57.7 mIoU on ADE20K, 57.8 PQ on COCO
Introduction
- 일반적인 모델들은 segmentation task 에 맞게 구조가 설계됨
- 현재는 이런 현상을 해결하기 위해 하나의 모델(universal architectures) 로 여러 segmentation task 에 사용할 수 있도록 연구되고 있음 (e.g., DETR)
- universal architecture 는 최근들어 semantic 과 panoptic segmentation 에서 SOTA 의 성능을 보여줌
- 하지만 task 에 특화 되어진 모델들에 비하면 성능이 떨어짐
- instance task 는 universal architecture 중 최고 성능이 instance 특화 모델보다 9 AP 가 낮음
- 또한, 특화된 모델들보다 학습을 시키기도 어려움
- MaskFormer 는 32GB 의 메모리를 가진 1개의 GPU로 300 epochs 를 돌아야 40.1 AP 가 나오지만, Swin-HTC++ 는 72 epochs 만에 더 좋은 성능을 냄
Key improvements
- Masked attention 을 통해서 추론한 segments 주변의 localized features 에 attention 을 제한함
- 일반적인 transformer decoder 의 cross attention 보다 빠른 수렴과 성능 향상을 보여줌
- 작은 객체 또는 영역을 segment 하는 것을 돕기 위해서 multi-scale high-resolution features 를 사용함
- 추가적인 연산이 필요 없는 self and cross-attention 의 순서 변경, 학습 가능한 query features 만들기, dropout 제거 와 같은 optimization improvements를 사용함
- 랜덤 샘플링 된 소수의 포인트들에서 mask loss 를 계산하는 방법으로 성능에 영향을 주지 않고 3배의 학습 GPU 메모리를 아낌
Universal architecture
- DETR 과 함께 나타났으며, set predicition objective 방식의 end to end 인 mask classification 구조가 어떤 segmentation task 들에도 충분함을 보여줌
- MaskFormer 는 DETR 기반의 mask classification 으로 panoptic segmentation 에서 좋은 성능을 보였을 뿐만 아니라 semantic segmentation 에서 SOTA 를 달성함
- K-Net 은 더 나아가 instance segmentation 에 set prediction 을 적용함
- 하지만, 이 모델들은 task 에 특화된 모델을 이기지 못함
- Mask2Former 는 최초로 모든 task 특화 모델들을 뛰어넘는 성능을 보여줌
Masked-attention Mask Transformer
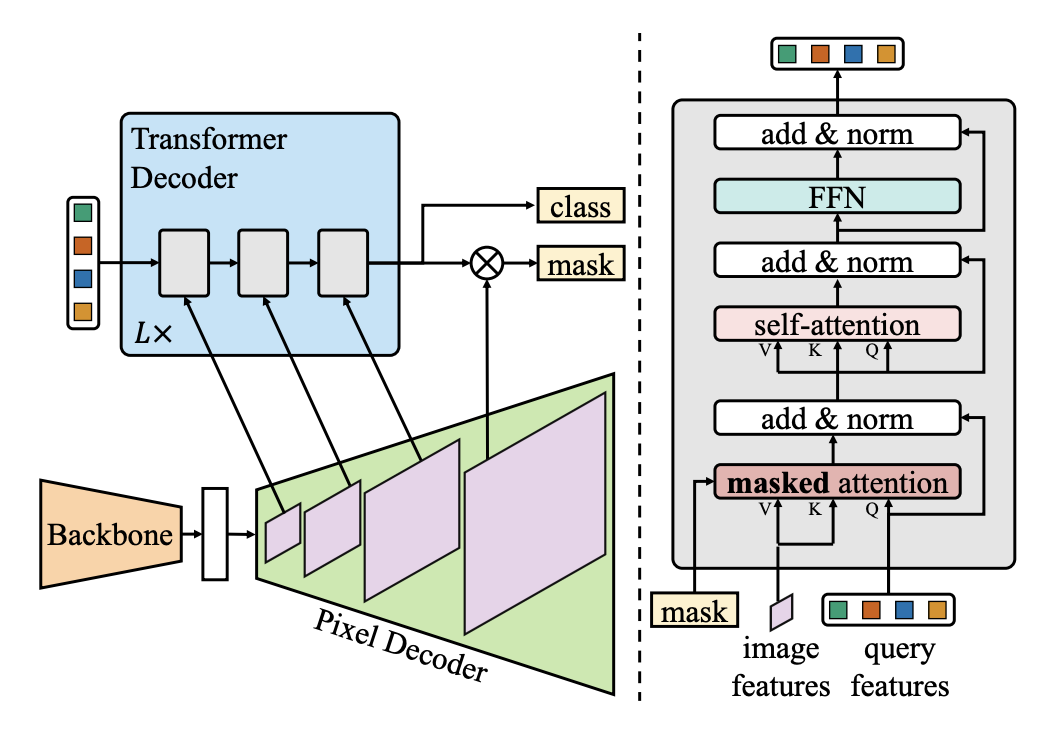
- mask classfication 을 위한 meta architecture
- 더 나은 수렴과 결과의 핵심인 masked attention 을 사용한 새로운 transformer decoder
- Mask2Former 를 더 효율적이고 사용하기 쉽게 만드는 학습 과정
-
Mask classification preliminaries
- Mask classification 은 N 개의 클래스에 따라서 N 개의 이진화 마스크를 추론하여 픽셀들을 그룹화함
- Mask R-CNN 은 semantic segmentation 을 수행하기 위해 bbox 를 사용함
- DETR 은 각각의 segment C 차원의 feature vector 로 표현할 수 있고, set prediction objective 로 학습된 transformer decoder 를 사용할 수 있음
- simple meta architecture는 backbone, pixel decoder, transformer decoder 로 구성됨
- Backbone → low-resolution feature 를 얻어냄
- Pixel decoder → low-resolution feature 를 high-resolution per-pixel embedding 을 생성하기 위해 업샘플링 해줌
- Transformer decoder → object query 를 처리하기 위해 image feature 에서 작동함
- Object query 를 사용하여 per-pixel embeddings 으로부터 최종 이진화 마스크 추론결과를 디코딩함
-
Transformer decoder with masked attention
- 일반적인 transformer decoder 를 masked attention operator 가 포함된 transformer decoder 로 변경
- feature map 전체의 attention 을 구하지 않고 각각의 query 에 대해서 추론된 마스크의 foreground 영역 내에서 cross-attention 제한하여 localized feature 를 추출
- 작은 객체를 해결하기 위해서, high-resolution feature 를 사용한 multi-scale 전략을 제안함
- 라운드 로빈 방식으로 pixel decoder 의 feature pyramid 에서 나온 연속적인 feature maps 를 연속적인 transformer decode layer 에 공급함
- 마지막으로, optimization improvements 를 통해 추가적인 연산 없이 모델의 성능을 올림
- Masked attention
- Transformer 기반 모델들은 cross-attention layer 안의 global context 로 인해서 느린 수렴이 발생한다고 함
- localized object region 을 강조하기 위해서 정말 많은 epochs가 cross-attention 에 필요함
- local features 가 query features 업데이트에 충분하고 context information 은 self-attention 으로 얻어진다고 가정함
- 각각의 query 에 대해 추론된 마스크의 foreground 영역에서만 집중하는 cross-attention 의 한가지 변형임
- residual path 를 가진 일반적인 cross-attention 식
- = layer index
- = 레이어에서 N개의 C 차원 query features
- = 선형 변환을 거친
- = transformer decoder 에 입력된 query features
- = 각각 , 변환한 image features
- , = spatial resolution of image features
- Masked attention 식
- = feature location (x,y) 의 attention binary mask
- threshold = 0.5
- ⇒ 와 같은 해상도로 리사이즈
- = 에서 얻은 이진화 마스크 추론 결과
- Masked attention
- High-resolution features
- 작은 객체에 특히나 좋아서 모델 성능을 향상시켜줌
- 연산량을 조절하기 위해서 효율적인 multi-scale 전략 제안
- 항상 high-resolution feature map 을 사용하는 것 대신, low-resolution, high resolution feature 로 루어진 feature pyramid 를 이용하고, 한번에 한개의 transformer decoder 에 multi-scale feature 중 한개의 resolution 을 공급함
- pixel decoder 로 생성된 1/32, 1/16 그리고 1/8 해상도의 feature pyramid를 사용함
- 각각의 resolution 에 sinusoidal position embedding 과 학습 가능한 scale-level embedding 을 추가함
- 두가지의 embedding 은 lowest-resolution 부터 highest-resolution 까지 모두 사용됨
- 3개의 레이어로 이루어진 transformer decoder 를 총 L 번 반복함
- 최종 transformer decoder 는 3L 레이어로 구성됨
- 라운드 로빈 방식으로 첫 3개의 레이어들은 1/32, 1/16, 1/8 사이즈의 해상도를 입력받고 뒤에 따라오는 모든 레이어가 똑같이 진행됨
- Optimization improvements
- Standard transformer decoder layer
- self-attention module, cross-attention, feed-foward network (FFN) 으로 구성됨
- query features () 는 transformer decoder 에 공급되기 전에 0으로 초기화되고, 학습 가능한 positional embedding 과 연결됨
- residual connections 와 attention maps 에 dropout 이 적용됨
- new transformer decoder layer
- 연산이 더욱 효율적이도록 self-attention 과 cross-attention 의 순서를 바꿈 (masked attention)
- 첫 self-attention layer에 입력되는 query features 는 이미지 독립적이며 이미지로부터 신호를 받지않음
- 따라서, self-attention 을 적용하는 것이 정보를 풍부하게 만들지 않음
- query features ( 를 학습 가능하게 만들고, 학습 가능한 query positional embedding 도 유지하고, query features 는 마스크를 추론하기 위한 transformer decoder 에 사용되기 전까지 학습됨
- 학습 가능한 query features 는 region proposal network 와 유사하게 작동하고, mask proposal 을 생성하는 능력도 있음
- 마지막으로, dropout 은 필수가 아니고 보통 성능을 낮추는 것을 확인해서, dropout 을 제거
- Standard transformer decoder layer
- Improving training efficiency
- 고해상도 마스크 추론으로 인한 큰 메모리 소비가 문제
- MaskFormer ⇒ 1개 이미지에 32GB 차지
- PointRend 에 의하면 랜덤 샘플링한 K 개의 포인트로 mask loss 를 계산하는 것으로 충분히 segmentation 모델을 학습 할 수 있다고 보여줌 → 해당 방법을 채용함 (matching loss + final loss)
- Matching loss : bipartite (이분법) matching 을 위한 cost matrix 를 구성하고 있고, 모든 GT 마스크와 추론 마스크에 대해서 동일한 K개의 포인트로 이루어지도록 샘플링함
- Final loss : 추론 결과와 매칭되는 GT 사이에서, importance sampling 을 사용하여 다양한 조합들로 이루어진 K개의 다양한 포인트 집합을 샘플링함
- 이 방법을 통해서 18GB → 6GB 으로 메모리 사용이 감소함
- 고해상도 마스크 추론으로 인한 큰 메모리 소비가 문제
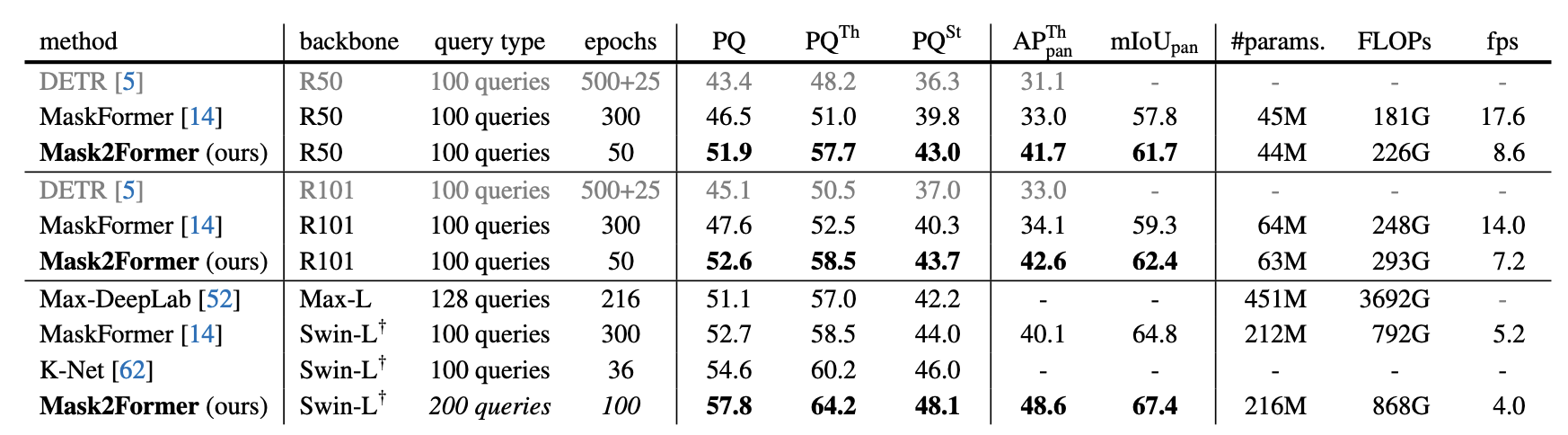
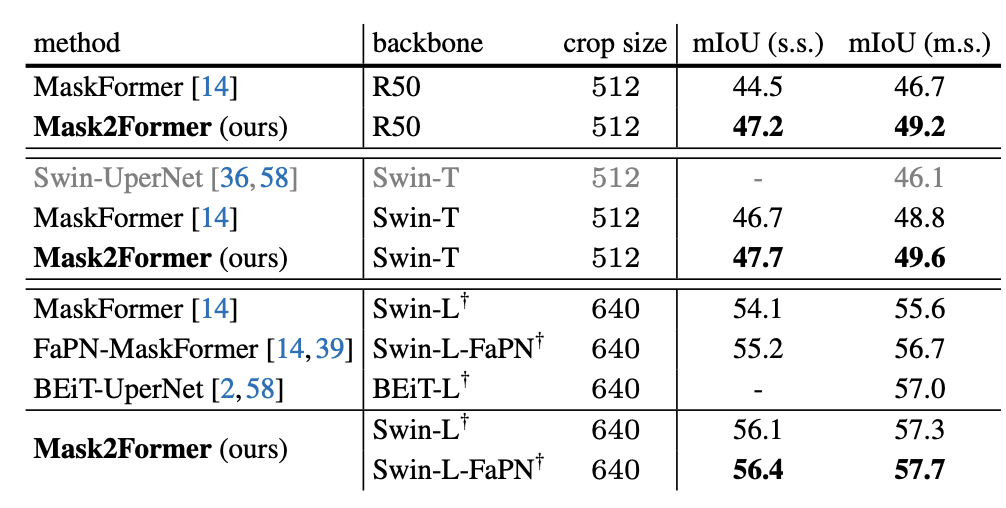
실험 결과

개발을 잘하고싶은 개발자