머신러닝 vs 전통적인 프로그래밍

즉, 절차과정을 인간이 직접 작성하는지의 여부에서 차이가 난다.
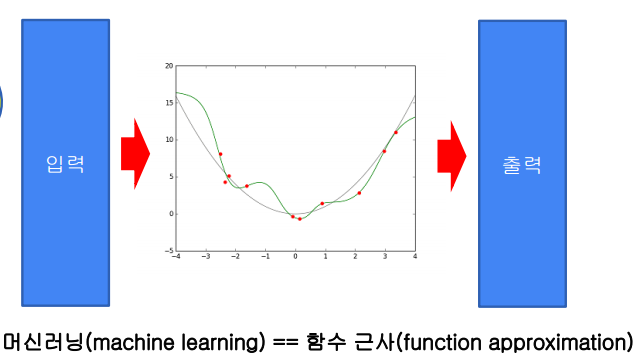
머신러닝이 그래서 뭘까?
머신러닝은 입력을 받아서 출력하는 함수 y=f(x)를 학습한다고 할 수 있다. (함수 근사)
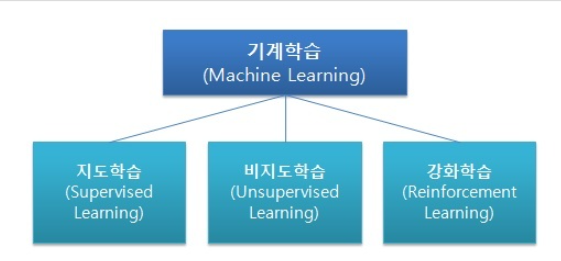
머신러닝의 종류
크게 3가지로 나눌 수 있다.
- 지도 학습
예제와 정답이 주어지고, 이를 통해 학습하여 입력과 출력의 관계를 학습하여 새로운 입력에 대한 출력값을 예측함.
- 비지도 학습
정답이 주어지지 않고, 입력 데이터로 패턴을 발견해 학습함.
- 강화 학습
보상 및 처벌의 형태로 학습 데이터가 주어짐.
이를 통해 시간이 지남에 따라 최적의 형태를 학습하면서 보상을 최대화함.
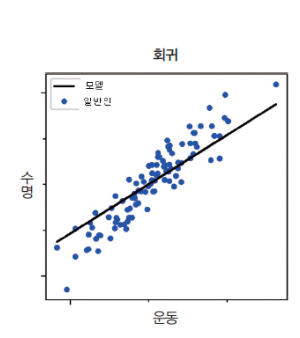
지도학습 [회귀 vs 분류]
회귀
주어진 입력-출력 쌍을 학습한 후에 새로운 입력값이 들어왔을 때,
합리적인 출력 값을 예측.
입력(x)과 출력(y)이 주어질 때, 입력에서 출력으로의 매핑 함수를 학습하는 것이라 할 수 있음.
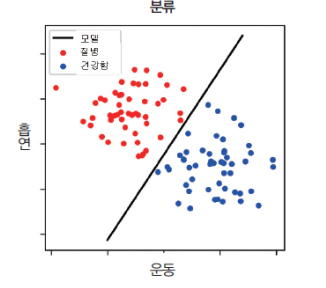
분류
말 그대로 입력을 특정 기준에 의해 2개 이상의 클래스(부류)로 나누는 것이다.
비지도 학습
“교사” 없이 컴퓨터가 스스로 입력들을 분류하는 것을 의미한다.
즉, 식 y = f(x)에서 레이블 y가 주어지지 않는 것이다.
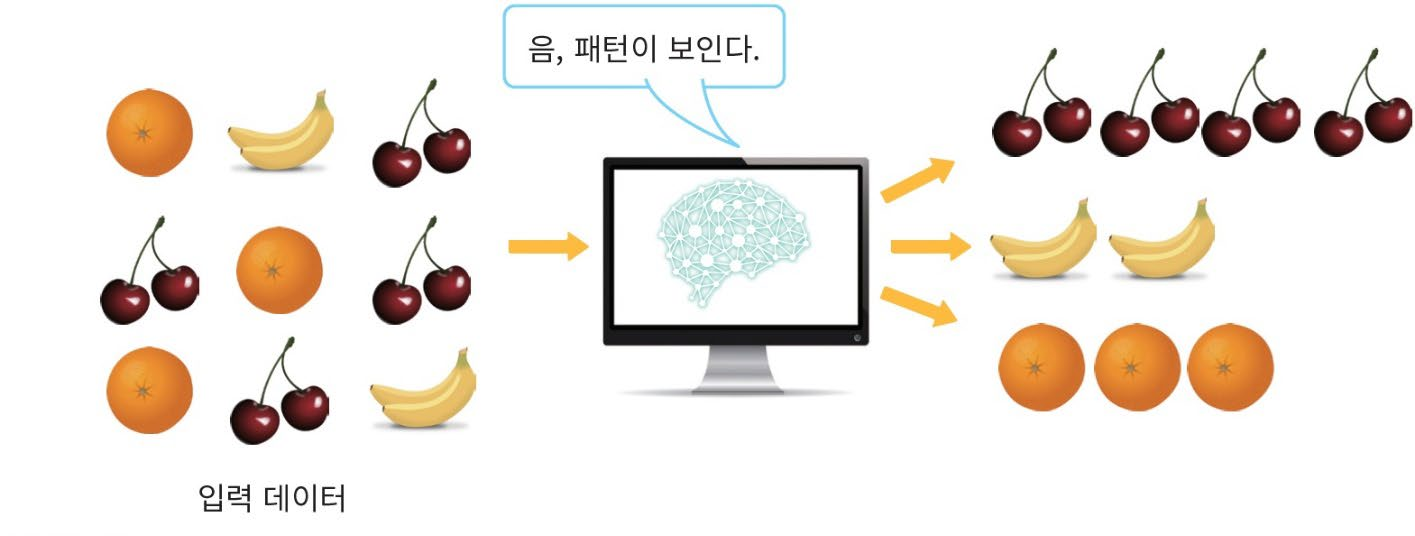
위는 데이터들의 상관도를 분석하여 유사한 데이터들을 모은 것이다.
특징이란?
데이터를 구분하게 해주는 특정 요소
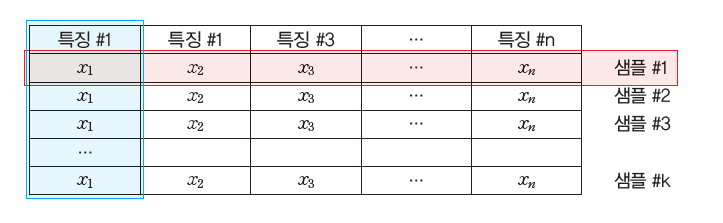
학습 데이터와 테스트 데이터
머신러닝에 사용할 데이터에는 반드시 학습 데이터와 테스트 데이터가 필요하다.
일반적인 학습 데이터와 테스트 데이터의 비율은 80:20 또는 70:30이다.
머신러닝 알고리즘의 성능평가
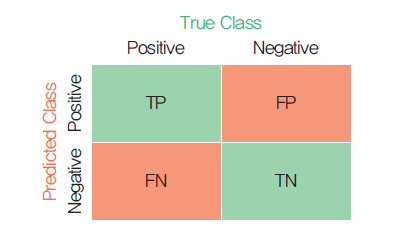
혼동 행렬(Confusion Matrix)
TP(True Positive)
FN(False Negative)
FP(False Positive)
TN(True Negative)
앞 부분은 판별의 올바름의 유무이고,
뒷 부분은 모델이 판별한 결과이다.
ex) FP > 긍정이라고 "잘못" 예측함[실제로는 부정이 정답임]
import matplotlib.pyplot as plt
시각화를 위한 라이브러리
from sklearn import datasets, metrics
from sklearn.model_selection import train_test_split
digits = datasets.load_digits()
n_samples = len(digits.images)
data = digits.images.reshape((n_samples, -1))
숫자 이미지 데이터를 포함한 데이터셋을 로드
데이터셋 내 이미지 개수를 가져옴
이미지 데이터를 2D 배열에서 1D 배열로 변환(-1은 자동으로 채워짐)
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=6)
X_train, X_test, y_train, y_test = train_test_split(data, digits.target, test_size=0.2)
데이터를 훈련 세트와 테스트 세트로 분할함.
테스트 세트는 전체 데이터의 20%로 설정.
knn.fit(X_train, y_train)
y_pred = knn.predict(X_test)
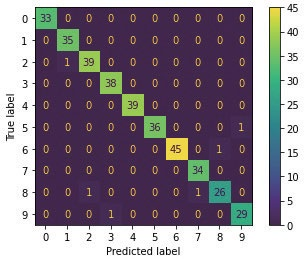
disp = metrics.plot_confusion_matrix(knn, X_test, y_test)
plt.show()
혼동 행렬(Confusion Matrix)을 시각화
출력 결과
분류성능평가지표

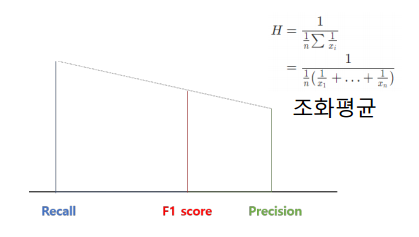
F1-Score
Precision과 Recall의 조화평균, 주로 분류 클래스 간 데이터 불균형이 심각할 때 사용
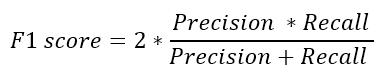
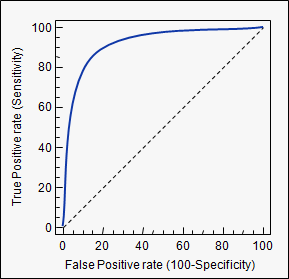
ROC(Receiver Operating Characteristic) Curve
• 여러 임계 값들을 기준으로 Recall-Fallout의 변화를 시각화
• Curve가 왼쪽 위 모서리에 가까울수록 모델의 성능이 좋다고 평가
• 즉, Recall이 크고 Fall-out이 작은 모형이 좋은 모형
• y=x 보다 상단에 위치해야 어느정도 성능이 있다고 말할 수 있음
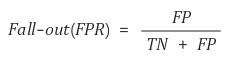
FPR = 1 – TNR(특이도)
강화학습
https://velog.io/write?id=df0f9c3f-389e-421f-8fbe-b00eae149ae1
