60.8 mIoU on ADE20K, 59.4 PQ on COCO
DETR with Improved Denoising Anchor Boxes → DINO
Introduction
- DETR-like 모델들은 set-prediction 을 적용하고 anchor design, non maximum suppresion 같은 것들을 제거함
- DINO 는 DAB-DETR 로부터 dynamic anchor box formulation 을 가져왔고, DN-DETR 로부터 query denoising training 을 가져와서, DETR-like 모델류에서 처음으로 COCO object detection SOTA 성능을 이뤄냄
- detection 과 segmentation 은 서로 도움이 되지 못하는 이유와 task 특화 모델을 대체할 수 있는 통합모델을 개발하는게 가능한지를 고민함
- DINO 의 box prediction branch 에 mask prediction branch 를 추가함
- backbone 과 transformer encoder 로부터 얻어진 high-resoluion pixel embedding map 에서 모든 segmentation task 에 mask classification 을 수행하기 위해서 DINO 에서 나온 content query embedding 을 재사용함
- DINO 는 region-level regression 인 detection model 이기때문에 pixel-level alignment 에 맞춰져있지 않음
- detection 과 segmentation 사이 에서 features 를 더 잘 맞추기 위해서 3가지를 제안함
- unified and enhanced query selection
- anchor 역할인 mask query 를 초기화 하기 위해서 최상위 tokens 에서 mask 를 추론함으로써 encoder dense prior 을 이용함
- pixel-level segmentation 이 early stage 에서 학습하기 더 쉽다는 것을 확인했고, boxes 품질을 향상 시키기위해서 initial mask 를 사용하기를 제안함
- segmentation 학습을 가속시키기 위해 masks 에 대해 unified denoising 학습을 제안함
- GT 에서 boxes 와 masks 더욱 정확하고 일관성 있는 매칭을 위해 hybrid bipartite matching 을 사용함
- unified and enhanced query selection
- detection 과 segmentation 사이 에서 features 를 더 잘 맞추기 위해서 3가지를 제안함
MaskDINO
-
DINO 의 확장판
- DINO 는 box prediction 과 label prediction 을 위한 두가지 branch 가 있고, boxes 는 유동적으로 업데이트 되고, 각각의 transformer decoder 에서 deformable attention 을 가이드하기 위해 사용됨
-
MaskDINO 는 segmentation tasks 에 맞추기 위해서 detection 의 중요 구성 요소를 최소한으로 확장했고, mask predicition 을 위한 branch를 추가함
-
DINO
- DINO 는 backbone, transformer encoder, decoder 를 가진 전형적인 DETR-like 모델임 (빨간 부분은 제외)
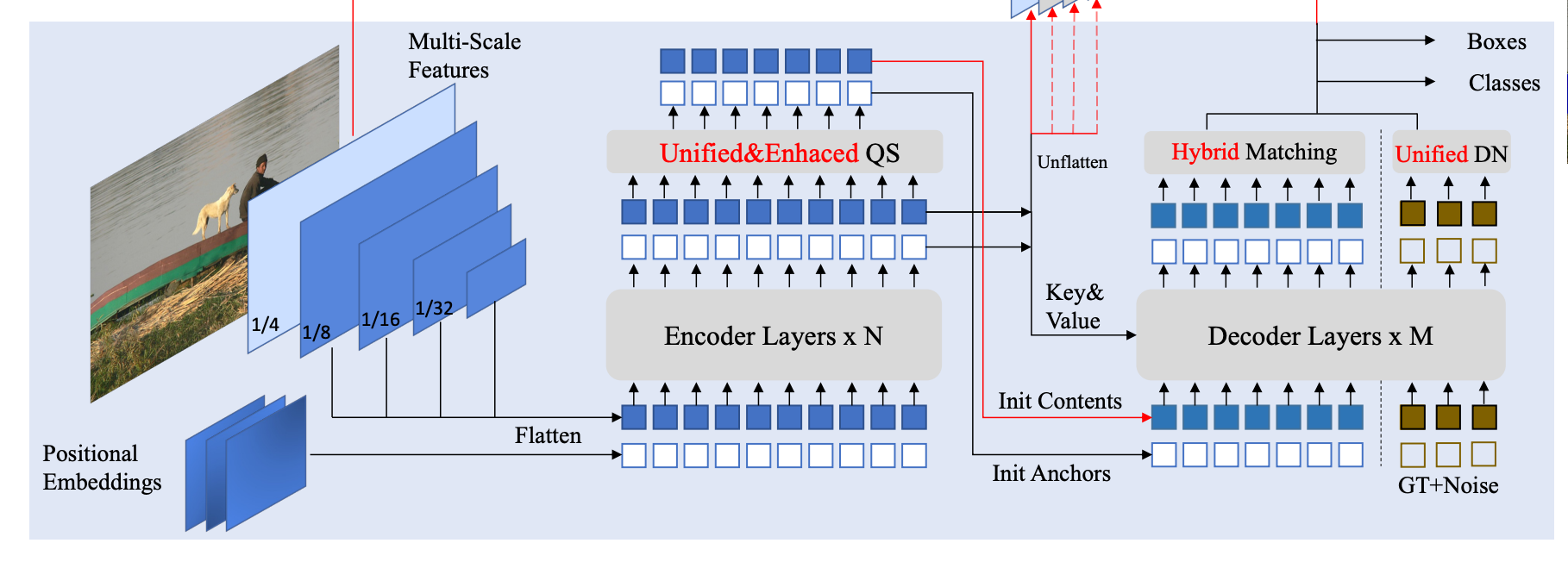
- DAB-DETR 을 참고하여, DETR 에서 각각의 positional query 를 각각의 decoder layer 를 통해서 동적으로 업데이트되는 4D anchor box 로 계산함
- 4D anchor box 는 sparse 하고 soft 한 방법으로 deformable attention 을 제한할 수 있음
- DINO 는 deformable attention 과 함께 multi-scale features 을 사용함
- DN-DETR 을 참고하여, denoising 학습과 학습의 수렴을 가속화하기 위해서 contrastive denoising 을 적용함
- decoder 의 positional query 를 초기화하기 위해 mixed query scheme 과 box gradient back-propagation 을 향상 시키기 위해 look-forward-twice 방법을 제안함
- DINO 는 backbone, transformer encoder, decoder 를 가진 전형적인 DETR-like 모델임 (빨간 부분은 제외)
-
Why cannot Mask2Former do detection well?
- query 가 Conditional DETR, DAB-DETR, Anchor DETR 에서 연구된 더 좋은 positional prior 를 사용하지 않음
- 예를 들어, content queries 가 transformer encoder 를 통해서 알맞게 정렬 돼있지만, positional query 는 단순히 학습이 가능한 벡터일 뿐임
- masked-attention 을 transformer decoder 에서 사용하는데, 직전 레이어에서 나온 attention mask 는 attention 연산을 위해 빡빡한 제한 조건으로 사용되며, 고해상도임
- box prediction 기준에서 효율적이지도, 유연하지도 않음
- box refinement 를 레이어마다 수행하지 않음
- decoder 의 coarse to fine mask refinement 에 encoder 의 multi-scale features 를 사용하지 못함
- query 가 Conditional DETR, DAB-DETR, Anchor DETR 에서 연구된 더 좋은 positional prior 를 사용하지 않음
-
Why cannot DETR/DINO do segmentation well?
- DINO + DETR 에서 DETR 의 segmentation head 는 최적화 되어있지않음
- DETR 은 가장 작은 feature map 과 query embedding 을 내적하여 attention map 을 연산하고, 업샘플링해서 mask predicition 을 만드는데, 이 방식은 query 와 backbone 에서 나온 larger feature maps 간의 상호작용이 부족함
- 그리고 헤드가 mask refinement 를 위해 mask auxiliary loss 를 쓰기에 너무 무거움
- DINO + Mask2Former 는 DINO 에서 나온 features 는 segmentation 과 맞지 않음
- DINO 의 query formulation, denoising training, query selection 은 region-level 에서는 성능 향상을 보이지만, segmentation 에 최적화 된게 아님
- DINO + DETR 에서 DETR 의 segmentation head 는 최적화 되어있지않음
MaskDINO architecture
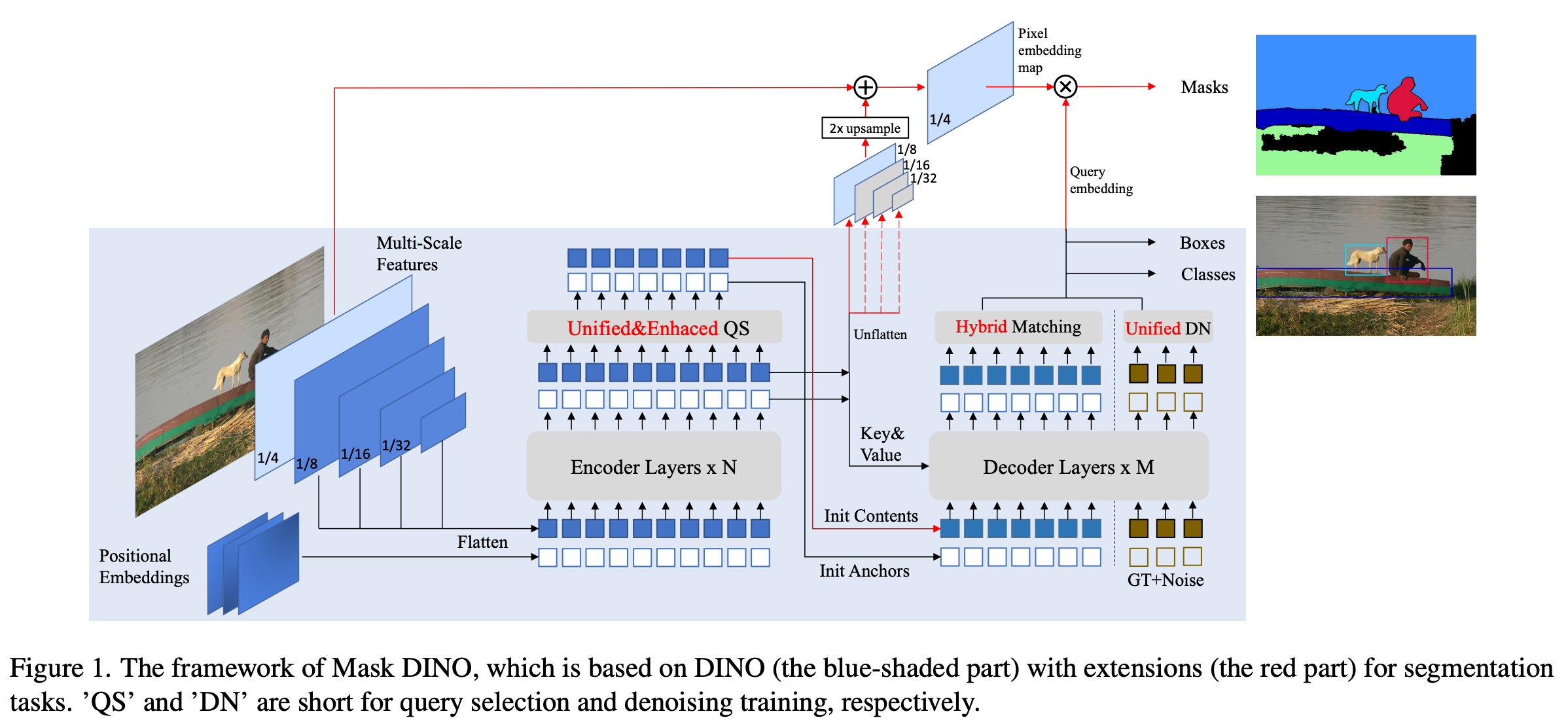
- DINO 에서 최소한의 수정을 통해서 detection 을 위한 구조를 적용함
- DINO 의 여러가지 key components 를 확장하고, segmentation 을 위한 mask branch 를 추가함
- Segmentation branch
- DINO 는 pixel-level 에 맞지 않기 때문에 mask classification 을 하기 위해서, Mask2Former 에서 backbone 와 transformer encoder features 에서 pixel embedding map 을 구성하는 아이디어를 가져옴
- pixel embedding map 은 backbone 에서 얻은 1/4 해상도의 feature map 와 transformer encoder 에서 얻은 1/8 해상도의 feature map 를 융합하여 만들어짐
- 다음 단계에서, decoder 의 content query embedding 별로 pixel embedding map 을 내적하여 output mask 을 얻음
- = segmentation head
- = transformer hidden 차원에 채널 차원을 맞추기 위한 convolutional layer
- = 1/8 해상도의 feature map 를 2배 업샘플링하기 위한 간단한 보간 함수
- DINO 는 pixel-level 에 맞지 않기 때문에 mask classification 을 하기 위해서, Mask2Former 에서 backbone 와 transformer encoder features 에서 pixel embedding map 을 구성하는 아이디어를 가져옴
- Unified and Enhanced Query Selection
- Unified query selection for mask
- 전통적인 2-stage 모델에 많이 쓰이고, DETR-like 모델들이 detection 성능을 올리기 위해 많이 사용함
- encoder output features 가 dense features 를 가지고 있어서, decoder 에게 더 좋은 우선 순위를 넘길 수 있기 때문에, decoder output에 존재하는 동일한 3개의 pridiction head 를 encoder ouput 에 붙임
- 각각의 tokens 에 대한 classification score 는 가장 순위가 높은 features 를 선택하기 위해 confidence 처럼 고려되고, 선택된 features 는 boxes 를 구하고, masks 를 추론하기 위해 고해상도 feature map 과 내적함
- 추론된 boxes 와 masks 는 GT와 비교하여 학습되고, decoder 에서 초기 anchors 로 사용됨
- 주의할 점
- DINO 는 anchor box queries 만 초기화 했지만, MaskDINO 에선 content queries 와 anchor box queries 두가지 모두 초기화 함
- Mask-enhanced anchor box initialization
- segmentation 은 object detection 보다 세밀함으로 인해 더 어려운 task 이지만, initial stage 에서 학습하기가 더 쉬움
- 예시 : per-pixel semantic similarity 비교만 필요한mask 는 고해상도 feature map 과 queries 를 내적하면 되지만, box 는 이미지에서 box 좌표를 바로 regress 해야하기 때문
- unified query selection 진행 후, mask 추론이 box 추론보다 훨씬 정확하기 때문에, 추론된 마스크에서 boxes 를 뽑은 후, decoder 에 더 좋은 anchor box 를 넣어줄 수 있음
- 해당 과정을 통해서 탐지 성능에 큰 향상을 가져옴
- segmentation 은 object detection 보다 세밀함으로 인해 더 어려운 task 이지만, initial stage 에서 학습하기가 더 쉬움
- Segmentation Micro Design
- Unified denoising for mask
- query denoising 은 detection 모델 학습의 수렴을 빠르게 하고, 큰 폭의 성능 향상을 보임
- GT 인 boxes 와 masks 에 노이즈를 추가하여 transformer decoder 에 공급하여 모델이 노이즈가 추가된 버전에서 원본 GT 객체를 재구성하도록 학습됨
- Hybrid matching
- MaskDINO 는 헐렁하게 묶여있는 2개의 head 로 box 와 mask 를 예측하는데, 2개의 헤드가 서로 일치하지 않은 box 와 mask 의 쌍을 예측할 수도 있음
- 단일 쿼리에서 더 좋은 결과를 얻기 위해 오리지널 box 와 classification loss 외에도, mask prediction loss 를 추가함
- Matching cost =
- = corresponding weight
- = loss
- MaskDINO 는 헐렁하게 묶여있는 2개의 head 로 box 와 mask 를 예측하는데, 2개의 헤드가 서로 일치하지 않은 box 와 mask 의 쌍을 예측할 수도 있음
- Decoupled box prediction
- panoptic segmentation 에서 stuff 카테고리는 box prediction 이 필요 없고 좋지 않은데, stuff 카테고리의 box prediction 을 진행하면 학습에서 thing 카테고리에 대한 detection 과 segmentation 이 잘못 될 수 있음
- stuff 카테고리에 대한 box loss, box matching 을 제거했고, deformable attention 을 사용하여 의미 있는 영역과 features 를 추출하기 위해 box prediction 파이프라인은 남겨둠
- stuff 에 대한 box prediction loss 는 계산하지 않고, stuff 카테고리의 box loss 는 thing 카테고리의 평균 값으로 지정됨
- 해당 방법으로 panoptic segmentation 에서 학습을 가속화하고, 추가적인 이득을 얻음
- panoptic segmentation 에서 stuff 카테고리는 box prediction 이 필요 없고 좋지 않은데, stuff 카테고리의 box prediction 을 진행하면 학습에서 thing 카테고리에 대한 detection 과 segmentation 이 잘못 될 수 있음
- Unified denoising for mask
- Unified query selection for mask
실험



개발을 잘하고싶은 개발자