Introduction
지난 주까지해서 YOLO의 구조 및 원리에 대해서 살펴보았다. 현재 YOLO는 수많은 다른 개발자들에 의해 가공되고 발전되서 YOLOv7까지 찾을 수 있었다.
지금 하고 있는 프로젝트에 사용하는 YOLO version은 5를 사용하게 되었는데, 딱히 명확한 이유는 없고 이걸로 한번 해서 개량해보자라는 방향이라 선정하게 되었다.
본 포스트에 기록할 내용은
- YOLO 개발환경 Setting
- Project 경과
- 앞으로의 계획 및 참고사항
이 주를 이룬다.
YOLO Setting
PC 사양
먼저 지금 사용하고 있는 PC 사양을 간략히 정리하면,
CPU : i5-9500
RAM : 32GB
OS : Windows 10
GPU : NVIDIA Geforce 1660
으로 지금 많이 나와있는 GPU에 비하면 조금 부족한 스펙이지만, 서버를 받게된다면 사용할 수 있기 때문에 아직까지는 큰 문제 없이 사용 중 이다. (+ 교수님 사무실에 남는 GPU도 주워오기로했다!)
Setting
이 과정이 제일 귀찮았는데, 버전이 다른것이 많아 + 사람의 PC 사양에 따라 달리 설치해주어야했기 때문에 주의해야한다. 기본적인 과정은
- VS(Visual Studio) 설치
- CUDA 설치
- cuDNN 설치
- OPENCV 설치
- Pytorch 설치
인데, 나는 VS v2015, CUDA v10.1, cuDNN v8.0.3, OPENCV v3.4.8, Pytorch는 CUDA10.1에 맞는걸로 구글링해서 설치했다. 상세한 설치방법은 다른 블로그들을 검색하면 충분히 많이 자료를 얻을 수 있어, 본인이 원하는 환경과 유사하게 진행하신 혹은 본인의 PC 사양과 비슷한 환경인 가이드를 따라가는게 제일인 것 같다.
🤦♂️유의사항🤦♂️
Visual Studio를 먼저 설치하고 CUDA를 꼭 설치해야한다. 그렇지 않으면 다시 까는게 나은 귀찮은 상황들과 마주하게 된다. 또한, Visual Studio에 C++ 및 Python 개발환경 Setting을 하면 편리하게 볼 수 있다. 마지막으로, 각 프로그램마다 요구하는 최소버전이 있기 때문에 이에 유의하여 설치해야한다. YOLOv5도 요구하는 버전, OPENCV, Python에 제약이 있기 때문에 너무 구버전은 호환성에 문제가 생길 수 있다. 또한 환경변수 PATH 설정도 잊어서는 안된다!
GET YOLOv5!
이렇게 모든 준비를 마쳤으면 이제 YOLOv5를 Github에서 다운로드해준다. 사실 다운로드만 하고 Sample Image를 실행하는 것은 이미 학습이 되어있기 때문에 바로 진행할 수 있다. cmd 창이나 본인이 Conda를 사용한다면 Conda Prompt나 등 console 창에 다음과 같이 명령하면 된다.
python detect.py --source "contents/imamge/" #--source 뒤에는 본인이 원하는 img의 경로 및 파일명을 기입하면 된다!Sample로 몇 가지를 해본 결과들이다.


NBA Final 사진에서 보면 Thompson 얼굴이 아니라 옆에 Anchor Box가 있는 약간의 miss가 있긴하지만, 비교적 높은 성능 그리고 빠른 시간을 보여준다.
Project
Intro...
지금 근로 중인 스타트업에서 하는 프로젝트 중 하나로 수표에 있는 인감도장의 대조에 관한 시스템을 구축, 개량하는 부분을 우선 진행 중이다.

👌 이미지출처
Start..!
위와 같이 모든 수표에는 인감도장이 찍히게 되는데, 그 인감도장이 수표의 사용에 문제가 없는 본인의 도장이 맞는지를 판단하는 시스템을 개량하신다고 한다. 그럼 우선 이 시스템의 개략적인 과정을 보면
1. 수표 사진에서 인감도장 검출
2. 은행 등 서버 데이터에서 본인 인감과 대조
3. 확인 후 승인 및 미등록 시 데이터 저장
의 단계를 거치게 된다. 따라서 우선적으로 해야하는것은 저 사진에 있는 인감도장을 얼마나 잘 검출해서 이를 데이터 서버에 넘겨줄 수 있는가이다.
따라서 제공받은 데이터를 최대한 Augmentation 시켜서 학습을 진행해보았는데, 이때 사용한 사이트가 Roboflow이다. 여기서 손쉽게 data를 build할 수 있었다. 실제 편집 사진은 실 수표라 생략하겠습니다..😂 저렇게 data를 만들고 이를 다운로드 해주면 train, test, valid 폴더를 얻게 되고 이를 yolov5 폴더에 data에 넣어주면 된다. 이후
python train.py --img 416 --batch 16 --epochs 128 --data contents/data.yaml --weights yolov5m.pt이렇게 학습을 시켜주면 된다. 여기서, img는 본인이 만든 img size로 epochs 원하는 만큼, 그리고 data는 data.yaml 파일이 위치한 경로를 contents 항목에 넣어주면 된다. 그럼 이제 열심히 학습을 한다.
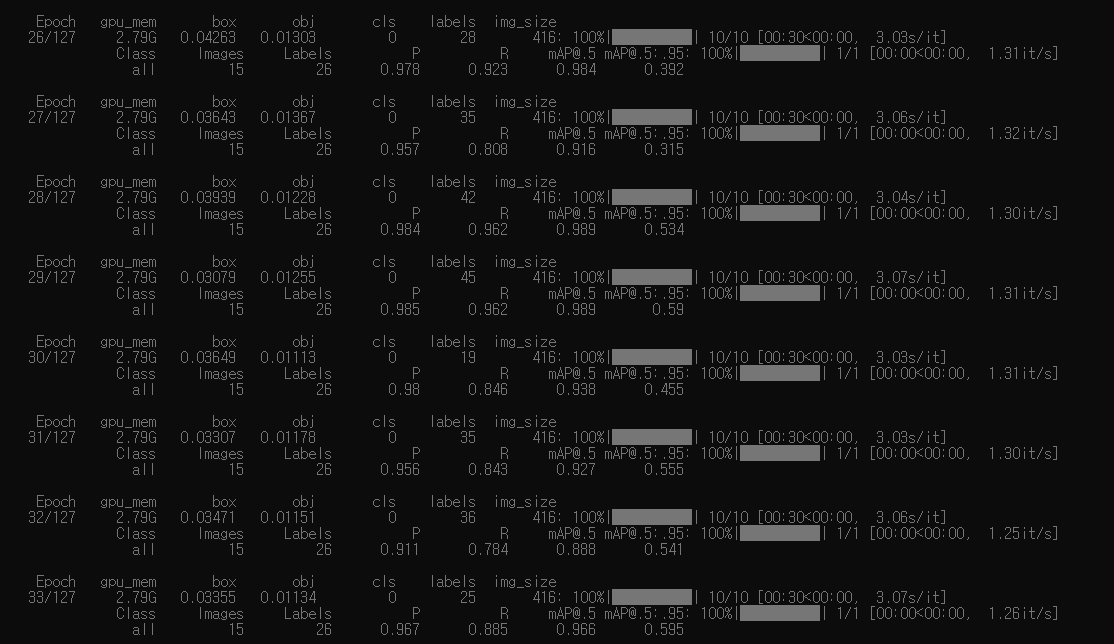
학습이 끝나면 이제 결과 파일이 저장되게 되고, weight 파일을 얻을 수 있다.

그럼 이제 이 weight 파일을 가지고 test를 진행하면 된다.
python detect.py --source contents/images/ --weight contents/modelfiles --conf /confidence score/이렇게 해주면 되는데, 여기서 confidence score는 본인이 설정하면 된다.
Result..!!!

그렇게 test를 진행하니 다음과 같이 인감도장이 검출되는것을 확인할 수 있다..!
Next Step
Data Pruning
이제 다음 단계로 해나갈 것은, 단순히 인감도장만 선택하면 되는데 굳이 많은 학습이 필요할까라는 물음에서 나와서 교수님께서 이것저것 생각해볼거리를 많이 어제 세미나에서 말씀해주셨다. 먼저, 인감도장의 형태와 색에 집중하고 다른 특징들에 대한 conv layer는 없어도 되지 않을까? 그럼 architecture가 간단해지고 더 빠른 속도를 나타낼 수 있다. 이 기본 과정을 기반으로 YOLOv5가 진행하는 filter의 과정 및 각 코드가 어떻게 작용하는지를 자세히 공부할 예정이다...! 어느정도 진행이 되면 이제 다시 Paper Review도 포스팅 해보고자 한다!
