지난 Attention is All You Need 포스트에 이은 두 번째 Paper Review는 NLP에서 사용된 Transformer를 CV 영역에도 적용한 Vision Transformer(ViT)입니다. 논문 원본과 공식 코드는 아래 링크를 참고해주세요.
✅An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale(ICLR 2021)
✅공식 Github 주소
Abstract
 Fig 1. Abstract
Fig 1. Abstract
Abstract에서 Transformer architecture의 소개 이후, NLP 분야에서는 많은 연구가 이루어 졌으나, computer vision에 적용하는 것은 아직 제한적이라고 말하며 시작합니다. 왜냐하면 Computer Vision 분야에서는 Attention이 CNN과 conjunction 되어 있거나, 특정 부분을 대체하는 정도로 사용되었기 때문입니다. 본 연구를 통해서 Vision 분야에서도 Pure transformer가 image classification 등의 영역에서 state-of-the-art CNN 보다 더 좋은 성능을 보였음을 증명합니다.
Introduction
Introduction에서 말하는 것을 간략히 정리하면 아래와 같습니다. 원문은 Fig 2~3을 참고해주세요.
 Fig 2. Introduction 1
Fig 2. Introduction 1
 Fig 3. Introduction 2
Fig 3. Introduction 2
- Transformer의 효율성과 확장성으로 인해, unprecedented size이며 100B가 넘는 parameter를 지닌 model의 학습도 가능하게 됨
- Computer Vision에서는 CNN이 아직 dominant로 남아있음
- NLP에서 Transformer의 성공으로 이를 이용한 연구가 발표되었으나, 이론적으로는 효율성이 나타나지만 실제 사용하는 하드웨어와의 호환이 잘 이뤄지지 않았음
- 본 연구에서는 image를 Transformer로 직접적으로 삽입
- 이를 수행하기 위해 image를 patch로 분할하고, linear embedding의 sequence로 만들어서 Transformer의 input으로 사용
- 이러한 Image patch들은 NLP에서의 token과 같은 역할을 수행
-
Mid-Size의 dataset(ImageNet)에서는 ResNets에 비해 strong regulation이 없는 경우 더 좋은 성능을 보이지 않았음
-
그 원인으로 논문에서는 아래와 같이 추론함
Transformers lack some of the inductive biases inherent to CNNS, such as translation equivariance and locality, therefore do not generalize well when trained on insufficient amounts of data.
-
하지만 더 큰 모델(14M-300M image)에서는 위의 inductive biases를 극복 가능하다고 함
-
따라서 ViT(Vision Transformer)는 충분히 큰 dataset에서 우선 학습 시키고(pre-trained) 그 모델을 작은 dataset으로 전이학습(transfer learning) 시켰을때 좋은 성능을 보임
Related Work
Transformer의 발견 이후, 많은 연구들이 있었습니다.(하단의 Fif 4-6의 하이라이트 된 부분을 참고해주세요.)
 Fig 4. Related Work 1
Fig 4. Related Work 1
- Fig 4의 마지막 문장에서 알 수 있듯, 앞선 선행 연구들은 하드웨어 가속기(hardware accelearator)에서 연산을 효율적으로 수행하기 위해서는 복잡한 작업들이 요구된다는 단점이 있습니다
 Fig 5. Related Work 2
Fig 5. Related Work 2
- Fig 5의 하이라이트 된 부분을 참고하면, 이미지를 2-2의 패치로 나눈 후 이를 적용하는 것인데 ViT와 가장 유사하다고 합니다
- 하지만, ViT가 vanilla Transformer 구조를 사용했다는 점, 오직 저해상도 이미지에서만 사용할 수 있는 반면에 ViT는 중해상도 이미지에서도 적용이 가능하다는 점에서 더 좋은 성능을 나타낸다고 합니다
 Fig 6. Related Work 3
Fig 6. Related Work 3
- 기존의 선행연구와 ViT의 차별점은 standard ImageNet dataset보다 더 큰 dataset에서 실험을 진행하고, 이를 기반으로 기존의 ResNet을 바탕으로 하는 CNN보다 월등한 성능을 낼 수 있었다는 것입니다
Method
본 챕터에서는 ViT의 model architecture 등에 대해 자세히 살펴보겠습니다. Image를 처리하기 위한 전처리 과정을 제외한다면 Transformer의 구조와 거의 유사하며, 이는 논문에서 필자들이 장점으로 이야기한 부분이기도 합니다.
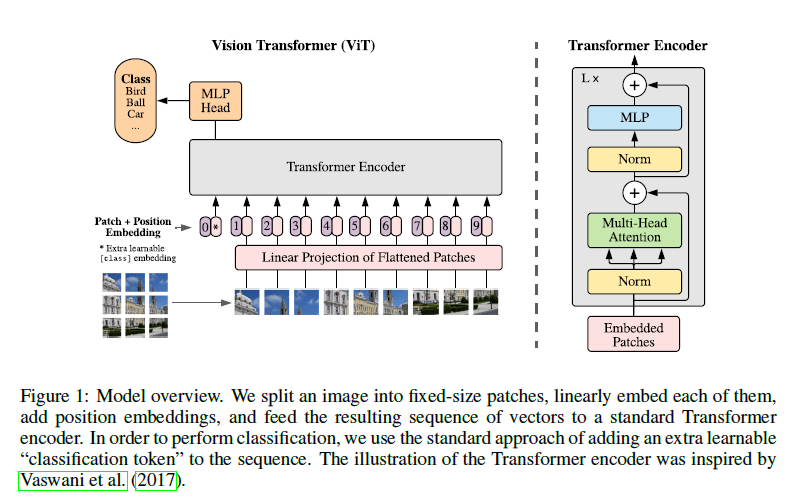 Fig 7. Model Architecture of ViT
Fig 7. Model Architecture of ViT
Vision Transformer(ViT)
아래 첨부한 이미지에서 흐름을 상세히 확인 할 수 있습니다. 수식으로, 글로 이해하는 것에서 그치지 않고 이렇게 이미지 파일로 보니 코드 짤때도 도움이 된 것 같습니다. 직접 짠 코드(Pytorch Based)도 기회가 되면 & 제가 github에 보다 익숙해지면 공유하도록 하겠습니다.
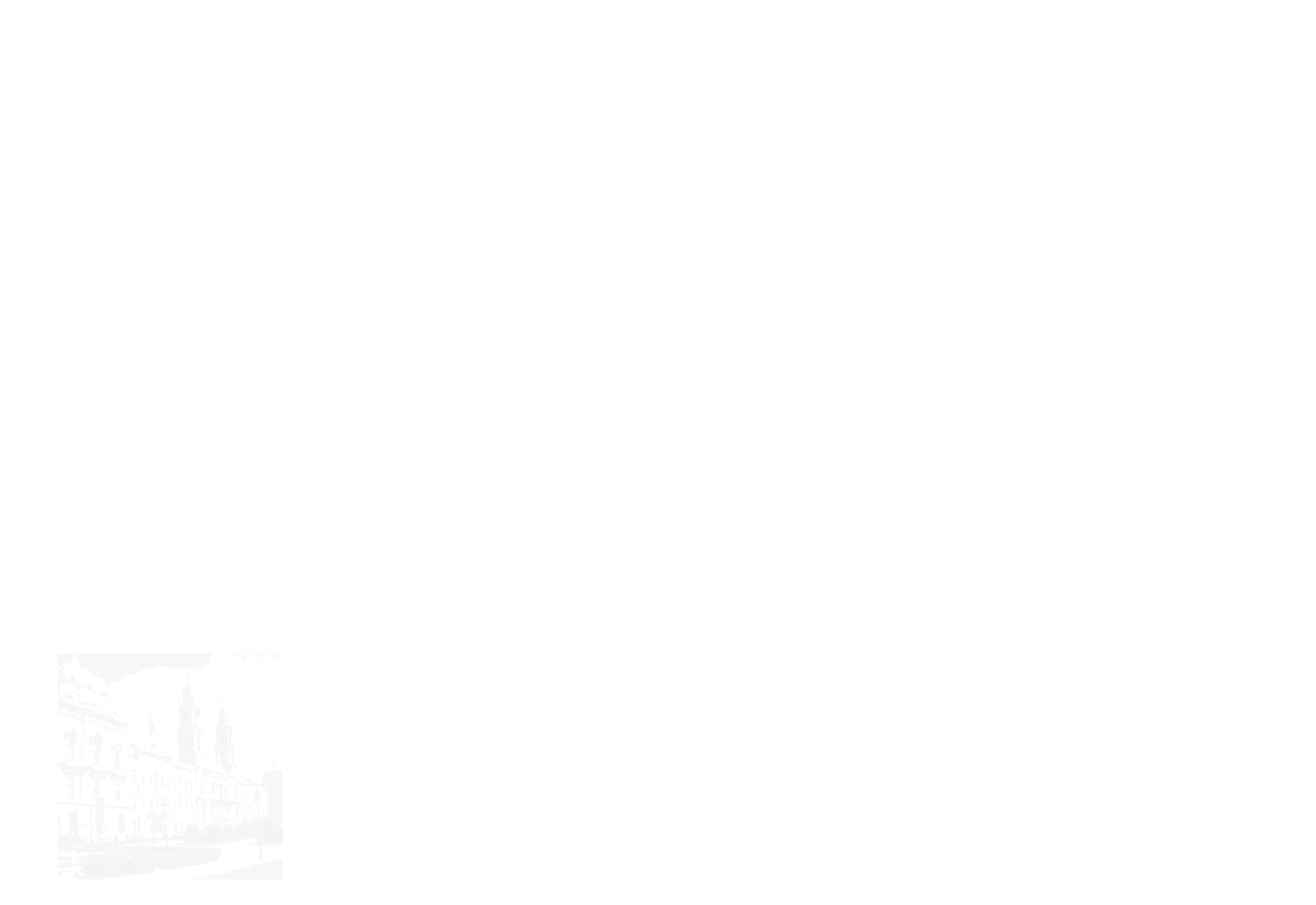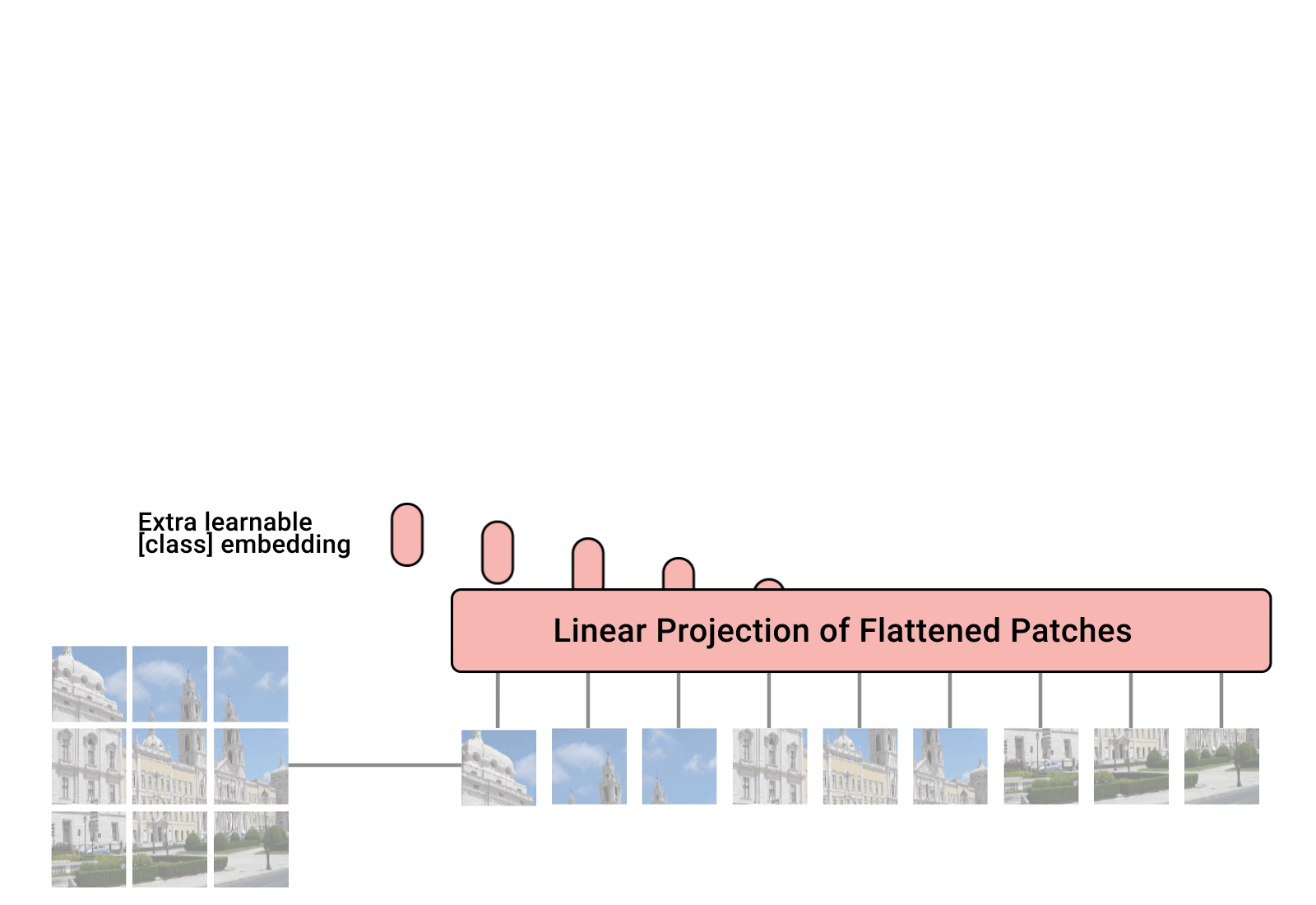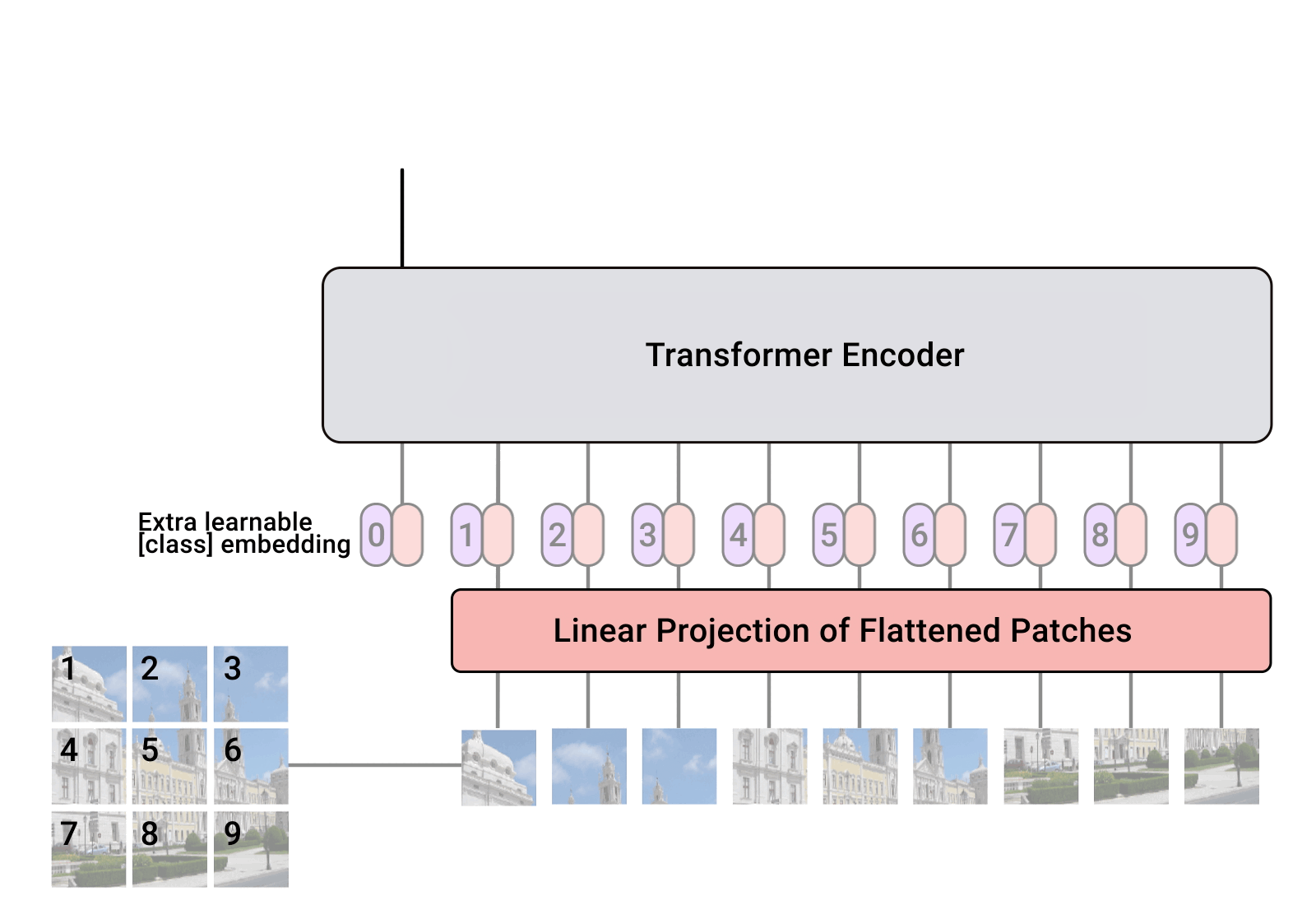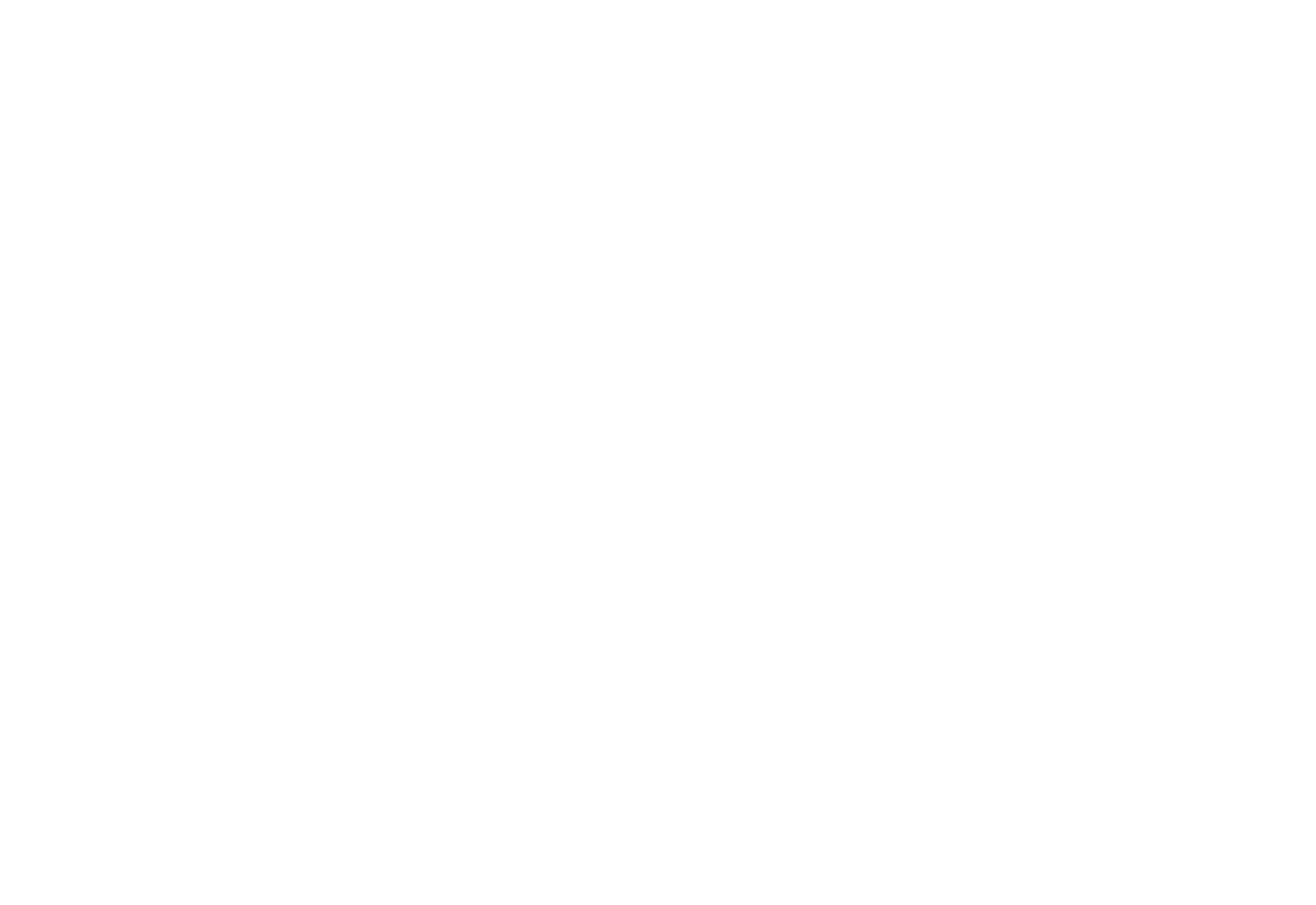 Fig 8. Model Architecture Flow of ViT
Fig 8. Model Architecture Flow of ViT
큰 틀은 기존에 리뷰한 Transformer와 유사합니다. 특히 Transformer Encoding 부분은 거의 변함이 없고, 이미지를 patch로 나누어서 linear projection하는 것이 NLP의 token과 같은 역할을 수행하는 것으로 보입니다.
 Fig 9. Vision Transformer 1
Fig 9. Vision Transformer 1
Fig 9.에는 2D 이미지를 flattern하고 patch로 만들어주기 위해 rearrange하는 과정에 대해서 설명해주었습니다. 2D 이미지를 다루기 위헤 이를 2D patches로 변환한 후 이를 다시 1D의 차원으로 flattern 하여 넣어줍니다. 따라서, Transformer에 맞는 vector 형식으로 치환하여 input value로 사용해주게 됩니다. Fig 8을 보시면 1~9번까지의 patch가 순차적으로 linear projection of flatterened patch로 들어가는 것을 볼 수 있습니다. 이 과정이 앞서 보인 Patch Embedding 과정입니다.(Fig.7 참고) 두번째 문단을 살펴보면 BERT와 유사하게 임베딩된 패치들의 맨 앞에 학습가능한 class 토큰 임베딩 벡터 하나를 추가했습니다. 임베딩벡터()는 Transformer의 여러 encoder층을 거쳐 최종 output() 으로 나왔을 때, 이미지에 대한 1차원 representation vector로써의 역할을 수행합니다. 여기서 은 마지막 dimension을 의미합니다.
 Fig 10. Vision Transformer 2
Fig 10. Vision Transformer 2
Position Embedding은 위치 정보를 유지하기 위해서 Patch Embedding에 추가되며, 본 연구에서는 advanced 2D-aware 위치 임베딩을 사용하는 것과 성능에서 큰 차이가 관측되지 않았기 때문에 학습가능한 1D position embedding을 사용합니다. Embedding vector의 Resulting sequence는 encoder의 input으로 사용됩니다. 아래의 Fig 11을 통해 ViT에서 사용되는 이론적인 수식을 알아볼 수 있습니다. 상세한 설명은 제가 참고한 리뷰를 보시면 도움이 될 것 같습니다.
 Fig 11. Vision Transformer 3 - Equation of ViT
Fig 11. Vision Transformer 3 - Equation of ViT
Inductive Device
 Fig 12. Inductive Device
Fig 12. Inductive Device
- CNN에서는 Locality, 2D neighborhood structure, translation equivariance의 세가지가 image-specific한 inductive device로 존재
- ViT에서는 MLP layer만 local, translationally equivariant로 작용하며 self-attention layers는 global함
- 2D neighborhood structure는 model의 초창기에는 cutting image to patch로, positional embedding 조절(fine-tuning)으로 작용함
Hybrid Architecture & Fine-tuning and higher-resolution
본 논문에는 짧게 소개되어 있어(Fig 13.) 참고한 리뷰글을 통해서 상세한 정보를 얻을 수 있습니다.
 Fig 13. Hybrid Architecture
Fig 13. Hybrid Architecture
Experiments
첨부한 각 이미지 별로 논문 내에서의 설명을 별첨하도록 하겠습니다.
 Fig 14. Datasets
Fig 14. Datasets
- ILSVRC-2012 ImageNet(1k classes & 1.3M images)
- Sperset ImageNet-21k(21k classes & 14M images) & JFT (18k classes and 303M high-resolution images)
Test of Downtream Tasks
- ImageNet (Val)
- ImageNet with cleaned-up ReaL Labels
- CIFAR-10/100
- Oxford-IIIT Pets
- Oxford Flowers-102
Also evaluate,
- VTAB Datasts for 19 tasks
"The tasks are divided into three groups: Natural – tasks like the above, Pets, CIFAR, etc. Specialized – medical and satellite imagery, and Structured – tasks that require geometric understanding like localization."
Baseline
" For the baseline CNNs, we use ResNet (He et al., 2016), but replace the Batch Normalization lay- ers (Ioffe & Szegedy, 2015) with Group Normalization (Wu & He, 2018), and used standardized convolutions (Qiao et al., 2019). These modifications improve transfer (Kolesnikov et al., 2020), and we denote the modified model “ResNet (BiT)”. For the hybrids, we feed the intermediate fea- ture maps into ViT with patch size of one “pixel”. To experiment with different sequence lengths, we either (i) take the output of stage 4 of a regular ResNet50 or (ii) remove stage 4, place the same number of layers in stage 3 (keeping the total number of layers), and take the output of this extended stage 3. Option (ii) results in a 4x longer sequence length, and a more expensive ViT model. "
상세한 내용은 paper의 appendixt table 6. 참고
- Optimizer : ADAM for Pre-training and SGD for fine-tuning
- batch size : 4096
- linear warmups & Learning Rate Decay : Cosine or Linear
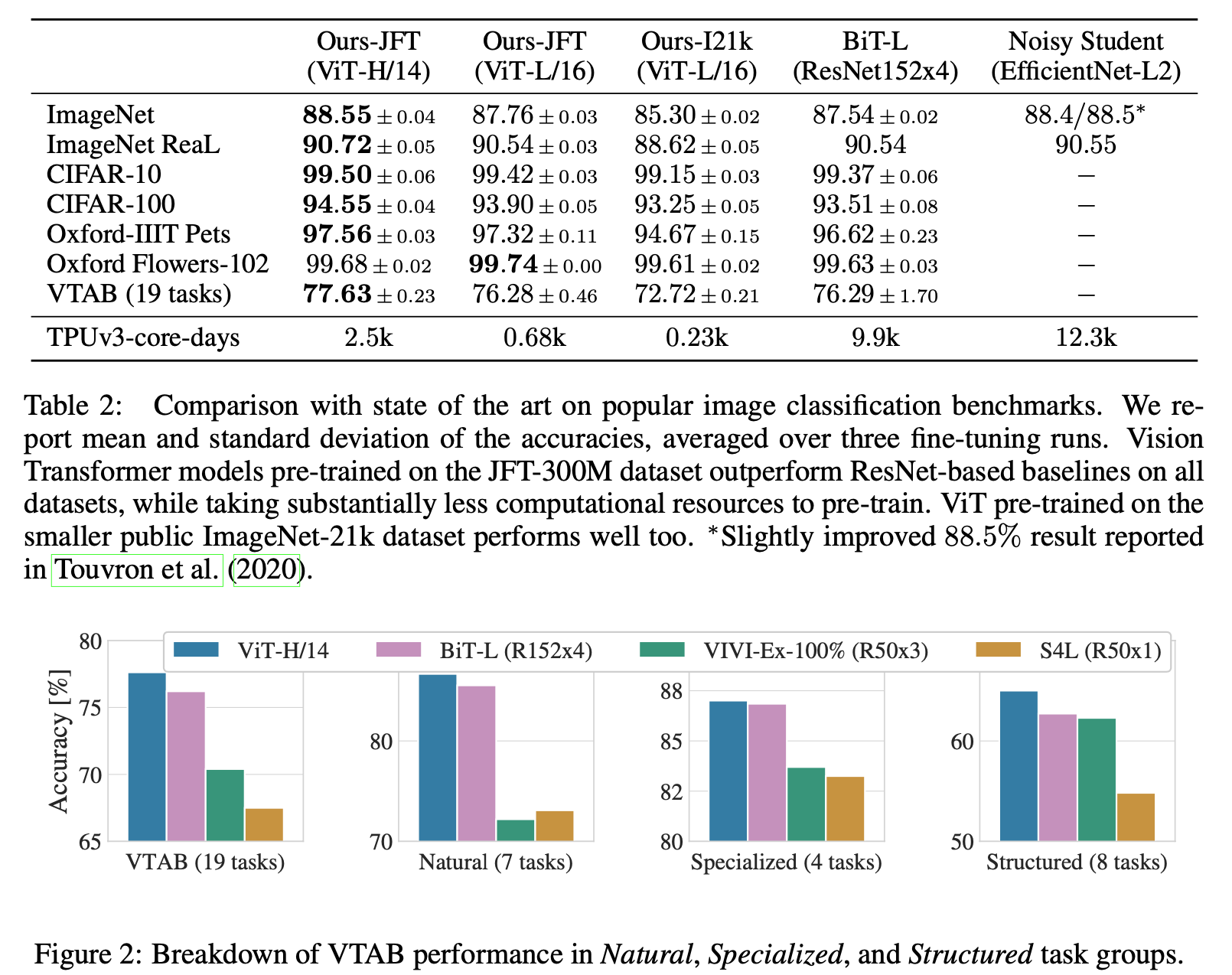 Fig 15. Details and Results
Fig 15. Details and Results
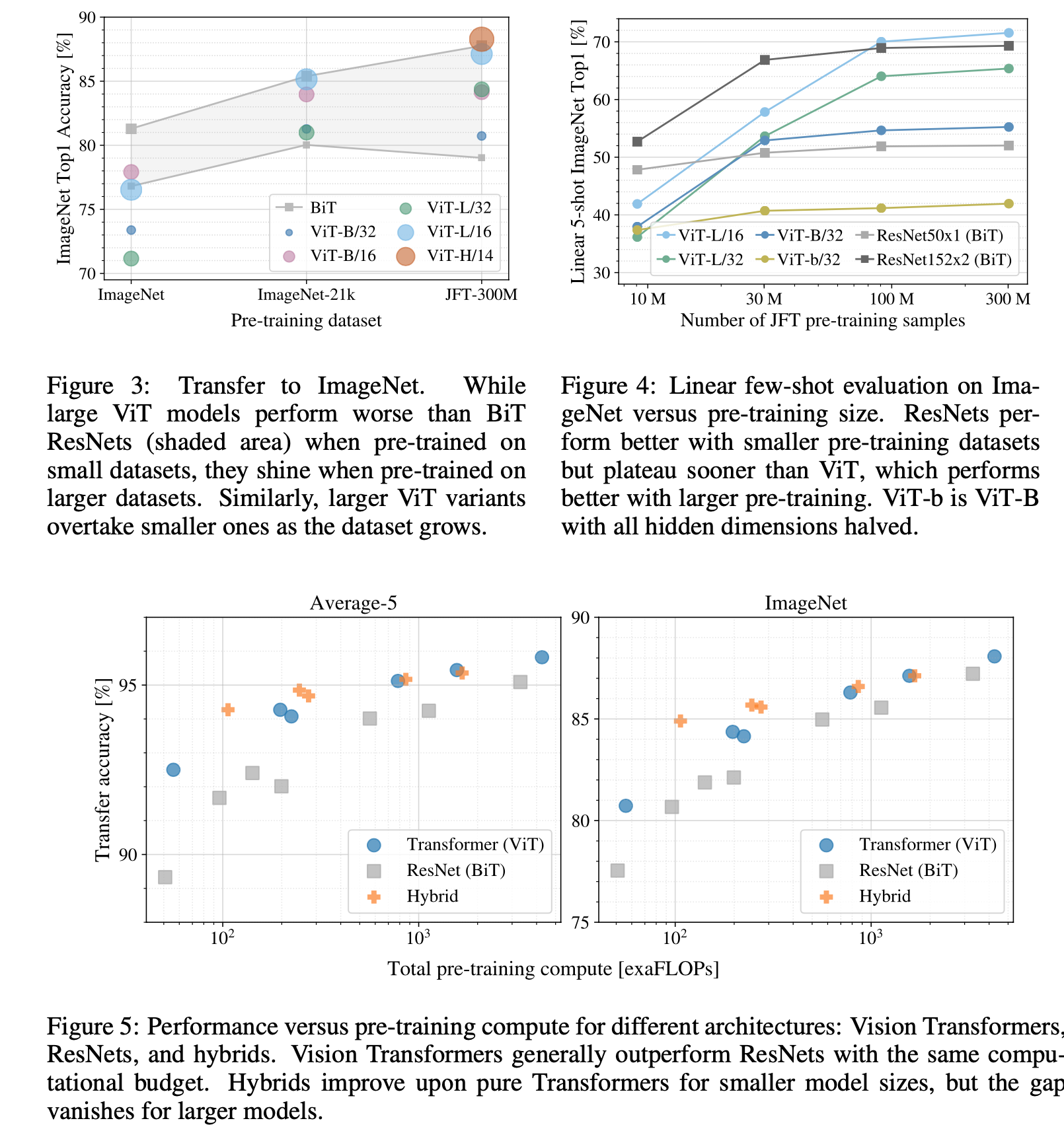 Fig 16. Results
Fig 16. Results
▶️ 이를 통해 ViT는 Model Parameter 및 DataSet의 크기가 증가할 수록 지속적으로 성능이 증가함을 도출 할 수 있음
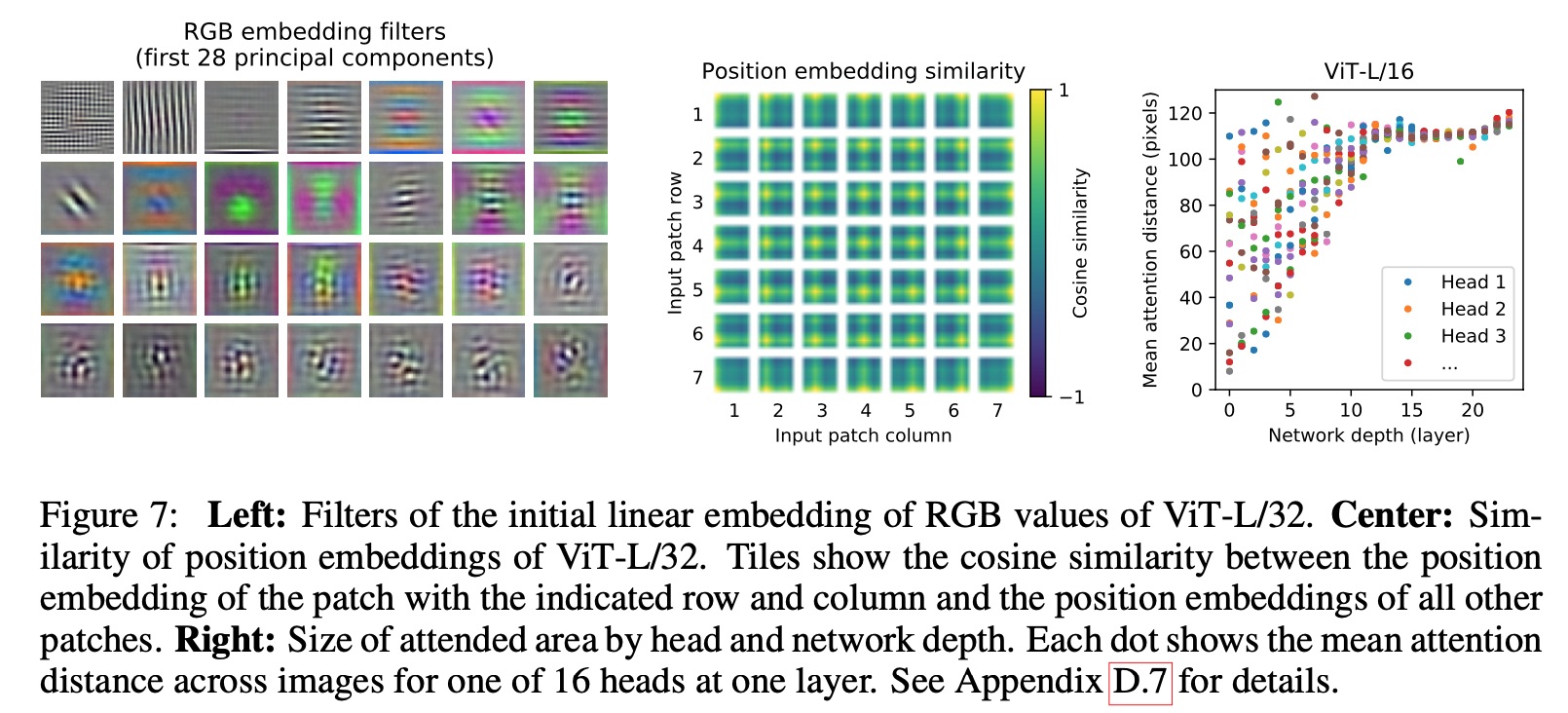 Fig 17. Inside of ViT
Fig 17. Inside of ViT
Fig 17.은 ViT의 내부를 확인하기 위해 진행한 실험으로 상세한 정리는 참고 리뷰에 상세히 나와있습니다. 저는 읽어보고 이해하는 정도에서 마쳤습니다.
Conclusion
ViT는 NLP 영역에서 사용되는 Transformer라는 개념을 computer vision에 직접적으로 접목시킨 연구분야로, 이를 통해서 최근 다양한 논문이 쏟아져 나오고 있습니다. Transformer에 대한 기본적인 이해가 있으면 보다 쉽게 읽을 수 있었던 것 같아 상세한 이론적인 내용이 조금 축약된 부분이 없지 않아 있어 보입니다. 그 전의 포스트 및 참고자료들을 이해하면 보다 쉽지 않을까 생각합니다. 제가 Transformer를 이론적으로 공부할 때 주로 봤던 영상과 사이트들을 링크 걸어둘테니 도움이 되길 바랍니다.
✅고려대학교 DSBA 연구실 Transformer 강의
✅고려대학교 DSBA 연구실 ViT 설명강의
다음 포스트는 SwinIR 혹은 RVRT로 생각 중 입니다. 두 편 모두 Review 할 예정이라 먼저 읽히는 논문 먼저 작성해보겠습니다.
감사합니다!
