Introduction
- 일반적인 모델들은 Segmentation을 진행할 때 픽셀 단위로 진행하는데, 저자는 Mask를 기준으로 진행
- mask를 이용한 분류는 인스턴스 레벨 segmentation에서도 좋은 성능을 보임
- 일반적인 segmentation 모델들은 인스턴스, 팬옵틱 segmentation 에서 1개 클래스에 대한 결과만 보여짐
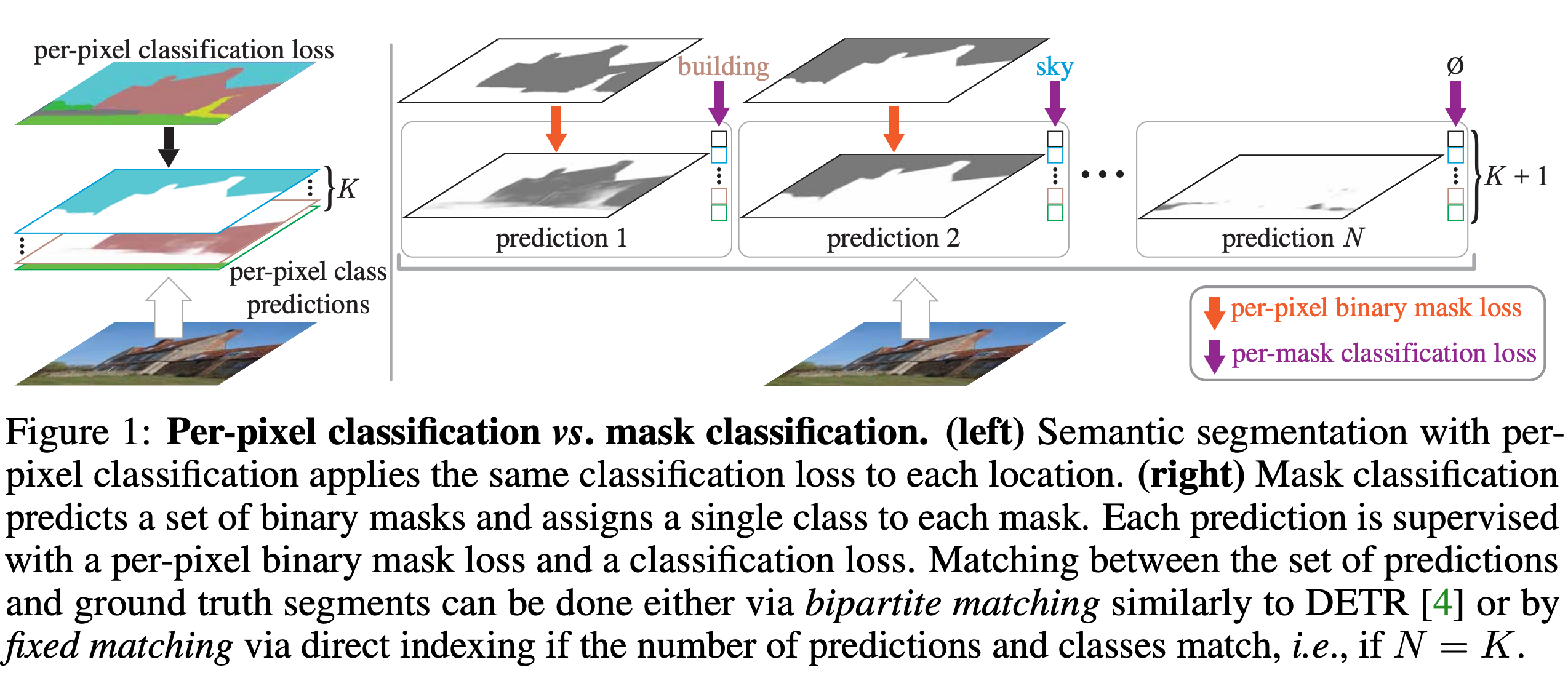
Key observation
- semantic, instance segmentation 둘다 효과적으로 처리 가능하며, 실제로 FCN 모델이 나오기 전에는 O2P, SDS 같은 마스크 분류 수식을 사용했음 → 의문점 1 : 단일 마스크 분류 모델이 semantic, instance segmentation 에서 효과적인 방법인지? → 의문점 2: 마스크 분류 모델은 현존하는 semantic segmentation 을 위한 픽셀 단위 분류보다 나을 수 있는지?
현존하는 픽셀 단위 분류 모델을 원활하게 마스크 분류 모델로 바꿀 수 있는 MaskFormer를 제안
DETR에서 제안된 set prediction mechanism 을 사용하면서, MaskFormer는 쌍들의 집합을 비교하기 위해 클래스 추론 결과와 마스크 임베딩 벡터로 각각 구성된 트랜스포머 디코더를 사용함
마스크 임베딩 벡터는 fully-convolutional network 에서 얻은 픽셀 단위 임베딩과 dot product 를 통해 이진화 마스크 추론 결과를 얻는게 사용됨
기존 모델에 변화를 주지 않고 픽셀 단위 이진화 마스크 loss 와 마스크별 단일 분류 loss를 사용하는 MaskFormer는 기존의 task에 맞춰진 추론 결과에 MaskFormer 결과를 섞는 추론 전략을 설계함
MaskFormer 는 클래스 수가 많을 수록 더 좋은 성능을 나타냄
단일 클래스 추론 에서도 Swin-transformer backbone을 사용해서 ADE20K 데이터셋에서 SOTA를 달성함
From Per-Pixel to Mask Classification
-
Per-pixel classification formulation
- H * W 사이즈의 모든 픽셀에 대해서 클래수 갯수 만큼의 확률 분포를 추론
- 일반적으로 cross entropy loss를 사용
-
Mask classification formulation
-
N 개 구역으로 이미지를 나누거나 그룹화하고 이진화 마스크로 나타냄
-
K개의 클래스에 대한 일부 분포와 각각의 영역 전체를 묶어줌(?)
-
no object(∅) 레이블을 통해서 K 개의 클래스에 일치하지 않는 부분을 표시함
-
mask classification 은 semantic, instance segmentation 에 적용할 수 있도록 같은 associated class에 대해 다수의 마스크 추론 결과를 허용함
→ GT 보다 추론 결과가 일반적으로 다르기 때문에, 저자는 추론 결과의 사이즈가 GT 보다 크다고 가정하고 no label을 넣어서 1대1 매칭이 되도록 함
-
bipartite matching > fixed matching
→ DETR 은 bbox를 이용하여 비교를 하지만, 저자는 class 와 mask 추론 결과를 바로 사용함

-
loss 수식
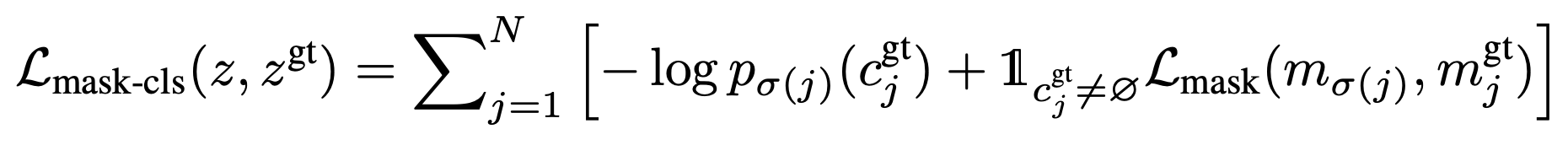 → Composed of a cross-entropy classification loss and a binary mask loss for each predicted segment
→ Composed of a cross-entropy classification loss and a binary mask loss for each predicted segment
-
-
MaskFormer
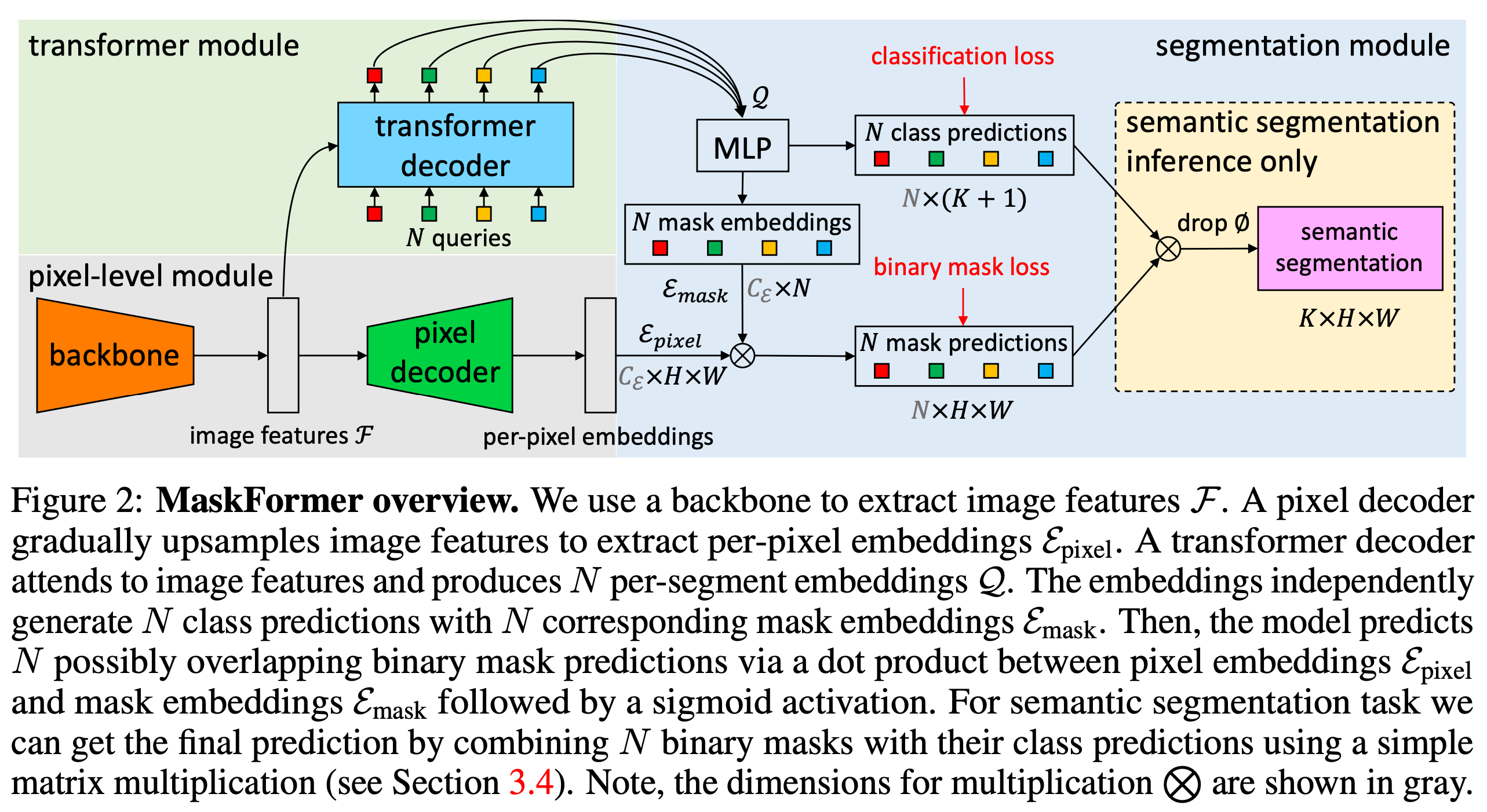
-
Pixel-level module
- backbone generates low-resolution image feature map
- = number of channels
- = stride of the feature map (use 32 in this paper)
- pixel decoder 는 픽셀별 임베딩들을 만들기 위해 feature 들을 업샘플링 함
- = embedding dimension
- 최신 모델을 포함한 픽셀 별 분류 기반 segmentation 모델은 pixel-level module 과 적합함
- backbone generates low-resolution image feature map
-
Transformer module
- 표준 Transformer decoder를 사용하여 image features 와 개의 학습 가능한 positional embedding 을 비교하고, 그 결과로 MaskFormer가 추론한 각각의 segment 에 대해서 글로벌 정보를 인코딩하는 차원 일 때, 에 속하는 를 개의 각각 segment embedding 이 나옴
- : 각 임베딩 벡터의 차원 수
- : 각 임베딩 벡터의 개수
- decoder 는 모든 추론을 병렬적으로 처리함
- 표준 Transformer decoder를 사용하여 image features 와 개의 학습 가능한 positional embedding 을 비교하고, 그 결과로 MaskFormer가 추론한 각각의 segment 에 대해서 글로벌 정보를 인코딩하는 차원 일 때, 에 속하는 를 개의 각각 segment embedding 이 나옴
-
Segmentation module
-
선형 분류기와 softmax 활성화 함수를 사용하여 segment 별 임베딩 Q 위에서 클래스 확률 분포 추론 결과 를 생성함
주의할 점
- 분류기는 임베딩이 어느 지역에도 일치하지 않는 경우 no label 로 추론함
-
마스크 추론을 위해서, 2개의 은닉층을 가진 MLP 가 각각의 세그먼트 임베딩들인 를 에 속하는 개의 마스크 임베딩 으로 변환 함
-
결과적으로, 각각의 이진화 마스크 추론 결과 를 마스크 임베딩과 pixel-level module로 계산한 픽셀 별 임베딩 을 dot product 하여 얻음
- dot product는 sigmoid 활성화 함수에 이어서 나옴
→
주의할 점- 경험적으로, softmax 활성화 함수를 사용함에 따라서 마스크 추론이 서로 상호 배타적이 되도록 강제하지 않는 것이 좋다고 확인함
- dot product는 sigmoid 활성화 함수에 이어서 나옴
-
학습하는 동안, loss는 cross entropy classification loss 와 각각의 예측된 segment 를 위한 이진화 마스크 loss 인 를 합침
-
단순화를 위해서, DETR 의 focal loss 와 dice loss 의 linear combination 에 각각 하이퍼 파라미터 와 를 곱해져 있는 를 사용함
-
-
-
Mask-classification inference
- General inference → mask classification 결과를 panoptic 또는 semantic segmentation 결과 포맷으로 변환하는 과정
- 직관적으로, 이 과정은 위치에 존재하는 픽셀에 가장 비슷한 클래스 확률 과 가장 높은 마스크 추론 확률 을 가졌을 때 probability-mask pair 를 할당함
- 동일한 확률 마스크 쌍을 할당받은 픽셀은 레이블 되어있는 segment 를 형성함
- semantic task 의 경우 같은 레이블들 달고 있는 픽셀은 하나로 합쳐지고, instance task 의 경우 라는 인덱스로 같은 클래스내에서 구별할 수 있도록 사용됨
- Panoptic task 에서 False positive 를 줄이기 위해서 confidence 가 낮은 추론을 필터링하고, 다른 추론에 의해 가려진 이진화 마스크의 많은 부분을 포함하고 있는 추론된 segment 를 제거함
- Semantic inference → semantic segmentation 을 위해서 만들어진 과정
- 간단한 행렬 곱셈으로 이루어짐
- 확률 마스크 쌍에 대해서 marginalization(주변화? → 마진 준다는 의미인듯?) 을 적용하는 것이 일반적인 추론보다 더 좋은 결과가 나오는 것을 경험적으로 확인함
- no label 을 포함하고 있지 않은 이유는 semantic task 에서는 모든 픽셀이 label 을 가져야하기 때문임
- 결과로 픽셀 별 클래스 확률이 나오는데, 픽셀별 클래스를 직접적으로 최대화 하는 것은 성능이 안좋게 나온다는 것을 확인함
- Gradients 가 모든 쿼리에 고르게 분포되어 훈련을 복잡하게 만든다고 가정함
- General inference → mask classification 결과를 panoptic 또는 semantic segmentation 결과 포맷으로 변환하는 과정
실험 결과
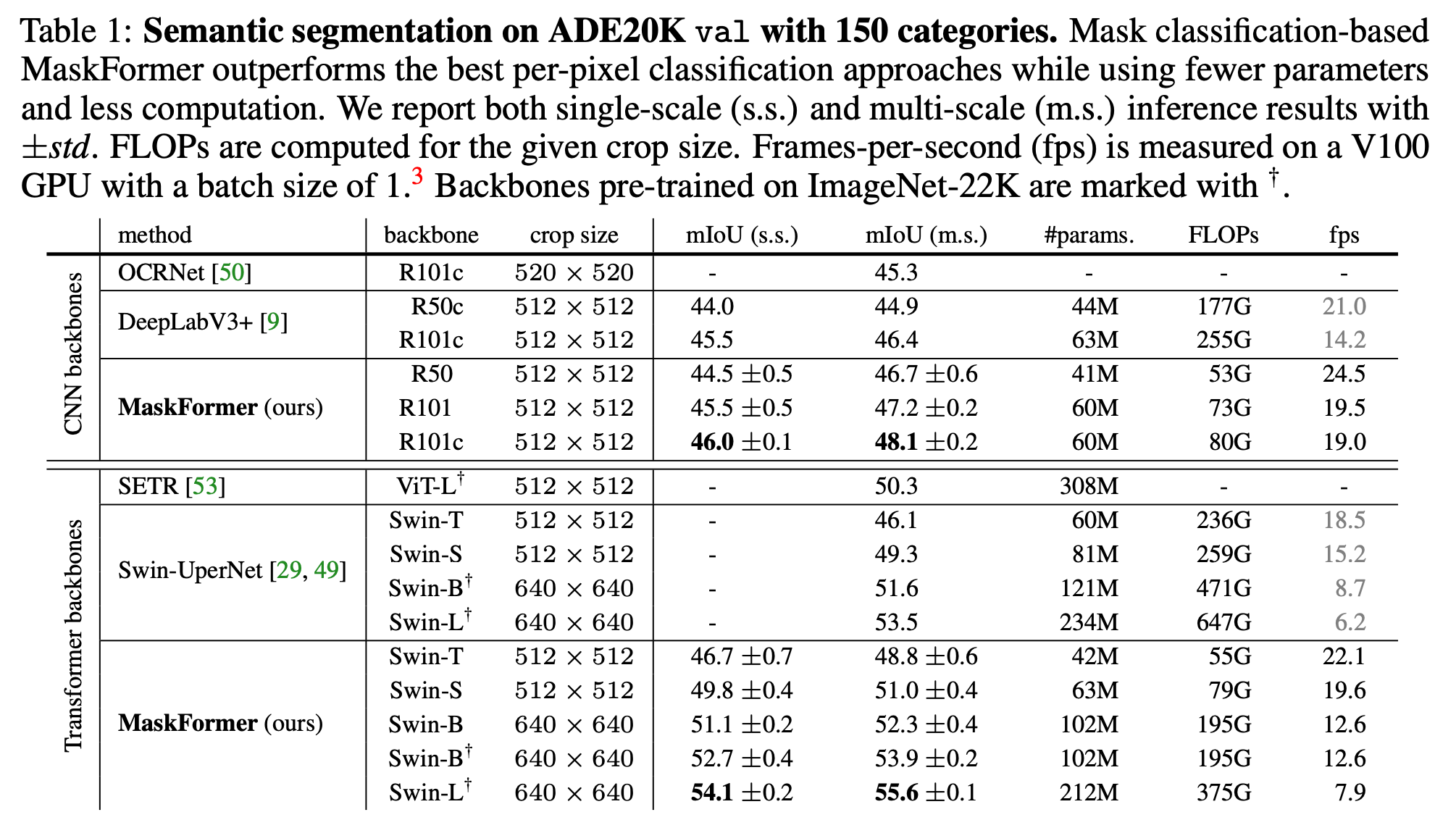
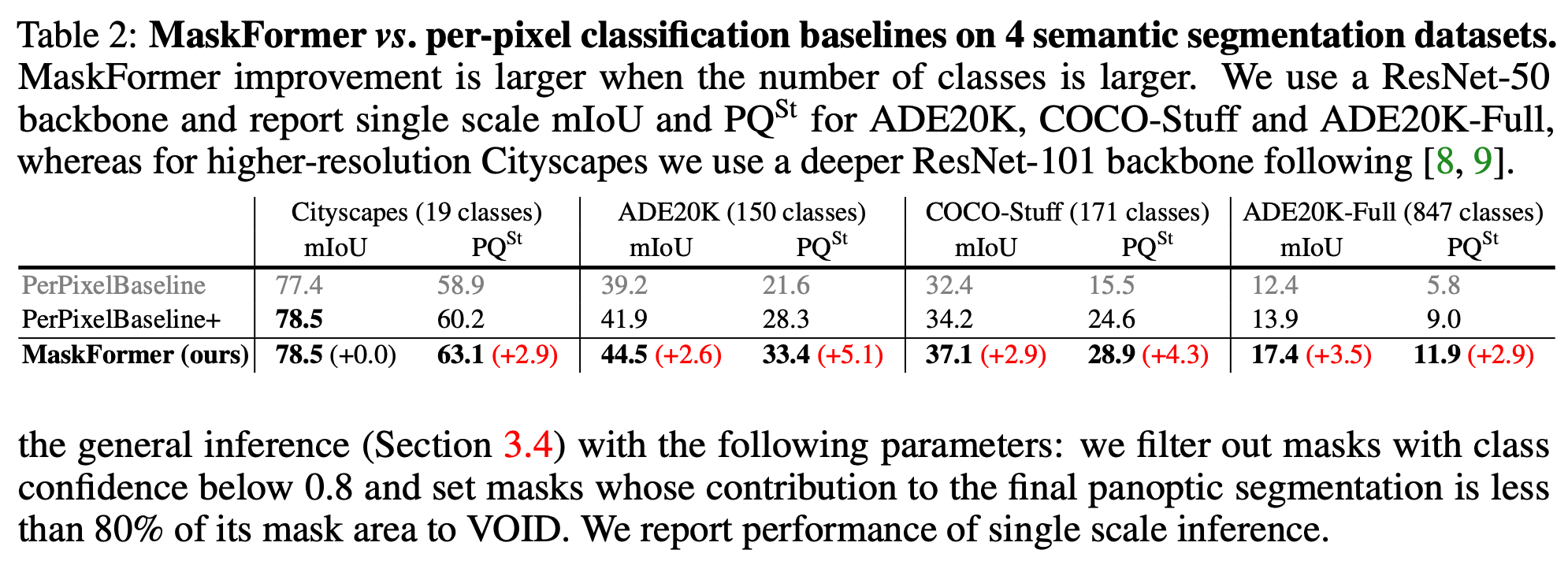
결과 정리
- ADE20K val set 에서 같은 CNN backbones (e.g., ResNet)을 사용하면 MaskFormer 가 DeepLabV3+ 보다 1.7 mIoU 가 더 높게 나옴
- MaskFormer 는 Vision Transformer backbone(e.g., Swin-transformer) 들이랑 경쟁 가능한 정도인 55.6 mIoU 가 나오는데, 이 점수는 prior SOTA 모델보다 2.1 점 높은 수치
- 데이터셋마다 다르지만, mIoU가 높아지지 않는 Cityscapes 데이터셋의 경우 점수가 2.9 가량 높아짐
- 픽셀별 segmentation quality 에선 부족하지만 recognition quality () 에서 더 좋은 결과를 보이는 것을 확인함
