이 글은 김기현의 딥러닝을 활용한 자연어생성 올인원 패키지 Online.
을 참고하여 만들어 졌습니다.
beam search 알고리즘은 seq2seq에서 transformer로 넘어가는 수준의 성능 향상을 보여주었다.
대부분의 이론설명에서는 mini batch 하나하나 beam search를 적용하는 예시로 설명하지만 실제로 그렇게 할 경우 추론 시간이 너무 길어지기 때문에 실제 학습에서는 parallel하게 진행한다.
본 글의 model은 transformer입니다.
transformer.py/beam_search
# |x[0]| = (bs, n) data
# |x[1]| = (bs,) length
batch_size = x[0].size(0)
n_dec_layers = len(self.decoder._modules)
mask = self._generate_mask(x[0], x[1])
# |mask| = (bs, n)
x = x[0]
# |mask_enc| -> (bs, n) -> (bs, 1, n) -> (bs, n, n)
mask_enc = mask.unsqueeze(1).expand(mask.size(0), x.size(1), mask.size(-1))
# |mask_dec| -> (bs, n) -> (bs, 1, n)
mask_dec = mask.unsqueeze(1)
z = self.emb_dropout(self._position_encoding(self.emb_enc(x)))
z, _ = self.encoder(z, mask_enc)
# |z| = (bs, n, hs)
여기까지는 일반적인 search와 동일하게 encoder의 output인 z를 얻어온다.
transformer.py/beam_search
prev_status_config = {}
for layer_index in range(n_dec_layers + 1):
prev_status_config[f'prev_state_{layer_index}'] = {
'init_status': None,
'batch_dim_index': 0,
}
# Example of prev_status_config:
# prev_status_config = {
# 'prev_state_0': {
# 'init_status': None,
# 'batch_dim_index': 0,
# },
# 'prev_state_1': {
# 'init_status': None,
# 'batch_dim_index': 0,
# },
#
# ...
#
# 'prev_state_${n_layers}': {
# 'init_status': None,
# 'batch_dim_index': 0,
# }
# }
boards = [
SingleBeamSearchBoard(
z.device,
prev_status_config,
beam_size=beam_size,
max_length=max_length,
) for _ in range(batch_size)
]
done_cnt = [board.is_done() for board in boards]
length = 0search.py/__init__
self.beam_size = beam_size
self.max_length = max_length
self.device = device
self.word_indice = [torch.LongTensor(beam_size).zero_().to(self.device) + data_loader.BOS]
self.beam_indice = [torch.LongTensor(beam_size).zero_().to(self.device) - 1]
self.cumulative_probs = [torch.FloatTensor([.0] + [-float('inf')] * (beam_size - 1)).to(self.device)]
self.masks = [torch.BoolTensor(beam_size).zero_().to(self.device)] # eos를 뱉었으면 1 아니면 0
self.prev_status = {}
self.batch_dims = {}
for prev_status_name, each_config in prev_status_config.items():
init_status = each_config['init_status']
batch_dim_index = each_config['batch_dim_index']
if init_status is not None:
self.prev_status[prev_status_name] = torch.cat([init_status] * beam_size, dim=batch_dim_index)
else:
self.prev_status[prev_status_name] = None
self.batch_dims[prev_status_name] = batch_dim_index
self.current_time_step = 0
self.done_cnt = 0prev_status_config를 선언해준다. prev_status_config는 각 레이어층의 출력이 저장될 곳의 초기값이다.
decoder
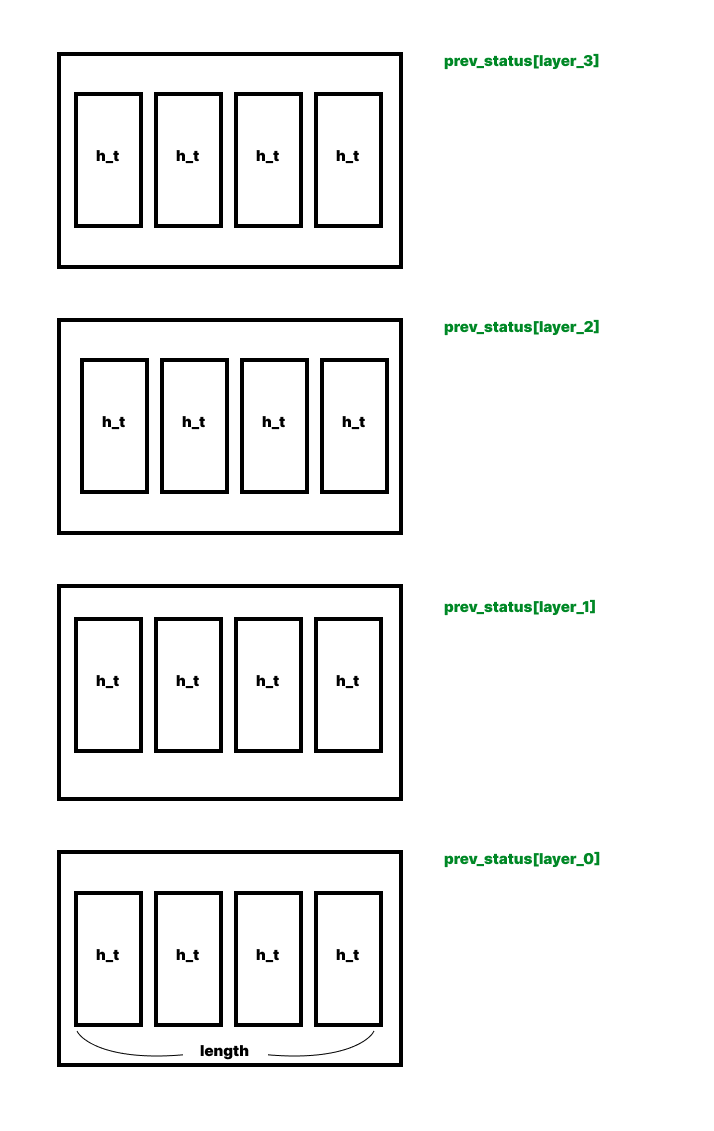
각 레이어층에 이전 타임스텝의 출력이 차곡차곡 쌓이게 된다.
layer_0은 input이 저장되는 곳이다.
batch size만큼 board를 만들어준다. board 생성과정에서 prev_status_config는 init_status와 batch_dim_index가 나눠진다.
나는 데이터의 shape가 전부 (batch_size, ~, ~)이런 식이므로 batch_dim_index는 전부 0이다
board선언부분을 더 알아보자면
word_indice는 beam안에서 채택된 단어의 index
beam_indice는 그 index가 몇번째 beam에 있는지를 저장한다.
둘다 각 타임스텝에서의 값이 전부 저장된다.
beam
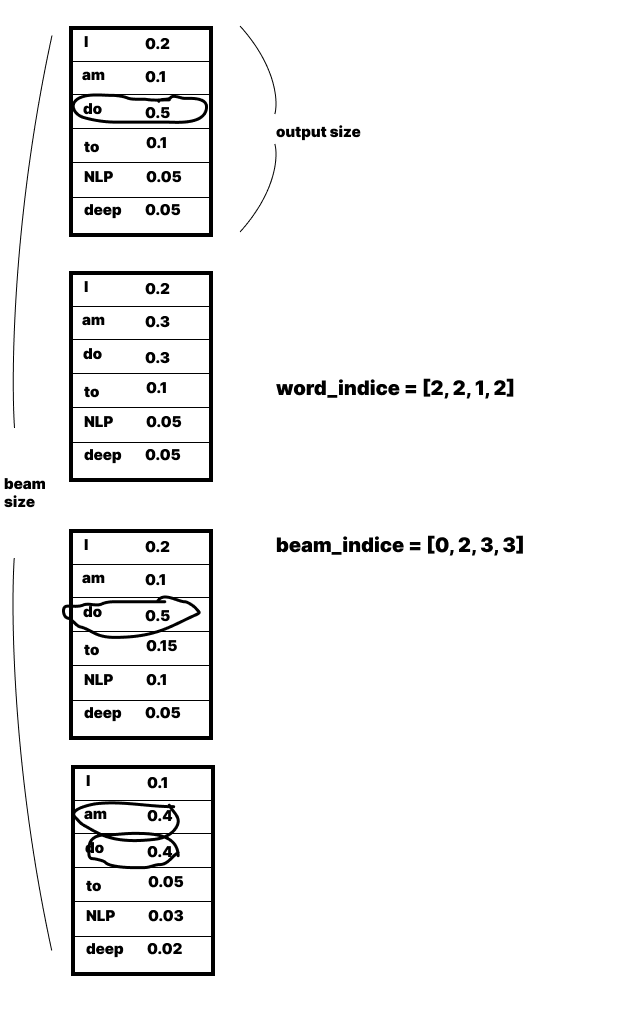
cumulative_probs는 각 word_indice에 뽑힌 단어들의 확률값을 누적(plus)하여 각 타임스텝마다 차곡차곡 저장한다.
또 cumulative_probs의 초기값이 [0,-inf * (beam_size-1)]인데 이는 후에 첫 타임스텝에서 cumulative_probs[-1]의 shape를 expand할때 첫번째 beam만 보게 해주기 위함이다.(어짜피 첫번째 타임스텝에선 모든 beam에서 단어들의 각 확률값이 같을 것이기 때문..)
masks는 eos를 출력한 beam을 가려주는 역할을한다.
current_time_step은 말그대로 현재 몇번째 타임스텝인지 알려주는 역할이고
search.py/is_done
def is_done(self):
if self.done_cnt >= self.beam_size:
return 1
return 0done_cnt는 beam이 eos를 출력할때 마다 하나씩 늘어나는데 done_cnt가 beam과 같아질때 해당 board는 종료된다.
transformer.py/beam_search
while sum(done_cnt) < batch_size and length <= max_length:
fab_input, fab_z, fab_mask = [], [], []
fab_prevs = [[] for _ in range(n_dec_layers + 1)]
# 각 미니배치 하나의 입력, z(인코더의 아웃풋), mask를 beam_size만큼 복제시킴
for i, board in enumerate(boards): # i == sample_index in minibatch
if board.is_done() == 0:
y_hat_i, prev_status = board.get_batch()
# |y_hat_i| = (beam_size, 1)
# |prev_status_i| = (beam_size, length, hidden_size) i is layer index
fab_input += [y_hat_i]
fab_z += [z[i].unsqueeze(0)] * beam_size
fab_mask = [mask_dec[i].unsqueeze(0)] * beam_size
# 각 board의 prev_state를 fab_prevs에 추가
for layer_index in range(n_dec_layers + 1):
prev_i = prev_status[f'prev_state_{layer_index}']
if prev_i is not None:
fab_prevs[layer_index] += [prev_i]
else:
fab_prevs[layer_index] = None다시 transformer.py로 돌아와
먼저 while문의 반복한번은 한 타임스텝이다.
따라서 done_cnt(각 board가 끝났는지 아닌지)의 sum이 batch_size와 같아지면 모든 추론이 끝났단 것이므로 끝나고
time_step인 length가 지정한 max_length를 넘어갈 경우에도 끝이난다(오류방지)
다음으로 아래 for문은 각 보드마다 즉 batch_size만큼
이전 타임스텝의 최종 출력 값 즉 채택된 단어들인 y_hat_i와
encoder의 최종output z와(encoder-decoder attention layer에서 필요함)
decoder-encdoer layer에서 z에서 씌울 mask를 만든다.
search.py/get_batch
def get_batch(self):
y_hat = self.word_indice[-1].unsqueeze(-1)
# |y_hat| = (beam_size, 1)
# if model != transformer:
# |hidden| = |cell| = (n_layers, beam_size, hidden_size)
# |h_t_tilde| = (beam_size, 1, hidden_size) or None
# else:
# |prev_state_i| = (beam_size, length, hidden_size),
# where i is an index of layer.
return y_hat, self.prev_statusword_indice[-1] 즉 이전 타임스텝에서 채택된 단어를 가져온다.
prev_status는 위 decoder사진,설명 참고.
그리고 is not None, is None같은 부분은 첫 타임스텝을 가려내기 위함이라 생각하면 된다.
transformer.py/beam_search
# concatenation current_batch_size = beam_size * batch_size
fab_input = torch.cat(fab_input, dim=0)
fab_z = torch.cat(fab_z, dim=0)
fab_mask = torch.cat(fab_mask, dim=0)
for i, fab_prev in enumerate(fab_prevs): # i == layer_index
if fab_prev is not None:
fab_prevs[i] = torch.cat(fab_prev, dim=0)
# |fab_input| = (current_batch_size, 1,)
# |fab_z| = (current_batch_size, n, hidden_size)
# |fab_mask| = (current_batch_size, 1, n)
# |fab_prevs[i]| = (current_batch_size, length, hidden_size)
# len(fab_prevs) = n_dec_layers + 1parellel한 연산을 위해 위에 batch_size만큼 가져온 값들을 concat한다. 따라서 각 batch마다 beam_size 만큼 있으므로
추론 연산할때 batch_size는 current_batch_size = batch_size * beam_size가 된다.
transformer.py/beam_search
h_t = self.emb_dropout(
self._position_encoding(self.emb_dec(fab_input), init_pos=length)
)
# |h_t| = (current_batch_size, 1, hs)
if fab_prevs[0] is None:
fab_prevs[0] = h_t
else:
fab_prevs[0] = torch.cat([fab_prevs[0], h_t], dim=1)
for layer_index, block in enumerate(self.decoder._modules.values()):
prev = fab_prevs[layer_index]
# |prev| = (current_batch_size, m, hs)
h_t, _, _, _, _ = block(h_t, fab_z, fab_mask, prev, None)
# |h_t| = (current_batch_size, 1, hs)
if fab_prevs[layer_index + 1] is None:
fab_prevs[layer_index + 1] = h_t
else:
fab_prevs[layer_index + 1] = torch.cat(
[fab_prevs[layer_index + 1], h_t],
dim=1
) # 각 층마다 출력 hidden state를 append해줌
y_hat_t = self.generator(h_t)
# |y_hat_t| = (current_batch_size, 1, output_size)이제 진짜 추론을 할 시간이다.
먼저 input을 embedding, positional encoding 그리고 dropout을 적용해줘 decoder에 넣기 좋게 만들어준다.
for문 들어가기전 보이는 if문은 입력이 저장되는 곳인 layer0에 input을 concat해주는 곳이다.
그리고 이제 for문이 decoder가 layer한 층씩 돌아가는 곳이다. 한 줄씩 살펴보자.
fab_prevs에는 각 layer마다 이전 타임스텝까지의 출력들이 들어가 있을것이다. 그중 현재 layer의 값을 가져온다.
그리고 decoder에 이번에 넣어줄 입력 h_t와 encoder의 K, V인 fab_z 그런 z에 적용할 mask과 현재 층에서의 이전 타임스텝까지의 출력을 넣어준다. look_ahead_mask는 추론에서는 어짜피 다음 타임스텝의 값이 없으므로 필요없다.
그렇게 해서 나온 출력은 다음 레이어의 input으로 들어갈테니 현재 layer + 1에 concat한다.
그리고 최종 출력을 generator에 넣어준다.
transformer.py/beam_serach
# |fab_prevs[i][begin:end]| = (beam_size, length, hs)
cnt = 0
for board in boards:
if board.is_done() == 0:
begin = cnt * beam_size
end = begin + beam_size
prev_status = {}
for layer_index in range(n_dec_layers + 1):
prev_status[f'prev_state_{layer_index}'] = fab_prevs[layer_index][begin:end]
board.collect_result(y_hat_t[begin:end], prev_status)
cnt += 1
done_cnt = [board.is_done() for board in boards]
length += 1아까 위에서 while문의 반복 한번이 한 타임스텝이라 했다.
이제 이번 타임스텝을 마무리하기 위해 board들에 이번 나온 값들을 정리하고 또 board에서 끝난 beam은 있는지 없는지 그리고 모든 beam이 eos를 출력해 끝난 board는 없는지 확인할 것이다.
먼저 current_batch_size에서 한 board만 갖고오기 위한 begin, end를 구할것인데 current_batch_size로 concat할때 각 board의 순서대로 concat했었으므로 0~beam_size, beam_size~beam_size*2... 마다 각 board의 값일 거다.
이를 이용해 각 board를 떼와서 collect_result를 한다.
search.py/collect_result
def collect_result(self, y_hat, prev_status):
# |y_hat| = (beam_size, 1, output_size)
# prev_status is a dict, which has following keys:
# if model != transformer:
# |hidden| = |cell| = (n_layers, beam_size, hidden_size)
# |h_t_tilde| = (beam_size, 1, hidden_size)
# else:
# |prev_state_i| = (beam_size, length, hidden_size),
# where i is an index of layer.
output_size = y_hat.size(-1)
self.current_time_step += 1
cumulative_prob = self.cumulative_probs[-1].masked_fill(self.masks[-1], -float('inf'))
cumulative_prob = y_hat + cumulative_prob.view(-1, 1, 1).expand(self.beam_size, 1, output_size)
# |cumulative_prob| = (beam_size, 1, output_size)
# torch.topk는 torch.sort보다 느림
# top_log_prob, top_indice = torch.topk(
# cumulative_prob.view(-1), # (beam_size * output_size, )
# self.beam_size,
# dim=-1
# )
# Following lines are using torch.sort, instead of using torch.topk.
top_log_prob, top_indice = cumulative_prob.view(-1).sort(descending=True)
top_log_prob, top_indice = top_log_prob[:self.beam_size], top_indice[:self.beam_size]
# |top_log_prob| = (beam_size)
# |top_indice| = (beam_size,)
self.word_indice += [top_indice.fmod(output_size)] # 한 beam안에서 몇번째 인덱스인지
self.beam_indice += [top_indice.div(float(output_size)).long()] # 몇번째 beam에 있는지
self.cumulative_probs += [top_log_prob]
self.masks += [torch.eq(self.word_indice[-1], data_loader.EOS)]
self.done_cnt += self.masks[-1].float().sum()
for prev_status_name, prev_status in prev_status.items():
self.prev_status[prev_status_name] = torch.index_select(
prev_status,
dim=self.batch_dims[prev_status_name],
index=self.beam_indice[-1]
).contiguous()
뭔가 굉장히 길어보이지만 주석을 빼면 사실 그리 길지않다.
그러므로 쫄지말고 같이 한줄씩 살펴보자.
먼저 cumulative_prob
cumulative_prob = self.cumulative_probs[-1].masked_fill(self.masks[-1], -float('inf'))cumulative_probs에서 바로 이전 타임스텝의 값을 가져와 끝난 beam이 있으면 mask를 적용해 확률 값을 -inf로 바꾼다.
cumulative_prob = y_hat + cumulative_prob.view(-1, 1, 1).expand(self.beam_size, 1, output_size)그리고 이번 타임스텝의 최종출력값인 y_hat을 더한다.
그러면 타임스텝이 지날수록 확률값이 커질것이다. 이점은 이따가 한번 더 얘기할것이니 기억해둬라.
그런다음 우리는 단어를 beam하나에서 단어하나를 뽑는게아닌 beam을 모두 연결해서 그중 가장 높은 단어를 beam_size만큼 뽑을 것이므로
top_log_prob, top_indice = cumulative_prob.view(-1).sort(descending=True)cumulative.view(-1)로 하나로 연결해주고 내림차순해준다.
top_log_prob, top_indice = top_log_prob[:self.beam_size], top_indice[:self.beam_size]그러면 가장 높은 확률값이 맨위에 있을 것이므로 위에서 beam_size만큼 잘라준다.
self.word_indice += [top_indice.fmod(output_size)] # 한 beam안에서 몇번째 인덱스인지
self.beam_indice += [top_indice.div(float(output_size)).long()] # 몇번째 beam에 있는지top_indice는 0~beam_size * output_size - 1의 값중 beam_size만큼 있을 것이다. 그래서 top_indice를 output_size로 나머지 연산을 하면 0~output_size - 1 중 beam_size개의 값이 나올거고
output_size로 나누면 0~beam_size - 1 중에 beam_size개만큼 값이 나올거다.
그런다음 나온 두값 word_indice, beam_indice를 append해준다.
self.cumulative_probs += [top_log_prob]
self.masks += [torch.eq(self.word_indice[-1], data_loader.EOS)]
self.done_cnt += self.masks[-1].float().sum()그리고 확률 값도 append해주고 만약 eos가 채택된 단어로 있는지 masks에 검사한다.
그리고 masks의 sum만큼 done_cnt에 더해준다.
그러면 나같이 멍청한사람은 어? 그러면 done_cnt에 계속 masks의 sum이 더해지니깐 eos가 beam_size만큼 나오기전에 끝나버리는거 아닌가? 생각할 수 있지만
다음 타임스텝에서 마스크 부분은 -inf로 채워져서 해당 beam은 무시하고 계속 진행하던 나머지 beam에서 여전히 beam_size만큼 뽑으므로 masks에서 1로 채워진 부분이 계속 1인것이 아니다.
필자는 이거때문에 다시 코드 따라가느라 시간좀 썼다.
for prev_status_name, prev_status in prev_status.items():
self.prev_status[prev_status_name] = torch.index_select(
prev_status,
dim=self.batch_dims[prev_status_name],
index=self.beam_indice[-1]
).contiguous()다음으로 prev_status를 저장하는 부분인데
prev_status_name에는 몇번째 layer인지 들어가게 된다. 즉, 각 층마다 채택된 단어가 있는 beam만 prev_status에 저장한다.
채택된 단어가 없는 beam은 버려지는 것이다.
transformer.py/beam_search
batch_sentences, batch_probs = [], []
for i, board in enumerate(boards):
sentences, probs = board.get_n_best(n_best, length_penalty=length_penalty)
batch_sentences += [sentences]
batch_probs += [probs]
return batch_sentences, batch_probs이제 마지막으로 문장을 생성하는 곳이다. 각 board 즉, mini batch마다 n_best만큼의 문장을 생성한다.
search.py/get_n_best
def get_n_best(self, n=1, length_penalty=.2):
sentences, probs, founds = [], [], []
for t in range(len(self.word_indice)):
for b in range(self.beam_size):
if self.masks[t][b] == 1:
probs += [self.cumulative_probs[t][b] * self.get_length_penalty(t, alpha=length_penalty)]
founds += [(t, b)]
for b in range(self.beam_size):
if self.cumulative_probs[-1][b] != -float('inf'):
if not (len(self.cumulative_probs) - 1, b) in founds:
probs += [self.cumulative_probs[-1][b] * self.get_length_penalty(
len(self.cumulative_probs),
alpha=length_penalty)]
founds += [(t, b)]
sorted_founds_with_probs = sorted(
zip(founds, probs),
key=itemgetter(1),
reverse=True
)[:n]
probs = []
for (end_index, b), prob in sorted_founds_with_probs:
sentence = []
# <eos>부터
for t in range(end_index, 0, -1):
sentence += [self.word_indice[t][b]]
b = self.beam_indice[t][b]
sentences += [sentence]
probs += [prob]하.. 또 뭔가 길다.
귀찮지만 한줄한줄 같이 살펴보자..
sentences, probs, founds = [], [], []먼저 sentences는 n개만큼 문장이 담길 곳이고 probs는 그 문장의 확률이 담길 곳이다.
founds는 eos가 나온 곳의 time step과 beam의 index가 담길곳이다.
for t in range(len(self.word_indice)):
for b in range(self.beam_size):
if self.masks[t][b] == 1:
probs += [self.cumulative_probs[t][b] * self.get_length_penalty(t, alpha=length_penalty)]
founds += [(t, b)]word_indice의 길이만큼 즉 타임스텝만큼 거기서 beam_size 즉 각 빔마다 if self.masks[t][b] == 1 마스크를 봐서 1이 있으면 해당 타임스텝 t에서 b번째 빔에서 문장하나가 완성 됐다는 소리이다.
그리고 probs를 가져오는데 위에서 얘기 했듯이 타임스텝이 길어질수록 확률이 늘어나므로 length penalty를 곱해준다.
search.py/get_length_penalty
def get_length_penalty(
self,
length,
alpha=LENGTH_PENALTY,
min_length=MIN_LENGTH,
):
# Calculate length-penalty,
# because shorter sentence usually have bigger probability.
# In fact, we represent this as log-probability, which is negative value.
# Thus, we need to multiply bigger penalty for shorter one.
p = ((min_length + 1) / (min_length + length)) ** alpha
return pmin_length와 length, alpha에 임의의 값을 넣어보면 (일반적으로 0~5, 100~255, 0~1) 넣으면 0~1사이의 값이 나온다.
length가 커질수록 더 작은 값이 나온다.
for b in range(self.beam_size):
if self.cumulative_probs[-1][b] != -float('inf'):
if not (len(self.cumulative_probs) - 1, b) in founds:
probs += [self.cumulative_probs[-1][b] * self.get_length_penalty(
len(self.cumulative_probs),
alpha=length_penalty)]
founds += [(t, b)]그리고 만약 운이 없으면 eos로 끝나지 않고 max_length로 끝나게 될텐데,
그걸 대비해 eos를 출력하지 않았고 아직 founds에 찾아지지 않은 문장의 경우에 probs와 founds에 넣는다.
일반적으로는 max_length에 걸리지 않을테니 하나만 -inf고 나머지는 어떤 확률값일 것이다.
그래서 founds와 probs에는 2*beam_size - 1개의 값이 들어가게 된다.
만약 운이 안좋아 max_length로 끝나게 된 경우엔 2*beam_size개 만큼 들어가 있을거다.
# Sort and take n-best.
sorted_founds_with_probs = sorted(
zip(founds, probs),
key=itemgetter(1),
reverse=True,
)[:n]그리고 가장 확률이 높은 n개를 뽑는다.
probs = []
for (end_index, b), prob in sorted_founds_with_probs:
sentence = []
# <eos>부터
for t in range(end_index, 0, -1):
sentence = [self.word_indice[t][b]] + sentence
b = self.beam_indice[t][b]
sentences += [sentence]
probs += [prob]
return sentences, probs그다음 probs를 비워준다음에 eos가 나온 인덱스는 t번째 타임스텝의 b번째 beam부터 단어 하나씩 돌아간다.
그런데 필자는 b를 구하는 부분이 이해가 가질 않아서 여기서 애좀 썼는데 나와 같은사람을 위해 그림으로 설명해주겟다.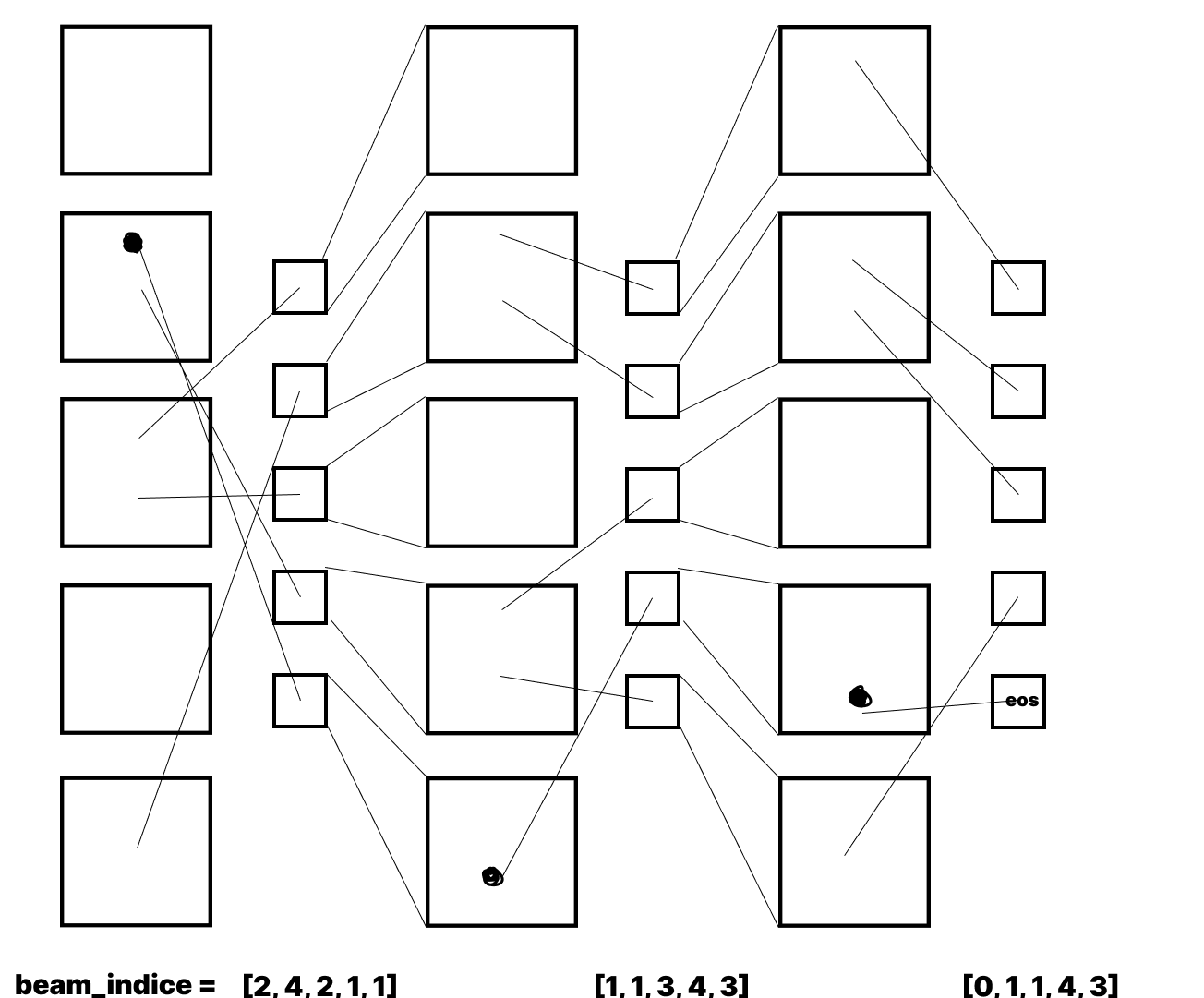
먼저 beam_indice는 사실 맨 첫,두 번째의 값은 0으로 꽉차 있는데 그림은 중간만 떼왔다고 가정하고 그렸다.
사진에서 eos의 founds는 (t,4)이다.
그러면 아래 beam_indice에 인덱스로 t,4가 들어가니 다음b는 3이 된다.
그럼 현재 인덱스는 (t-1,3)이 되고 이를 또 아래 beam_indice는 4가 나온다.
그렇게 계속 따라가다 보면 우리가 원하는 단어들이 나오게 된다.
이게 그림으로 보면 간단하지만, beam_indice가 채택된 단어들 사이에서도 확률이 높을수록 먼저 나오는것과 코드만 보고 머리로 생각하면 생각보다 이해가 잘가지 않는다.(필자가 멍청한걸 수도)
beam search의 parellel한 구현의 설명은 여기서 마무리 된다.
아무쪼록 독자들에게 도움이 됐으면 좋겠다.
