플링
- 각 경로의 최종 답을 비교하여 가장 일관된(빈도가 높은) 답을 선택
즉, 여러 번 생각하게 하고 다수가 동의한 답을 택한다는 방식
-> 복잡한 문제는 다양한 사고 경로가 존재하지만, 올바른 답은 하나로 수렴한다는 점을 이용
1.INTRODUCTION
LLM은 여러 NLP 과제에서 뛰어난 성과를 보이지만, 추론 능력은 여전히 약점으로 평가된다. 단순히 모델 크기를 키우는 것만으로는 이 한계를 극복할 수 없음.
기존 접근: Chain-of-Thought (CoT) Prompting
: 모델이 사람처럼 단계별 추론 과정을 문장으로 생성하도록 유도.
예시:
“주차장에 3대가 있고 2대가 더 오면?”
→ “3대가 있다. 2대가 더 왔다. 이제 3 + 2 = 5. 정답은 5.”
이 방식은 다단계 추론 과제에서 성능을 크게 향상시킴. 그러나 기존 CoT는 탐욕적 디코딩으로 한 가지 추론 경로만 따름
⇒ 다양한 사고 가능성을 반영하지 못하고 local optimum에 갇히기 쉬움.
| 용어 | 의미 | 비유 | 문제점 |
|---|---|---|---|
| 국소 최적해(Local Optimum) | 주변에서는 제일 좋아 보이지만, 전체적으로는 더 좋은 해가 있음 | 낮은 봉우리에 올라가서 “여기가 정상이다!” 착각 | 탐욕적 선택 때문에 더 좋은 해를 놓침 |
| 전역 최적해(Global Optimum) | 전체 중 진짜 최고 해 | 가장 높은 산 정상 | Self-Consistency가 이걸 더 잘 찾게 해줌 |
해결책: Self-Consistency 디코딩 전략
1️⃣ 여러 추론 경로를 샘플링
2️⃣ 각 경로에서 나온 답들을 비교
3️⃣ 가장 일관된 답을 최종 정답으로 선택
- 탐욕적 디코딩의 반복성과 국소 최적화 문제 해결
- 단일 샘플링의 불안정성 완화
- 다양한 사고 경로를 활용해 더 안정적이고 신뢰도 높은 추론 결과 도출
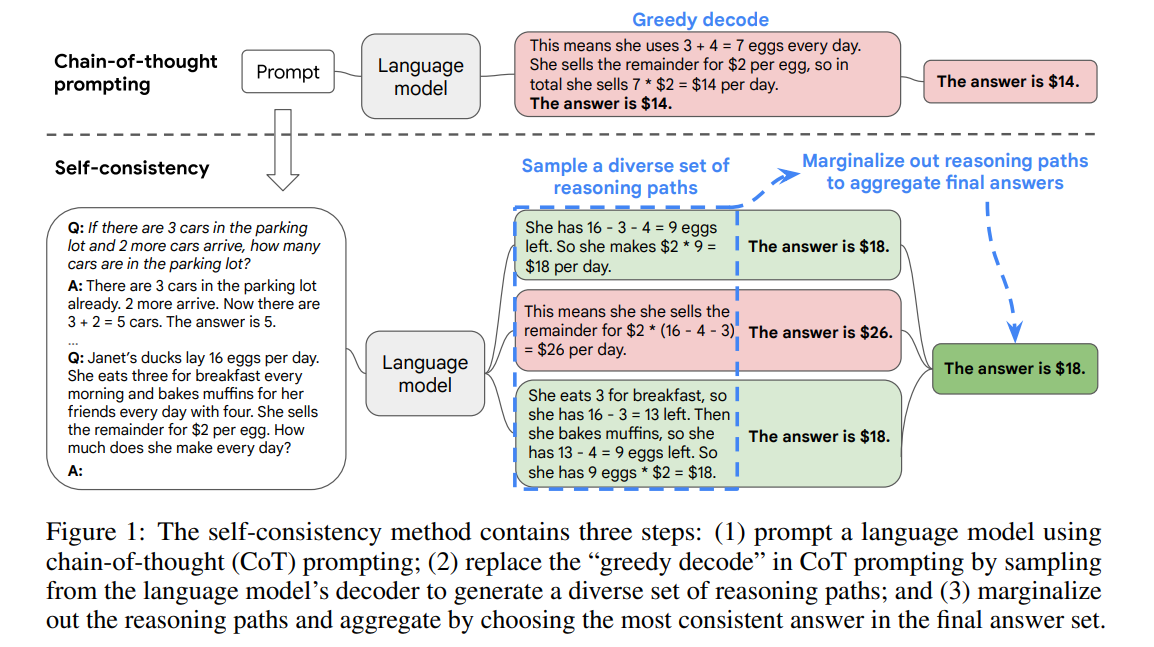
기존과 다른 Self-consistency 방법
- 먼저 언어 모델에 Chain-of-Thought 프롬프트를 입력한다.
- 기존처럼 하나의 최적 추론 경로만 탐욕적으로 생성하지 않고,
- 모델의 디코더에서 여러 가지 추론 경로를 샘플링 한다.
- 각 추론 경로는 서로 다른 최종 답변에 도달할 수 있다.
- 따라서 여러 경로에서 공통적으로 도출되는 일관된 답을 찾아내기 위해, 샘플링된 추론 경로들을 주변화하여 최종 정답을 결정한다.
Q1) 모델의 디코더에서 여러 가지 추론 경로를 샘플링은 어떻게 하는지
A) 모델이 예측한 “다음 단어의 확률 분포”에서, 확률에 비례해 무작위로 단어를 선택해 여러 번 문장을 생성하는 것.
1️⃣ 모델은 매 스텝마다 다음 단어의 확률 분포를 계산함.
예:
"mat" → 0.7
"floor" → 0.2
"couch" → 0.12️⃣ 탐욕적 디코딩은 확률이 가장 높은 단어(“mat”)만 계속 선택해서
→ 항상 같은 문장, 같은 reasoning path를 만듦.3️⃣ 샘플링은 이 확률을 비례 확률로 반영해서
→ 매번 랜덤하게 선택함.
- “mat”은 자주 뽑히지만,
- “floor”, “couch”도 가끔 선택될 수 있음.
4️⃣ 이렇게 확률을 반영한 무작위 선택을 여러 번 반복하면,
→ 매번 조금씩 다른 추론 경로가 생김.5️⃣ 다양성을 조절하는 temperature 값으로 무작위 정도를 조정함.
- temperature=0 → 항상 같은 답
- temperature=1 → 적당한 다양성
- temperature>1 → 창의적이지만 불안정
Q2). 주변화란?
A) 여러 추론 경로가 낸 결과를 종합해서, 가장 일관된(자주 나온) 답을 최종 정답으로 선택하는 과정.
1️⃣ 여러 번 샘플링해서 얻은 reasoning path 각각의 최종 답만 추출함.
예:
Path1 → $18
Path2 → $26
Path3 → $18
Path4 → $182️⃣ 각 답이 등장한 빈도(혹은 비율) 를 계산.
$18 → 3회 (75%)
$26 → 1회 (25%)3️⃣ 가장 자주 나온 답(=가장 일관된 답) 을 최종 정답으로 선택.
→ 이 과정을 수학적으로 “주변화”라고 부름.
→ 여러 경로의 확률을 합쳐서 최종 답의 확률을 추정
Self-consistency 방법은, 별도의 검증 모델을 추가로 학습시키거나
인간의 추가 주석을 활용해 재랭커를 학습하는 기존 접근법들보다 훨씬 단순하다.
또한 완전히 비지도 방식으로 작동하며, 사전 학습된 언어모델에 바로 적용할 수 있고, 인간 주석이나 추가 학습, 보조 모델, 파인튜닝이 전혀 필요 없다.
일반적인 앙상블 방식과도 다르다. 일반적인 앙상블은 여러 모델을 따로 학습시켜 각 모델의 출력을 결합하지만, Self-consistency는 하나의 모델 위에서 작동하는 자기 앙상블 형태다.
- sample-and-rank, beam search, ensemble 등보다 더 높은 성능
- 샘플링 전략·프롬프트 품질이 완벽하지 않아도 강건함
2. SELF-CONSISTENCY OVER DIVERSE REASONING PATHS
이 논문에서의 가설은 아래와 같다.
“올바른 추론 과정은 다양하더라도, 그 최종 답은 서로 일관되게 일치한다. 반면, 잘못된 추론 과정들은 답이 일관되지 않다.”
작동 과정
1️⃣ Chain-of-Thought 예시를 수동으로 몇 개 작성해 모델에 입력한다.
2️⃣ 모델의 디코더에서 여러 개의 후보 출력을 샘플링한다.
→ 이렇게 하면 서로 다른 추론 경로가 다양하게 생성된다.
3️⃣ Self-Consistency는 다양한 샘플링 알고리즘과 호환된다.
예를 들어:
- Temperature sampling
- Top-k sampling: 확률이 높은 단어 k개만 남겨놓고 그중에서 랜덤으로 뽑기
- Nucleus sampling (top-p): 확률이 누적해서 p(예: 90%)가 될 때까지 단어만 남기고 그중 랜덤 선택
4️⃣ 마지막으로, 생성된 추론 경로들로부터 나온 최종 답들을 모아,
주변화를 통해 가장 일관된 정답을 선택한다.
주어진 프롬프트와 질문에 대해, LLM의 디코더에서 샘플링된 개의 후보 출력은 다음과 같이 정의된다.
- 생성된 답변: ()
- 이 답변들은 고정된 답변 집합 의 원소
Self-Consistency는 여기에 추가적인 잠재 변수 를 도입한다.
- 추론 경로 (Reasoning Path):
- 는 번째 출력의 **추론 경로를 구성하는 토큰들의 시퀀스
각 쌍 는 가 로 이어지는 관계를 갖는다. 즉, 는 최종 답 를 도출하기 위한 중간 추론 과정일 뿐이며, 답변 를 얻기 위해서만 사용된다.
| 요소 | 내용 | 설명 |
|---|---|---|
| 추론 경로 | "She eats 3 for breakfast ... So she has 9 eggs * $2 = $18." | 최종 답을 도출하기 위해 모델이 생성한 중간 계산 및 논리적 단계 |
| 최종 답 | 18 | 마지막 문장 "The answer is ."에서 파싱되어 추출되는 최종 결과 값 |
주변화
디코더에서 여러 개의 (추론 경로 , 최종 답변 ) 쌍을 샘플링한 후, Self-Consistency는 다음과 같은 다수결 과정을 통해 주변화를 수행하고 최종 답을 결정한다.
Self-Consistency는 샘플링된 개의 답변 중 가장 빈번하게 등장한 답 를 최종 답으로 선택
- : 지시 함수
- 샘플링된 번째 답변 가 특정 후보 답변 와 일치하면 1의 값을 갖고, 일치하지 않으면 0의 값을 갖는다.
- : 전체 개의 샘플 중 후보 답변 가 등장한 빈도수를 계산.
- : 모든 가능한 답변 중에서 빈도수가 최대가 되는 답변 를 최종적으로 선택하라는 의미
즉, 가장 자주 등장한 답 𝑎를 선택한다. 이를 가장 일관된 답이라고 정의한다.
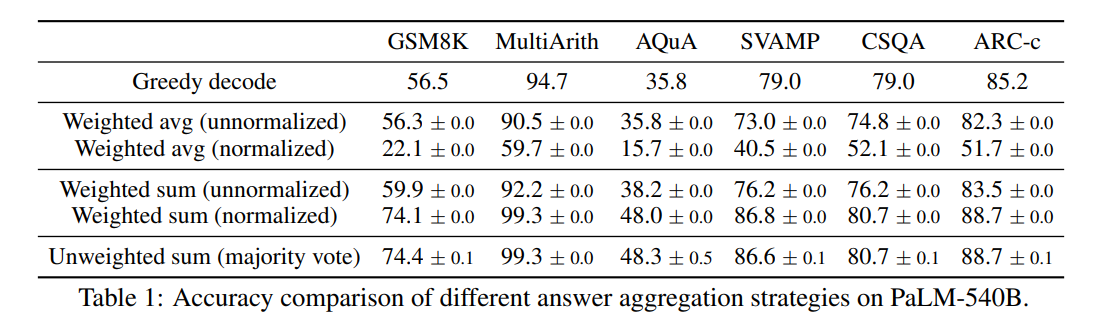
Self-Consistency 논문에서는 여러 답변 통합 방식에 대한 성능 비교를 진행했다.
1). 단순 다수결
- 여러 𝑎𝑖 중 가장 자주 나온 답을 바로 선택
- 결과적으로 정규화된 가중합 방식과 거의 동일한 정확도
2). 가중치 기반 통합
- 각 쌍 에 대해 모델의 확률 로 가중치를 부여
- 이 확률은 모델이 해당 답을 생성할 확률로 계산되며,
두 가지 방식이 있다:- 비정규화: 단순 생성 확률 합
- 정규화: 출력 길이 𝐾로 나누어 조정
| 기호 | 의미 | 쉬운 설명 |
|---|---|---|
| 번째 단어(토큰) | LLM 출력 시퀀스(와 ) 중 번째로 생성된 단위. | |
| 번째 단어가 나올 확률 | "이전 단어들(), 프롬프트, 질문이 주어졌을 때 다음 단어()가 나올 확률"을 모델이 계산한 값. | |
| 로그 | 확률들의 곱셈을 덧셈으로 변환하여 계산을 용이하게 함. (확률은 0과 1 사이 값이므로 로그를 취하면 음수 값이 됨) | |
| 로그 확률의 총합 | 전체 시퀀스 의 결합 확률을 로그 형태로 합산한 값. | |
| 평균 | 전체 시퀀스의 로그 확률 평균. 문장(시퀀스) 길이가 로 길어져도 해당 확률 값이 불리해지지 않도록 길이에 맞춰 조정하는 정규화 역할. | |
| 지수 변환 | 를 되돌려서 로그 평균 확률을 다시 원래의 확률(0과 1 사이 값) 형태로 복원. |
3). 가중 평균
- 각 답 𝑎에 대해 가중치의 합을 해당 답의 출현 횟수로 나눈다.
- 결과적으로 가장 낮은 성능을 보임.
단순 다수결로 고른 결과랑, 확률 가중치를 써서 고른 결과가 거의 같았다.
Self-Consistency는 Open-ended generation와 Fixed-answer reasoning 사이의 중간 지점에 해당한다.
즉, 완전히 자유로운 창작도 아니고, 하나의 정답만 내는 단답형도 아님. 여러 사고 과정을 거쳐 합의된 정답을 내는 방식에 가깝다.
- 현재 방식은 정답이 명확히 정의된 문제에 가장 적합.
- 하지만 여러 생성 결과 간 일관성을 평가할 기준만 마련된다면,
→ open-text generation (예: 요약, 창작) 영역으로도 확장 가능하다.
