Static analysis of android apps: A systematic literature review (2017) 논문에서 3. Methodology for the SLR 부분만을 읽으며 Systematic Literature Review의 연구법에 대해 배워보고자 합니다.
이 논문을 선정한 이유는,
- 2017년 논문 발표된 이후에 무려 249회나 인용되며, 인정받았기 때문에
- Research Question -> Search Strategy -> Exclustion Criteria -> Snowballing 등으로 이어지는 과정이 아주 잘, 깔끔하게 설명되어 있으며 "정석"에 가깝기 때문에
그러면, 시작!
3. Methodology for the SLR
Kitchenham이 제시한 방법을 기본적으로 따른다고 함. (참고, 저 사람은 2004년에 SLR 연구법 논문을 썼는데 이것은 그냥 정석 그 자체임)
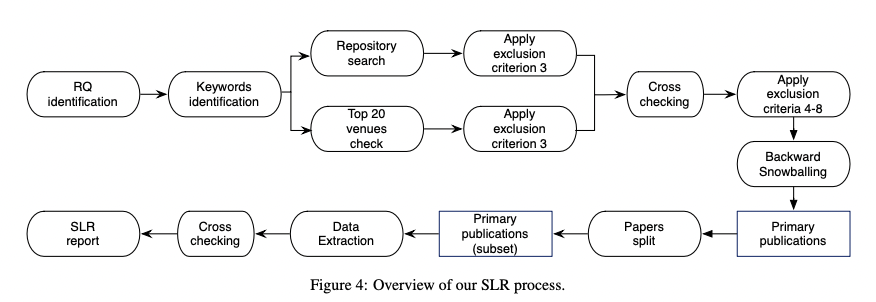
- 처음에는 SLR을 시작하게된 research question을 정의하고, 논문에서 수집해야 할 관련 정보를 식별하였다.
- 관련있는 논문들을 수집하기 위한 서로 다른 검색어(search keyword)들을 생성하였다.
- 검색 과정은 2개의 시나리오를 따라 수행되었다. 1) 잘 알려진 publication repositories 2) top venues로부터의 리스트
- 관련된 논문에만 연구를 한정하기 위해서, exclusion criteria를 적용하여, 일부를 배제하였다.
- 2개의 시나리오로부터의 결과를 통합하여 논문의 전체 리스트를 생산하였다. 우리는 논문들의 abstracts의 내용을 기반으로 또다른 exclusion criteria를 적용하여 이 리스트를 강화하였다.
- 마지막으로 선정된 논문에 대해서 가벼운 backward-snowballing을 수행하였고, 최종 논문 리스트는
primary publications/studies라고 불린다.
논문의 수가 많다는 점을 고려하여, 각각의 논문이 철저하게 연구되었는지를 검증하고, 추출된 정보가 믿을만한지 보장하는 전략을 고안하였다. 그 결과는,
- 각 논문의 원저자들에게 일일이 연락하여, 검토를 부탁하고, 스프레드시트를 채울 것을 요구하였으며, 결과가 서로 다른 경우에는 크로스-체크까지도 하였다. (우와 이게 돼..? 대박)
3.1. Research Questions
- RQ1. 분석의 목적이 무엇인가?
- RQ2. 어떻게 분석이 설계되고 구현되었는가?
연구 방법에 대해 깊게 연구하는 것이 필요했다. 그 결과 다음과 같은 sub-question들이 나오게 되었다.- 어떤 code representations가 분석 과정에서 사용되었는지?
- 안드로이드 앱 정적 분석을 위해 어떤 fundamental techniques가 사용되는지?
- 어떤 sensitivity-related feature들이 적용되는지?
- 어떤 Android-specific characteristics가 고려되는지?
- RQ3. 연구 결과가 공개적으로 이용가능한지?
- RQ4. 어떤 challenge가 아직 처리되어야 할 상태로 남아 있는지?
- 나열된 분석들이 어느 정도로 이 챌린지들을 커버하는지?(reflective calls, native code, multi-threading .. )
- 분석의 트렌드는 무엇인지?
3.2. Search Strategy
research question 덕분에 우리의 검색어를 키워드로 정리할 수 있었다. 그것은 1) 분석 작업과 관련, 2) 정적 분석의 핵심 요소와 관련, 3) 대상 프로그램과 관련 이다.
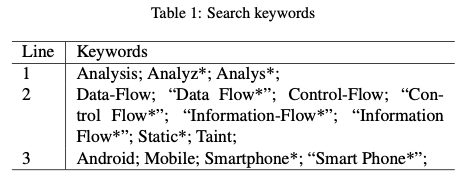
우리의 검색어 s는 3개 줄의 '결합'으로 이루어졌다. 한편 각각의 줄은 or 조건으로 합쳐졌다. 수식을 통해 보자면,
s = l1 AND l2 AND l3, l1 = Analysis OR Analyz OR Analys
우리의 데이터 검색은 repository들을 기반으로 하고, software enginerring and security의 top venue들을 체크함으로써 보충된다. repository 검색은 관련된 논문을 찾기 위함이고, top venue 체크는 추가적인 검증 과정으로, repository 검색이 주요한 논문을 빼먹지 않았다는 것을 확실히하기 위해 필요했다.
Repository Search
논문들의 데이터셋을 찾기 위해서 5개의 잘 알려진 repository를 이용했다. ACM Digital Library, IEEE Xplore Digital Library, SpringerLink, Web of Knowledge, ScienceDirect. 특정 경우에는 레포지토리의 검색 엔진이 검색되는 양에 있어서의 한계가 있는 경우가 있으므로, 우리는 검색어를 쪼개어 모든 관련된 정보가 나올 때까지 반복했다.
Top Venue Check
몇몇 컨퍼런스와 저널, 예를 들면 NDSS와 같은, 것들은 open proceeding이라는 정책을 가지고 있어서, 위에서 언급한 repository에는 존재하지 않는다. 따라서 우리는 well-known venue들에서 나온 모든 논문들을 고려하였다. 이 연구에서 우리는 top 20개의 venue를 포함했다. 10개는 소프트웨어 엔지니어링, 프로그래밍 언어 영역이고, 또다른 10개는 보안과 개인정보 분야이다. 몇몇 기초 암호학 관련, 병렬 프로그래밍 관련, 잡지, 비공식 출판물은 제외하였다. H5-index는 Google Scholar 기준으로 판단하였는데, 이 수치는 최근 5년간의 출판물들이 고려된 것이다. 클 수록 좋다.

Top venue 검사는 DBLP 기반으로 수행되었다. 이 검색을 위해서는 line 3에 있는 키워드만 이용하였는데, DBLP가 논문의 이름만을 제공하기 때문에 같은 키워드를 사용할 필요가 ㅇ벗었기 대문이다. 이상적으로 스마트폰과 관련된 모든 논문이 대상에 포함되었다. 결과적으로 coarse-granularity 전략은(정확하게 안하고 대충 뭉뚱그린 전략)은 관련 없는 논문들을 포함하게 되었다. 다행히도, venue의 수가 작기 때문에 직접 이러한 관련 없는 논문들을 배제할 수 있었고, 이 부분은 다음 섹션에서 더 설명하겠다.
3.3. Exclusion Criteria
위에서 언급한 검색어는 거의 모든 논문 리스트들의 집합을 의도적으로 허용한다. 그러나 이러한 범위의 넓음은 실제로는 관련 없거나 기초적인 논문일 것이다. 우리의 연구를 위해 다음의 제외 규칙을 정하였다.
- 비-영어 논문은 배제하였다.
- single column 기준으로 7페이지 미만의 논문이나, double column 기준으로 5페이지 미만의 논문은 배제하였다. 실제로 이런 논문들은 선제적 연구의 성격이 있어, 나중에 온전한 포맷으로 출판되는 경우가 많고, 이 경우 우리의 파이널 셋에 포함된다.
- 중복되는 논문들은 배제하였다. 컨퍼런스 논문이 이후에 저널 영역의 논문으로 발전한 경우이다. 우리는 이러한 논문들을 저자의 리스트, 논문의 제목, abstract를 기준으로 발견하였다. 이후에 직접 같은 내용을 공유하는지 여부를 검사하였다.
- non Android-related 논문들을 배제하였다. 이 배제 기준을 통해 절반 이상의 논문을 삭제할 수 있었다.
- 남은 논문들을 빠르게 스치면서, Android를 타겟으로 하나 Static Analysis를 사용하지 않는 논문들을 배제하였다. 예를 들면, dynamic analysis 관련 논문은 삭제되었다.
Android가 최근 몇 년간 뜨거운 주제였기 때문에, 이러한 조건을 거치고 나서도 해당하는 논문이 아주 많았다. 수집된 논문들 중 몇몇은 1) Android static analysis 영역에 기여한 바가 없거나, 2) 단순히 API 이름을 가져와서 매칭한 경우이다. 예를 들면, 몇몇 접근들은 단순히 manifest 파일을 읽어 permission 리스트를 가져오거나, 함수 호출에서의 특정한 API 이름을 가져오려는 시도이다. 따라서 우리는 4개의 exclusion criteria를 추가하였다.
- Android 앱이 아니라 OS를 정적 분석한 논문들을 배제하였다. 예를 들면 PSCout, EdgeMiner과 같은 논문은 Android framework를 분석하는 데에 기여했기 때문에 배제하였다.
- 앱의 프로그램 코드를 실제로 parse하지 않은 논문은 배제하였다. 예를 들면 오로지 meta-data(description, configuration ...) 만을 대상으로 static analysis를 진행한 경우.
- SCanDroid와 같은 technical report도 배제하였다. 이런 non-peer-reviewed 논문은 종종 컨퍼런스나 저널에 재출판되는 경우가 많고, 그렇게 되면 우리의 리스트에 포함될 확률이 높다.
- 명령어의 순서를 이용하거나, API 이름을 가져오는 정도의 단순한 이용은 배제하였다. 예를 들면 Juxtapp이라는 clone detection approach는, 단순히 opcode sequence를 가져오는 데에 그치기 때문에 배제하였다.
3.4. Backward Snowballing
Kitchenham 님의 절대적인 가이드라인에 따라 backward snowballing도 수행하였다. 목적은 키워드 검색에서 미처 발견되지 못한 추가적으로 관련된 논문을 식별하기 위함이다. 이것을 직접 수행하기에는 지루하고, 시간이 많이 들기 때문에 우리는 python script를 짜서 자동으로 레퍼런스들을 추출할 수 있도록 하였다. 구체적으로 우리는 pdfx를 이용하여 pdf를 텍스트 포맷으로 변경하였다. 그러면 우리는 모든 레퍼런스가 텍스트 파일로 나오는데, 여기에 script를 이용하여 1) SLR timeline 밖의 논문을 제거하고, 2) 제목에 우리가 설정한 키워드가 들어가지 않는 논문을 제거하였다. 그 이후에는 우리는 나머지 레퍼런스 논문들을 직접 읽으면서 검사하였다. 여기에서 발견된 논문들이 우리의 논문 셋에 포함되지 않는 경우에는 추가해주었다.
3.5. Primary publications selection
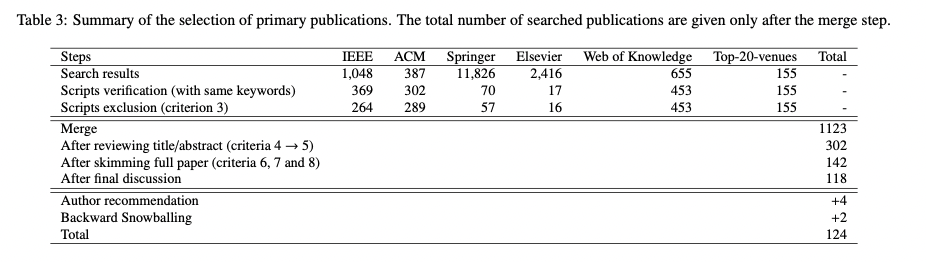
Table 3에서 보여주고 있는 우리의 최종 선택 결과에 대한 자세한 설명을 하려고 한다. 첫 두 줄은(search result, script verification)은 키워드를 기반으로 한 검색의 수치를 보여준다. 첫 줄에서, repository search로부터 나온 결과에 집중했다. (여기에서는 최대한 많은 논문을 수집하는 데에 집중했다.) repository search를 통해, 우리는 paper title이나, paper abstract와 같은 정보를 수집했다. 둘째 줄은 수집된 데이터에 대한 추가 검증 단계에 대한 결과이다. 구체적으로 우리는 수집된 데이터에 대해서 자동화된 키워드 검색을 수행했다. (이전 스텝에서와 정확히 같은 키워드를 이용) 둘째 줄을 도입한 이유는 5개의 repository에서 제공하는 "advanced" 검색 기능의 결함 때문이다. 검색 결과는 때때로 정확하지 않아, 관련 없는 논문들이 많이 포함되어 있었다. 둘째 줄을 거친 후에 해당하는 논문의 수가 많이 감소하였다.
세번째 줄은 exclustion criteria를 적용한 결과를 나타낸다. 특히 IEEE repository에서 큰 감소가 있었는데, IEEE에서는 짧은 논문들이 많아 그들의 접근법/도구에 대한 불충분한 설명을 제공하기 때문이었다. 이러한 것들은 제거하는 것이 맞다!
네번째 줄에서는 이것을 하나의 셋으로 합치는 과정에서 중복된 연구를 제거하였다. 이 과정에서 이러한 경우들이 존재했다. 1) ACM repository에서 IEEE나 Springer에 원래 출판되었던 논문을 포함하고 있는 경우, 2) Web of Knowledge repository에서 Elsevier에 출판된 논문을 포함하고 있는 경우, 3) 5개의 repository가 top-20-venue에 등장하는 논문을 포함하고 있는 경우.
merge한 이후에는 공동 저자들에게 논문을 분배하였다. 우리는 직접 title/abstract를 읽고, 전체 컨텐츠들을 검사하면서 4-8 exclusion criteria를 적용하였다. 저자들 사이의 최종 검토를 통해 118개의 논문을 기초 논문으로 선정하였다.
자기-검사 과정을 위해, 우리는 저자들의 이메일 주소를 수집하여, SLR를 이 저자들에게 발송하고, 그들의 논문이 올바르게 분류되었는지 검사해주기를 요청하였다. 우리는 25개의 피드백 메시지를 받았고, 저자들은 19개의 논문이 SLR에 더 추가되어야 한다고 추천해주었는데, 그 중에서 15개는 이미 존재하였고 4개는 우리의 exclusion criteria의 경계선쯤에 존재하였다. (dynamic anlaysis인데 static analysis를 이용한) 우리는 이것들을 셋에 포함하였다.
backward-snowballing과 관련해서, 우리는 timeline 내부에 존재하는 1815개의 관련된 논문을 발견하였다. 그 중에서 오로지 53개만이 키워드 밖의 title을 가지고 있어 배제하였다. 나머지 논문들을 검토하여서 오로지 2개만이 우리의 조건을 만족하여 추가하였다.
최종적으로 우리의 SLR은 124개의 논문을 검토하였는데, 해당 리스트는 뒤에 첨부하였다. 이러한 논문들을 타입과 도메인으로 분류한 그림도 첨부하였다. 70%에 달하는 논문이 컨퍼런스였다. ... (그 밖에 ~~ 했더라)

끝!
