Setting up your Machine Learning Application
Train / Dev / Test sets
좋은 고성능 신경망을 빨리 찾을 수 있도록 돕는 다음과 같이 결정해야 할 것들
- of layer
- of hidden unit
- Learning Rate
- Activation Function
- ....
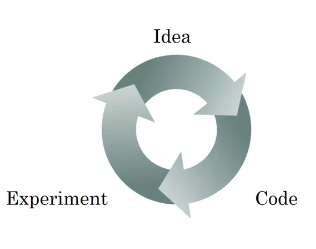
새 응용 프로그램을 시작할 때 올바른 응용 프로그램을 사용하는 것은 거의 불가능하다
매우 반복적인 프로세스
- Idea
- 신경을 만들고자 하는 것과 같은 아이디어로 시작
- 특정한 수의 계층, 특정한 수의 숨겨진 단위의 네트워크, 특정 데이터 세트
- Code
- 코드를 실행- Experiment
- 실험을 실행
- 결과에 따라 아이디어를 개선
더 나은 그리고 더 나은 신경망을 찾습니다. 오늘날, 딥 러닝은 발견했습니다 자연어에 이르기까지 많은 분야에서 큰 성공 프로세싱, 컴퓨터 비전, 음성 인식, 많은 부분에구조화된 데이터에도 응용됩니다. 그리고 구조화된 데이터는 모든 것을 포함합니다
Train/Dev/Test Set
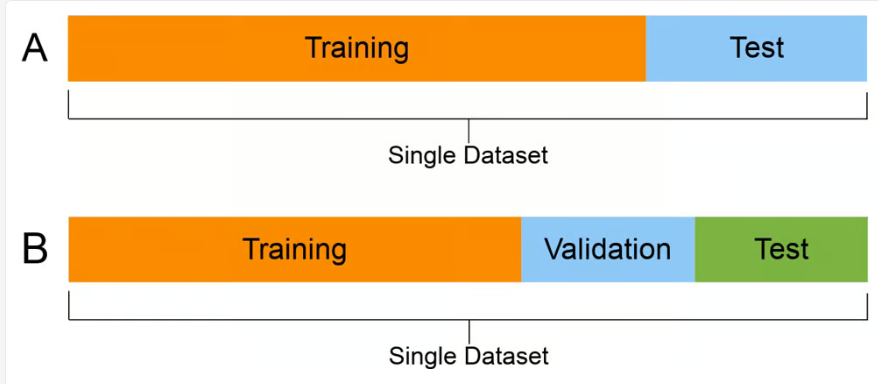
출처: https://dev.to/isholafaazele/train-test-and-dev-sets-59jh
데이터 세트를 잘 설정하면 테스트 세트를 사용해 훨씬 더 효율적으로 작업할 수 있습니다
머신 러닝의 이전 세대에는 모든 데이터를 가져 와서 70/30%로 분할하는 것이 일반적
60% 훈련 20% 개발 및2 0% 테스트 측면에서 분할하는 것이 일반적으로 간주되었다.
현대의 빅 데이터시대에는 개발 및 테스트 세트가 전체에서 훨씬 더 작은비율이 되고 있는 추세입니다 train 98%,dev 1%,test 1%가 필요
Bias / Variance
기계 학습 Bias 및 Variance이 실무자는 Bias Variance에 대해 매우 수준높은 이해를 하는 경향이 있습니다 쉽게 배울 수 있지만 마스터하기 어려운개념 중 하나
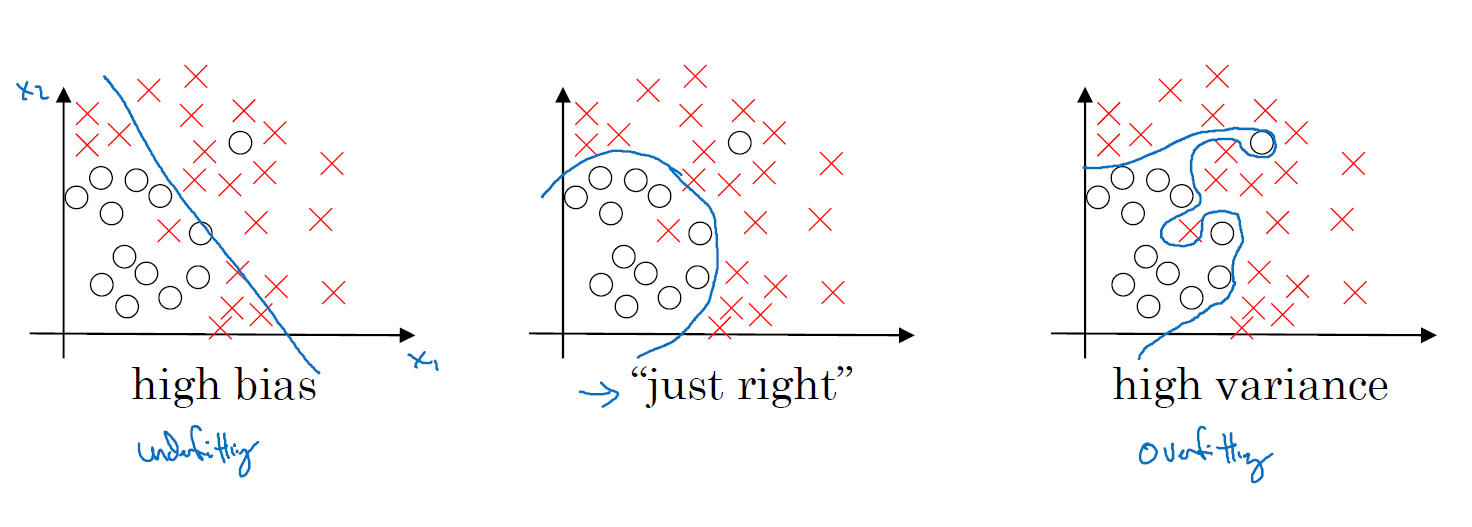
첫번째 그래프(로지스틱 회귀)는 데이터에 매우 적합하지 않다 - high bias
세번째 그래프(심층 신경망)는 과적합됐다. - high Variance
이 둘의 중간값인 두번째 그래프가 게이터에 훨씬 적압해 보인다.
단 두 가지 특징으로, X-1과 X-2라는 두 가지 기능만 있으면 데이터를 플로팅하고 바이어스와 분산을 시각화할 수 있습니다 고차원 문제에서는, 데이터를 플롯하고 분할 경계를 시각화할 수 없습니다

Trainig set error가1%이고 Dev set error는, 그러면 논쟁을 위해, 11%라고 가정이 예제에서는 train set에서는 매우 잘 하고 있지만, dev set에서는 상대적으로 저조합니다 그래서 이것은 여러분이훈련 세트를 과적합한 것 같습니다 어떻게 든 dev set와 함께 이 홀드아웃 교차 검증 세트를잘 일반화하지 못하고 있다는 것입니다 따라서 이와 같은 예가 있는 경우, 우리는 이것에 분산이높다고 말할 수 있습니다 - High Variance
Trainig set error가 15%라고 가정해 보겠습니다 저는 맨 윗줄에 여러분의 Trainig set error를 쓰고 있는데, 여러분의 Dev set error는 16%입니다. 이 경우 인간이 대략 0%의오차를 달성한다고 가정하면, 인간은 이 사진을 보고 고양이인지 아닌지 알 수 있습니다 그러면 알고리즘이 Trainig set에서 잘 작동하지 않는 것처럼 보입니다 따라서 잘 보이는 것처럼 훈련 데이터에도 적합하지 않은 경우, 그러면 데이터가 과소적합됩니다 그래서 이 알고리즘은 높은 바이어스를 가지고 있습니다 - high Bias
15% Trainig set error가 있다고 가정해 보겠습니다 따라서 그것은 상당히 높은 바이어스입니다 그러나 여러분이 Dev set로 평가하면 더 나빠집니다 아마도, 여러분도 아시다시피 30% 정도일 것입니다 이 경우 이 알고리즘은 Trainig set에서 잘 수행되지 않고 바이어스가 높기 때문에 high Bias로 진단합니다 그래서 이것은 최악의 상황을 모두 가지고 있습니다 - High Variance & high Bias
Basic Recipe for Machine Learning
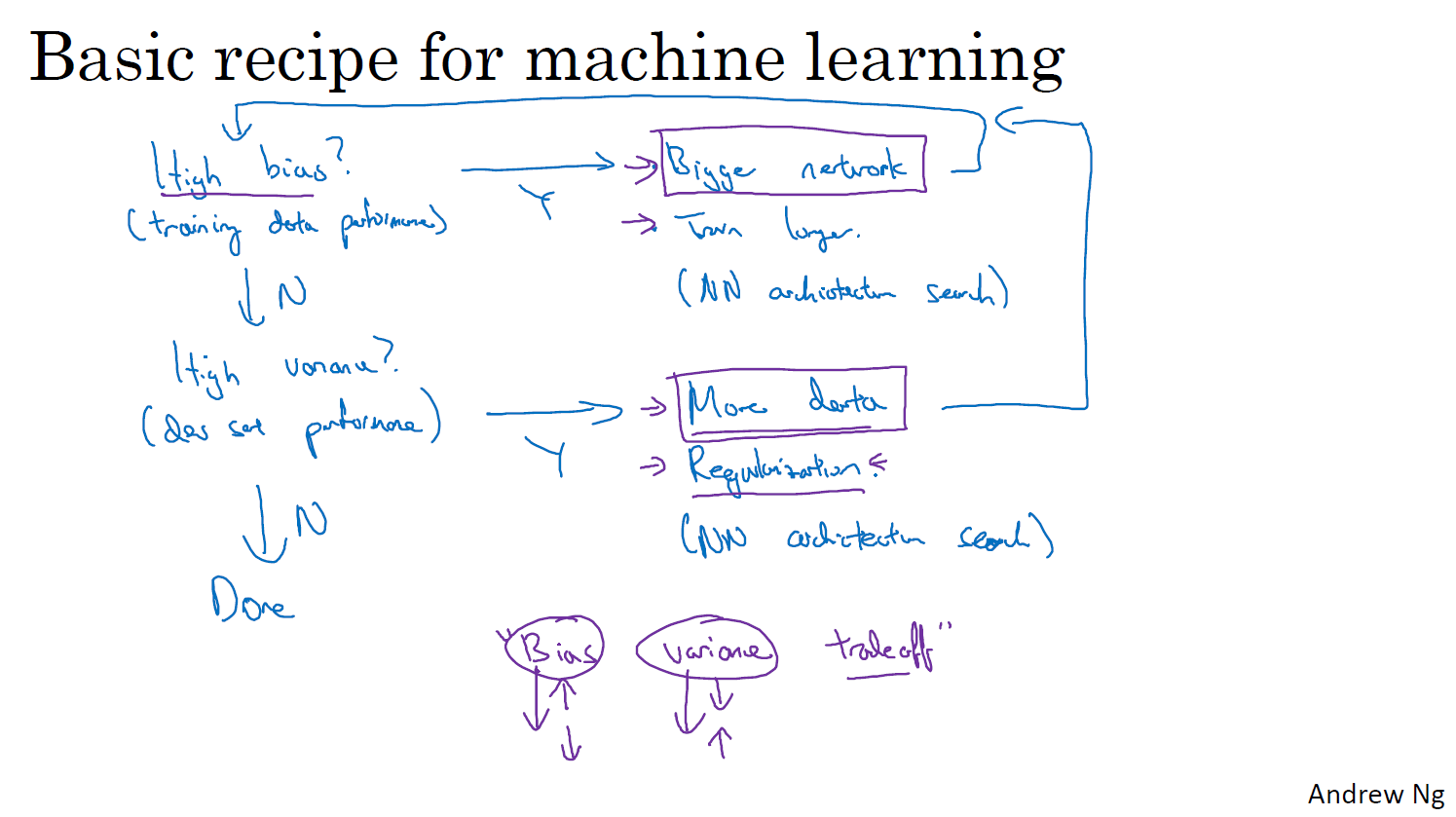
알고리즘에 high Bias가 있는가?
훈련 세트나 훈련데이터 성능을 살펴봐야 합니다 훈련 세트에 잘 맞지않거나 더 오래 훈련할 수 있고, 시도할 수 있는 몇 가지 방법은 네트워크를 선택하는 것인데요, 예를 들어, 더 많은 은닉계층이나 더 많은 은닉 유닛이 있고, 훈련을 더 오래 실행하거나, 여러분도 아시다시피, 더 고급 최적화 알고리즘을 시도할 수 있습니다 더 큰 네트워크를 얻는것이 거의 항상 도움이 되고,
더 오래 훈련하는 것이항상 도움이 되는 것은 아닙니다
바이어스를 허용 가능한만큼 줄였다면, High Variance가 있나요?
고분산 문제를 해결하는 가장좋은 방법은 더 많은 데이터를 얻는 것이다. 그러나 때때로 더 많은데이터를 얻을 수 없습니다 > 정규화, 더 적절한 신경망아키텍처
high Bias 또는 High Variance이 있는지 여부에 따라, 시도해야 하는 항목의집합은 상당히 다를 수 있습니다 그래서 저는 일반적으로 훈련 개발 세트를 사용하여 Bias 또는 Variance이 문제가있는지 진단하려고 시도합니다 다음 적절하게 정규화하는 한 반드시 여러분의 분산을 손상시키지 않으면서 편향을 줄입니다 거의 항상 더 큰네트워크를 얻을 수 있습니다 그리고 더 많은데이터를 얻으면서, 거의 항상 분산을 줄이고 Bias를 크게 해치지 않습니다
