
정규표현식에 대해서 모던 자바스크립트 Deep Dive를 읽고, 정리를 한번 해보았지만 막상 실제로 사용하는데에 있어서 어려움이 있어서 완전히 끝낼 목적으로 다시 한번 정규표현식에 정리하면서 작성한 글입니다.
정규표현식이란?
문자 검색과 교체에 사용되는 패턴으로 문자열과 관련하여 강력한 기능을 제공한다.
--> 조건문 없이 패턴을 정의하고 테스트할 수 있다.
new RegExp(pattern[, flags]); // 생성자 함수를 사용하여 RegExp 객체를 생성할 수 있다.
const target = 'Is this all there is?';
const regexp = new RegExp(/is/i); // ES6
regexp.test(target); // --> true정규표현식의 구성
- 플래그
- 패턴
플래그
검색 방식의 설정을 위함
- i: 대,소문자 없이 검색한다.
- g: 패턴과 일치하는 모든 것들을 찾는다. 이것이 없으면 패턴과 일치하는 첫 번째 결과만 반환된다.
- m: 문자열의 행이 바뀌더라도 패턴 검색을 계속한다.
패턴
문자열의 일정한 규칙을 표현하기 위해 사용
여러가지 패턴을 알아두는 것이 나중에 정규 표현식을 사용할때 많이 도움이 된다.
문자열 검색
const regExp = /찾고 싶은 문자열/flag
// abc를 찾는 대소문자 구별 패턴
const regExp = /abc/;
// 대소문자를 구별하지 않고 패턴과 일치하는 결과가 있을 경우 첫 번째 결과 하나만 반환
const regExp = /abc/i;
// 대소문자 구별하지 않고 패턴과 일치하는 모든 문자열 검색
const regExp = /abc/ig;임의의 문자열 검색
.은 임의의 문자 하나를 의미한다.
// 임의의 3자리 문자열을 대소문자를 구별하여 전역 검색(공백 포함)
const regExp = /.../g;반복 검색
{m, n} --> 최소 문자 m번, 최대 n 번 반복
{n} --> 앞선 패턴이 n번 반복 ({n, n} === {n})
{n,} --> 앞선 패턴이 최소 n번 이상 반복
+ --> 앞선 패턴이 최소 한번 이상 반복 ({1,} === + )
? --> 앞선 패턴이 최대 한번 이상 반복 ({,1} === ? )
// A가 최소 2번 이상, 최대 3번 반복되는 문자열 전역 검색한다.
const regExp = /A{2, 3}/g;
// A가 2번 반복되는 문자열 전역 검색한다.
const regExp = /A{2}/g;
// A가 최소 2번 이상 반복되는 문자열 검색한다.
const regExp = /A{2,}/g;
// A가 최소 한번 이상 반복되는 문자열을 검색한다.
const regExp = /A+/g;
// A가 0번 또는 최대 한번이상 반복되는 문자열을 의미하고, 이를 전역검색한다.
const regExp = /A?/g;OR 검색
// A 또는 B를 전역 검색한다.
const regExp = /A|B/g;
// A 또는 B를 한번 이상 반복하는 문자열을 전역 검색한다.
const regExp = /A+|B+/g;
// 위와 동치이다. []내의 문자는 or로 동작한다.
const regExp = /[AB]+/g;
// 범위 지정
const regExp = /[A-Z]+/g;
// 대소문자 구별 X, A~Z 또는 a~z 가 한번 이상 반복되는 문자열을 전역 검색한다.
const regExp = /[A-Za-z]+/g;
// 0~9가 한번 이상 반복되는 문자열을 전역 검색한다.
cosnt regExp = /[0-9]+/g;문자 클래스
\d --> 0에서 9 사이의 문자( === [0-9])
\s(공백) --> 스페이스, 탭(\t), 줄 바꿈(\n)을 비롯하여 아주 드물게 쓰이는 \v, \f, \r 을 포함하는 공백 기호
\w --> 문자, 숫자, 언더스코어 의미
// 0~9가 한 번 이상 반복되는 문자열을 전역 검색
const regExp = /[\d]+/g
const regEXp = /[0-9]+/g
// 알파벳, 숫자, 언더스코어가 들어간 문자열 전역 검색
const regExp = /[\w]+/g
const regExp = /A-Za-z0-9_]+/g반대 클래스
\D -> 0~9가 아닌 문자를 의미함
\W -> 알파벳, 숫자, 언더스코어가 아닌 문자를 의미함
NOT 검색
[...] 내의 ^은 not의 의미이다.
/[^0-9]/ === /[\D]/
/[^A-Za-z0-9_]/ === /[\W]/
시작 위치로 검색
[...] 밖의 ^ 문자열은 시작을 의미한다.
// https로 시작하는지 검사한다.
const regExp = /^https/;마지막 위치로 검색
$는 문자열의 마지막을 의미한다.
// com으로 끝나는지 검사한다.
const regExp = /com$/;알고리즘과 평소에 자주 사용하는 정규표현식 패턴
팰린드롬(회문)
영문자와 숫자만 고려한 팰린드롬
const isPalindrome = s => {
const temp = s.toLowerCase().replace(/[^a-z0-9]/g, '');
console.log(temp === temp.split('').reverse().join(''));
};전달받은 문자열 s를 소문자로 바꾸고 모든 공백을 제거한뒤, 남은 문자열을 가지고 거꾸로 뒤집은 문자열과 같다면 그 문자열을 팰린드롬이다.
replace(/\[^a-z0-9]/g, '')의 의미는 소문자 a~z와 0~9를 제외한 나머지 문자들을 ''(빈 문자열)로 대체하는 것!
카카오 알고리즘 문제 - 신규 아이디 추천
const solution = s => {
let recommended = s
.toLowerCase()
.replace(/[^\w-_.]/g, '')
.replace(/\.{2,}/g, '.')
.replace(/^\.|\.$/g, '')
.replace(/^$/g, 'a')
.substring(0, 15)
.replace(/\.$/g, '');
if (recommended.length <= 2) {
const ch = recommended[recommended.length - 1];
while (recommended.length <= 2) {
recommended += ch;
}
}
return recommended;
};
console.log(solution('...!@BaT#*..y.abcdefghijklm'));정규표현식을 이용하여 조건을 걸러준후, 나머지 조건을 조건문을 이용하면 간단하게 문제를 풀 수 있다.
특정 문자를 ~로
문자열에서 특정 문자가 A이고 모두 #으로 바꾸어야 한다고 하면 최신 문법 replaceAll('A', '#')함수를 사용하여도 되지만 정규표현식을 이용하면 다음과 같다.
const replaceAtoSharp = s => console.log(s.replace(/A/g, '#'));
replaceAtoSharp('BANANA'); // => B#N#N#A라는 문자를 모두 검색하여서 #으로 바꾸는 정규 표현식이다.
대문자 찾기
특정 문자열에서 대문자의 개수를 찾아라
const countUpperCase = s => console.log(s.match(/[A-Z]/g).length);
countUpperCase('KoreaTimeGood'); // => 3match함수를 이용하여 정규 표현식에 맞는 대문자들을 모두 찾아 그 배열의 길이를 반환하면 된다.
문자의 개수 찾기
특정 문자열이 주어지고 문자가 주어지면 그 문자열 안의 문자의 개수를 찾아라.
const count = (s, word) => console.log(s.match(new RegExp(word, 'g')).length);
count('COMPUTERPROGRAMMING', 'R'); // => 3바로 인수로 전달받은 word를 사용할 수 없기 때문에, new RegExp 생성자 함수를 사용하여 패턴에 word와 플래그를 string 형식으로 주고 그 길이를 찾으면 된다.
대소문자 변환
대문자는 소문자로, 소문자는 대문자로 변환하여 출력하여라
const toggleCase = s =>
console.log(
s.replace(/./g, str =>
str === str.toUpperCase() ? str.toLowerCase() : str.toUpperCase()
)
);
toggleCase('StuDY'); // => 'sTUdy'
이 경우는 정규 표현식을 어떠한 방법으로 사용해야 효율적인지 잘 모르겠다..
문자열 압축
const compress = s =>
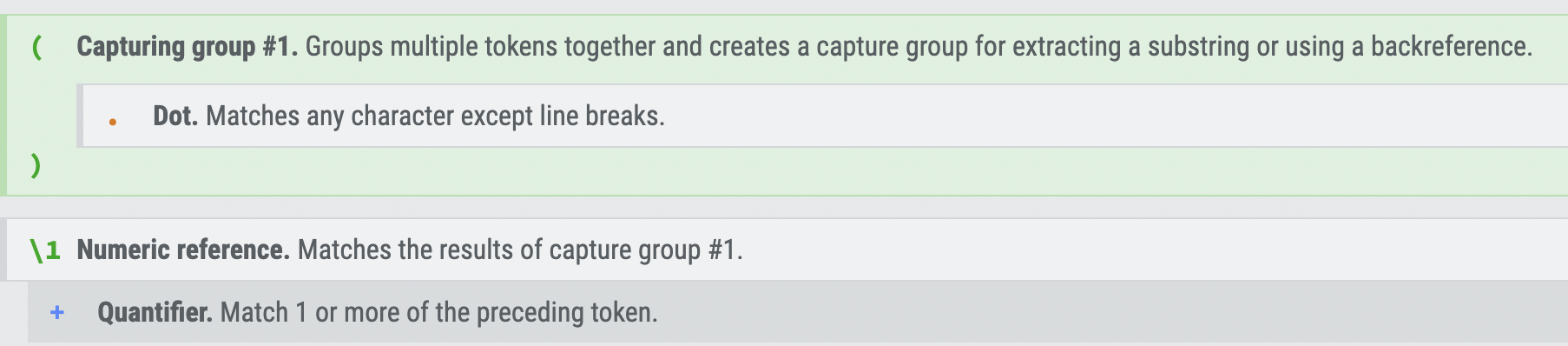
console.log(s.replace(/(.)\1+/g, match => match[0] + match.length));
compress('ABBCCCE'); // => AB2C3E(.)은 임의의문자열을 그룹으로 묶고, \1 그룹핑된 그룹의 첫 번째를 가리키며, +를 통해 1개 이상의 결과를 가리켜 최종적으로 BB와 CCC가 이에 해당이되고 해당 된 것들이 replace 2번째 콜백 함수의 인자로 들어가 결과를 반환하여 갖고 온다.
그외
특정 단어로 시작하는지 검사
'http://' 또는 'https://'로 시작하는지 검사
/^https?:\/\//.test(url);특정 단어로 끝나는지 검사
html로 끝나는지 검사
/html$/.test(fileName);숫자로만 이루어진 문자열인지 검사
/^\d+$/.test(target);하나 이상의 공백으로 시작하는지 검사
문자열이 하나 이상의 공백으로 시작하는지 검사
\s는 여러가지 공백 문자(스페이스, 탭 등)을 의미한다.
/^[\s]+/.test(target);아이디로 사용 가능한지 검사
알파벳 대소문자 또는 숫자로 시작하고 끝나며 4~10 자리인지 검사
/^[A-Za-z0-9]{4,10}$/.test(id);메일 주소 형식에 맞는지 검사
/^[0-9a-zA-Z]([-_\.]?[0-9a-zA-Z])*@[0-9a-zA-Z]([-_\.]?[0-9a-zA-Z])*\.[a-zA-Z]{2,3}$/.test(email); 핸드폰 번호 형식에 맞는지 검사
/^\d{3}-\d{3,4}-\d{4}$/.test(cellphone); 특수 문자 포함 여부 검사
(/[^A-Za-z0-9]/gi).test(target);정규표현식 연습 사이트
참고자료
