2021년 3월 28일 출간된 논문으로 정상 이미지를 사용하여 결함 이미지를 만들어내는 Defect-GAN 제안 및 설명에 대한 논문입니다.
혹시나 잘못된 내용이 있을 경우 알려주시면 감사하겠습니다.
Abstract
저자는 미래 생산 공정에서 효율이 좋고 결과가 잘나오는 유지, 보수, 공정을 위해서 자동 결함 검사는 중요하다고 주장합니다. 하지만 자동 결함 검사는 결함 이미지가 적기때문에 제약이 항상 존재합니다. 그것을 해결하고자 저자는 Defect-GAN을 선보이고, 이 모델로 사실적이며 다양한 결함에 대한 이미지를 만들 수 있다고 합니다. Defect-GAN은 defacement와 restoration을 통해서 학습하며, defacement 과정에선 정상 이미지에 결함을 만들고, restoration 과정에선 결함 이미지를 정상으로 만드는 과정을 거칩니다.
Defect-GAN은 다른 질감과 외형을 가진 다양한 배경 이미지에 사실적인 결함을 만들기 위해 새로운 구성의 레이어 기반 구조를 가지고 있고, 결함의 확률적인 분포를 따라하며, 결함의 위치 또는 카테고리(Class) 를 조절해서 사용할 수 있습니다.
Introduction
자동 결함 검사는 여러가지 유형의 결함을 찾는 것이 일반적인 목표입니다. 이런 기능은 제조 및 건설에서 중요한 사항입니다.
제조 업에선 기계가 고장나거나, 생산을 올리기 위해서 유지,보수, 공정에서 하나의 구성요소입니다. 다른 예로 건설업에선 빌딩, 다리와 같은 다양한 구조에서 잠재적인 위험을 확인 할 수 있기때문에 중요합니다.
하지만 자동 결함 검사 분야는 수년간 연구가 되었음에도 불구하고, 여전히 어려운 분야로 남아있습니다. 그 이유는 앞서 언급했던 결함 이미지의 부족입니다. 여기에는 두가지 이유가 있는데, 첫번째로는 Labeling이 된 결함 이미지를 많이 만들고 모으기 위해서는 시간과 비용이 너무 많이 소요되고, 두번째는 단순히 시간과 노력을 들인다고 해서 결함 이미지를 모을 수 있는 것이 아니다 라고 주장합니다.
일반적으로 많은 환경에서 결함 이미지는 희귀하고, 구한다고 해도 그 양은 필요한 양에 비하면 턱 없이 모자릅니다. 그렇기 때문에 효과와 효율이 좋은 자동 결함 검사 시스템을 만드는 과정에서 많은 양의 결함 이미지 가용성이 걸림돌이 됩니다.
사담을 좀 적자면, 저 또한 제조업에서 근무를 하고 있어서 실제로 딥러닝을 학습시킬때, 결함 이미지가 정말 적다는 것을 많이 느낍니다. 정상 이미지는 언제나 충분하지만, 결함 이미지는 심한 곳은 1장만 제공될 때도 있고, 많아 봤자 20장 이런 경우가 정말 많습니다.
저자는 이러한 문제를 해결하기 위해 최근 몇년간 많은 발전을 이루어낸 GAN을 사용하고자 합니다. 물론 GAN을 사용하는데 있어서 몇가지 문제가 존재하는데, 첫번째는 현존하는 GAN 모델들은 대용량 학습 데이터를 사용하고, 두번째로 GAN은 간단한 구조와 패턴을 만들도록 설계되어 있고, 복잡하고 큰 확률적인 다양성을 가진 불규칙한 패턴에 적합하지 않습니다. 마지막으로 배경이 다른 결함 이미지를 수집하는 것은 보통 일이 아닌데, GAN 모델들은 같은 배경에서 다른 부분을 같게 만들도록 되어있습니다.
결과적으로, GAN 모델들은 비슷한 특징을 가진 이미지를 잘 만들어낼 수 있지만 다양한 배경에서 새로운 결함 이미지를 만들어내기에는 좋지 않습니다.
이러한 문제들을 해결하기 위해 저자는 Defect-GAN 을 통해서 다양한 위치에 다양한 결함이 존재하는 이미지를 만들 수 있도록 설계하였고, 결함 검사에도 적용해본 결과는 Experiments에서 소개하겠습니다.
Related Works
Image Synthesis
GAN은 생성기(Generator)를 학습하여 사실적인 데이터를 만들고 구별기(Discriminator)를 통해 생성기에서 만들어진 이미지를 구별하도록 학습합니다. 최근에 많은 연구들이 진행되고 있고, style translation(pix2pix, CycleGAN), super-resolution, image inpainting, multi-modal image synthesis(Stable Diffusion) 와 같이 많은 분야가 존재하지만, 현존하는 모델들은 결함 생성에 실패했습니다.
Defect-GAN은 defacement와 restoration 과정으로 시뮬레이션하고, 결함의 확률적인 분포를 따라하기 위해서 랜덤성을 추가했습니다. 그리고 결함을 특수 부위로 인식하고, layer-based architecture를 이용하여 정상 이미지에 결함을 합치게 되면, 정상 이미지의 형상을 유지하면서 다양하면서 사실적인 양질의 결함 이미지를 생성할 수 있습니다.
Learning From Limited Data
딥러닝 기반 기술들은 일반적으로 많은 데이터를 요구하지만 언제나 가능한게 아닙니다. 최근의 연구들은 데이터 부족 문제에 대해서 해결하고자 많은 시도가 있었습니다. 예를 들자면 Few-shot learning과 Data augmentation 이 있습니다.
Few-shot learning은 문자 의미대로 적은 양의 데이터로 학습하는 것을 의미합니다. 하지만 같은 domain에서 많은 양의 이미지를 요구하기 때문에 연구된 방법들은 성능이 좋지 못했습니다.
Data augmentation은 더 많은 양과 다양한 이미지로 만들어서 학습용 데이터를 풍부하게 만들기 위해 만들어졌습니다. 최근 몇가지의 연구에서는 GAN을 이용한 Data augmentation 연구하기 시작했고, 저자가 제안하는 Defect-GAN 또한 결함 이미지 검사의 성능을 더 끌어올리기 위해서 data augmentation 방법입니다.
Defect Inspection
결함 검사는 일반적으로 머신비전으로 결함의 위치를 특정하고 어떤 결함인지 확인하는 과정을 말하는데, 산업 제조업, 안전 검사, 빌딩 건설 같은 분야에선 정말 중요한 부분입니다. 딥러닝 시대가 오기 전에는 Feature Extractor와 Heuristic pipline 을 직접 만들었습니다. 그리고 딥러닝이 많이 연구되면서 Convolutional Neural Network(CNN) 을 기반으로 한 모델들이 획기적인 성능을 보여주었습니다. 하지만 통상적인 상황에서 항상 결함 이미지의 부족은 큰 문제였습니다. 결함 이미지 부족 현상을 해결하기 위해서, 일부러 정상인 제품을 부시거나, CAD를 이용해 결함 이미지를 만들어냈습니다. 저자는 이러한 문제를 해결하기 위해서 layer-wise composition strategy 와 함께 defacement와 restoration 과정을 시뮬레이션하여 양질의 사실적이고 다양성을 가진 결함 이미지를 생성합니다. 또한 이 모델은 처음 보는 배경에 대해서도 결함 패턴을 생성할 수 있다고 합니다.
Method
Defect-GAN for Defect Synthesis
저자는 정상 이미지는 충분하지만 결함 이미지가 부족한 상황을 가정합니다. 이런 가정이라면, 한 쌍으로 묶지 않는 image-to-image translation의 패러다임을 따라하여 결함 이미지를 생성합니다. 이 방법은 적은 학습 데이터가 필요하고 데이터에 충실한 가짜 이미지를 만들어 낼 수 있습니다. Defect-GAN은 정상 이미지에 결함을 생성하는 defacement가 항상 존재하고, 결함 이미지에서 정상으로 가는 restoration 과정을 기반으로 설계되어 있습니다. 두가지 과정을 따라하기 위해서많은 양의 정상이미지를 이용할 겁니다.
모델의 구조는 생성기 와 구별기 로 구성되어 있고, 학습 단계 동안 모델은 생성기를 이용해 두 싸이클동안 image translation( -> -> , -> -> )을 합니다.
(hat) 이 붙은 이미지들은 입력 이미지를 재생성한 것입니다.
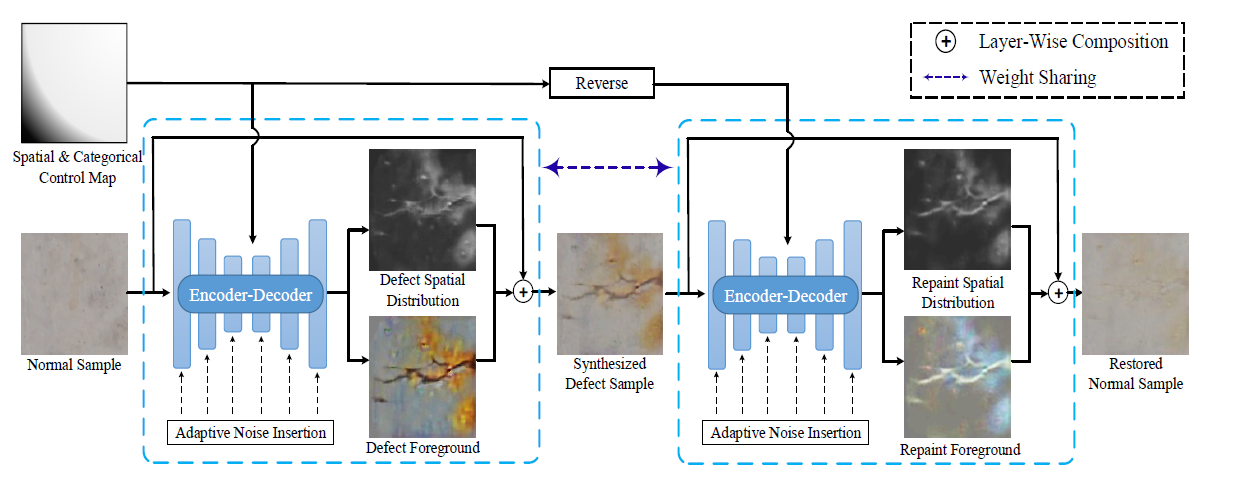
생성기 는 위와 같은 구조로 정상 이미지를 입력하면 stride가 4인 환경에서 Encoder-Decoder를 통하면서 원본 이미지 사이즈로 돌아오고, 결함의 사실적인 합성과 다양성을 향상시키기 위해서 spatial and categorical control과 stochastic variation 그리고 layer-based composition으로 설계했습니다. 층마다 Adaptive Noise Insertion을 해준 뒤, 결함 이미지의 공간 분포에서 결함에 대한 정보를 정상 이미지에 합쳐주면서 가짜 결함 이미지를 생성 합니다.
구별기 는 PatchGAN을 이용하여 입력된 이미지가 진짜인지 가짜인지 구별해주는 StarGAN과 같은 구조를 가지고 있습니다. 그리고 는 생성한 결함의 종류를 판별합니다.
Spatial and Categorical Control for Defect Generation
정상 이미지에서 다른 위치에 다른 유형의 결함들이 존재할 수도 있습니다. 생성한 결함에 대해서 공간과 종류에 대한 조절을 위해서 Spatial & Categorical Control Map 을 생성기 에 입력하여 특정 위치에 결함을 생성할 수 있도록 합니다. Spatial & Categorical Control Map 은 Spatially-adaptive denormalization (SPADE normalization)을 통해서 네트워크에 입력되고 생성기 의 decoder의 모든 block 마다 입력됩니다. 주의해야할 점은 control map 은 모든 이미지의 위치에 대해서 존재해야하며, 결함이 있다면 label을 알아야 합니다. 이러한 제약때문에 inference 과정에서 문제가 있을 수 있지만 Defect-GAN에선 context-compatible 방식으로 결함을 다른 위치에 추가하는 것을 지원합니다.
Stochastic Variation of Defects
일반적인 이미지와 다르게 결함은 GAN 모델을 적용하기에는 높은 확률적 분포를 가지고 있는 복잡하고 불규칙적인 패턴을 가진 것으로 알려져 있습니다. 이것을 해결하기 위해서 Adaptive Noise Insertion을 사용했습니다. noise injection을 시행할 때마다 모델은 입력된 노이즈의 강도를 조절하여 학습하게 됩니다. 이로 인해 더욱 다양한 사실적인 결함을 만들게 됩니다.
Adaptive Noise Insertion 이란 가우시안 노이즈를 각각의 convolutional block을 통과한 feature map에 Gaussian noise를 넣는 방법입니다.
Layer-Wise Composition
앞서 보여드렸던 Defect-GAN의 구조를 보시면, Normal Sample을 입력 값으로 주면 defacement 과정을 거쳐서 Synthesized Defect Sample이 나옵니다. 일반적인 image translation 모델은 여기까지만 하지만 Defect-GAN은 나온 결함 이미지를 가지고 restoration 과정을 거쳐서 Restored Normal Sample을 생성하게 됩니다.
Defacement 과정
= spatial-wise multiplication
= generated defect foreground
= 0~1 사이 값으로 이루어진 의 corresponding spatial distribution map
Restoration 과정
= restored normal image
= restored normal foreground
= 0~1 사이 값으로 의 corresponding spatial distribution map
설명을 드리자면, 1번 수식에서 생성기 에 정상 이미지, 과 Spatial & Categorical Control Map인 를 입력값으로 넣으면 와 정상이미지 을 이용하여 와 가 출력으로 나오게 됩니다. 이 두가지 값을 2번 수식에 대입하면 spatial-wise multiplication을 통해서 이미지 전체가 1인 이미지에서 생성된 를 빼준 이미지를 정상 이미지 과 연산을 합니다. 그리고 와 에도 spatial-wise multiplication을 적용시키면 만들어진 결함의 부분들만 남게되는데 그것을 앞서 연산한 결과 이미지와 더해주면 정상 이미지 + 생성된 결함 부분이 되기 때문에 Synthesized Defect Sample의 결과가 나오게 됩니다.
Restoration 과정은 Defacement 과정과 똑같이 진행되지만 반대로 결함 이미지와 을 입력으로 넣어주게 됩니다.
이런 방식의 layer-based synthesis는 사실성과 다양성을 높게 만들어 낼 수 있었습니다. 백그라운드로 많은 양의 정상 이미지를 가지고 있고, Defect-GAN은 결함 생성에 집중할 수 있게 됩니다. 일반적으로 결함 이미지의 희소성 때문에 다른 모델들은 결함을 다른 배경에 합성할 수 있는 가능성이 적지만, 해당 모델은 많은 정상 배경 이미지를 학습하였고 결함 생성에만 집중할 수 있기 때문에 다양한 배경에 결함을 생성 할 수 있습니다.
Training Objective
이 논문에선 Loss 값을 구할 때 쓰는 수식이 몇가지가 있습니다.
제대로 이해 못한 부분이 있을 수 있으니 참고 바라고, 잘못된 부분이 있다면 알려주시면 감사하겠습니다
는 일반적인 GAN 모델의 loss function으로 생성기 의 결과가 최소가 되면서 의 결과가 최대가 되도록 조절해주는 값입니다.
D의 시점
구별기 가 가짜와 진짜를 모두 구별할 수 있는 경우에 최대 0이라는 값을 가지는데 이 경우에는 가 1이 되면서 앞 항의 값이 0이 되고 뒷 항에서 가짜 이미지인 d를 완벽하게 구별하기 때문에 의 값이 0이 됩니다.
G의 시점
생성기 가 가짜 이미지를 진짜같이 만들 때 최소값 를 가지게 됩니다.
이 경우에는 뒷 항의 값이 가 1에 가까워지면서 로그함수의 특성으로 인해 으로 발산하게 되고, 앞 항의 값은 구별기 와 에 관한 항으로 관련이 없어서 무시하셔도 됩니다.
Loss function
6번 수식은 결함 이미지 의 결함 종류가 와 같은지에 대한 확률을 보여주는 위한 loss 입니다. 만약 정답을 맞추지 못하면 loss 값이 증가하게 됩니다.
7번 수식은 6번 수식과 변수만 다를 뿐, 똑같이 작동하므로 설명을 생략하겠습니다.
8번 수식은 reconstruction loss이며, 과 은 정상 이미지와 재생성된 정상 이미지를 의미합니다. 과 에 L1 norm 적용 후 차이를 이용한 loss로 정상 이미지와 재생성된 정상 이미지에 대한 유사도를 나타낸다고 생각하시면 쉽습니다. 모델은 해당 loss를 이용하여 loss가 작아지도록 학습하여 모델이 이미지가 더욱 유사하게 생성되도록 합니다.
9번 수식은 8번과 유사하지만 spatial distribution cycle-consistency loss이며, 대상이 다릅니다. 은 입력으로 쓰인 정상 이미지에 대한 mid-level representation 이고, 은 재생성된 정상 이미지의 mid-level representation 입니다. 두 값의 차이의 의미는 입력 이미지와 다르게 restoration 됐다는 것을 의미하기 때문에 해당 loss를 줄이는 방향으로 학습하게 됩니다.
10번 수식은 결함의 영역 과 전경(foreground) 영역을 제한해서 결함이나 전경이 너무 큰 부분을 차지하지 않도록 하기위한 region constrain loss 입니다. 결함은 일반적으로 적은 영역을 차지하기 때문에 너무 크게 나온 경우 잘못 생성된 것으로 판단하여 더 적은 영역을 차지하는 결함을 생성하도록 하는 방향으로 학습하게 합니다.
11번 수식은 앞서 설명한 loss들의 조합을 이용하여 구별기 의 최종 loss로 5번 수식인 에 마이너스 부호를 붙임으로써 D의 시점에서 의 최대값이 이 되고 최소값이 0이 되고, 은 6번 수식에 hyper-parameter 를 곱해준 식으로 의 성능이 개선되면서 앞 항의 값이 최소가 되고 가 결함의 종류를 잘 맞추는 방향으로 학습하여 이 최소가 됩니다.
12번 수식은 5번 + 7번 + 8번 + 9번 + 10번 수식들을 모두 더한 값이고, hyper-parameter 인 가 곱해져있습니다. 이 수식은 G의 시점에서 의 최소값은 이며, 나머지 수식들은 각 수식 설명에서 자세하게 설명한 방향으로 학습을 진행하게 됩니다.
Experiments
데이터셋
- CODEBRIM 데이터
실험 방법
- Defect-GAN의 결함 합성에 대한 성능 측정
- Data augmentation 으로써 결함 분류에 주는 영향에 대한 측정
Defect Synthesis
Data : all images resized 128x128 in CODEBRIM + 50,000 normal image patches cropped from original full-resolution images
Optimizer : Adam (, )
Learing rate : from and reducing to
GPU : NVIDIA 2080 Ti
Batch-size : 4
Total training iteration : 500,000
학습을 안정화하고 더욱 좋은 이미지를 만들기 위해 5번 수식을 Wasserstein GAN Objective with gradient penalty 로 대체하였고, 5번의 구별기 업데이트마다 생성기 를 한번 업데이트 했습니다.
Evaluation metric
Frechet Inception Distance (FID)
FID는 다음과 같은 단계로 계산됩니다:
- 실제 이미지와 생성된 이미지를 Inception 모델을 통해 특징 벡터로 추출합니다.
- 추출된 특징 벡터들의 평균과 공분산을 계산합니다.
- 실제 이미지의 특징 벡터들과 생성된 이미지의 특징 벡터들 간의 Fréchet distance를 계산합니다.
두 확률 분포 R와 G가 주어졌을 때, R의 평균을 , R의 공분산 행렬을 , G의 평균을 , G의 공분산 행렬을 라고 가정합니다.
여기서 는 평균 벡터 간의 유클리드 거리의 제곱이고, 는 행렬의 트레이스(대각 요소의 합)를 나타냅니다. 는 와 의 행렬 곱의 제곱근 행렬입니다.
이러한 수식을 통해 FID는 생성된 이미지와 실제 이미지 간의 차이를 측정하고, 생성 모델의 품질을 정량화하는 데 사용됩니다.
FID Score 로 여러가지 모델들과 비교하면 아래의 Table 1 이미지와 같은 결과가 나옵니다.

Applied to classification training set as data augmentation
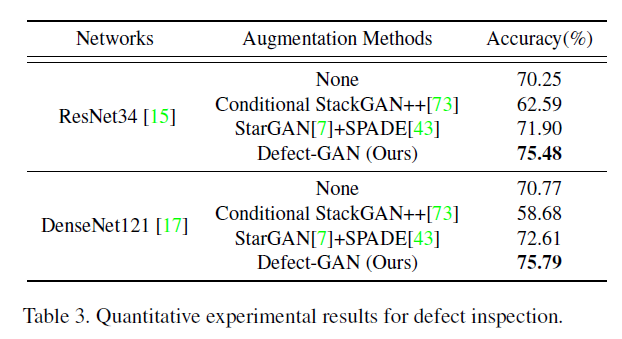
저자는 Defect-GAN을 이용하여 data augmentation 으로써 training data 를 학습하고 생성한 이미지를 통해 분류가 잘되는지 확인을 했고, 다른 모델에서도 같은 데이터 셋으로 생성하여 classification 모델을 학습 해본 결과 아래 Table 3와 같은 결과를 보였습니다.
Conclusion

Defect-GAN은 다른 모델들에 비해서 우수한 성능을 보이는데, 위의 그림은 같이 배경의 특징이 다른 정상 이미지에 결함 종류별로 생성한 이미지입니다. 보시다시피, 배경이 달라진다 해도 결함의 형상이 제대로 생성되는 것을 확인할 수 있고, 다양성을 가진 결함의 위치와 형상을 확인하실 수 있습니다.
Reference
제목 : Defect-GAN: High-Fidelity Defect Synthesis for Automated Defect Inspection
링크 : https://arxiv.org/abs/2103.15158
참고 블로그 : https://velog.io/@hyebbly/Deep-Learning-Loss-%EC%A0%95%EB%A6%AC-1-GAN-loss
개인적인 의견
저는 GAN에 대해서 공부를 시작한지 얼마 안됐습니다. Defect-GAN 논문은 두번째로 본 논문이고, 첫번째로 본 논문은 DFMGAN 이라는 모델을 제안한 Few-Shot Defect Image Generation via Defect-Aware Feature Manipulation 입니다. 해당 논문에 대한 리뷰도 조만간 남길 예정이고, Defect-GAN 보다 더 좋은 성능을 보이는 것으로 보이니 한번씩 보시는 것도 좋을 것 같습니다!
