What is YOLO?
-You Only Look Once
-CNN로 학습한 feature로 object detect
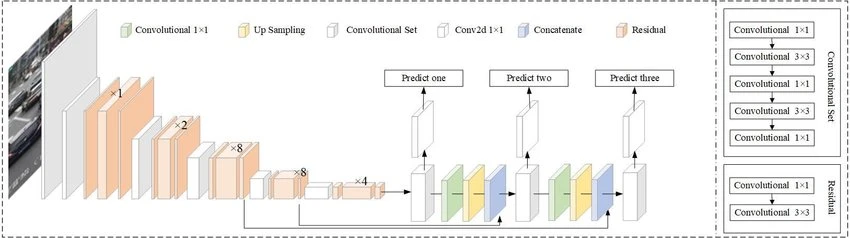
A Fully Convolutional Neural Network
-YOLO는 layer로 convolutional layer만 사용. 그러면서, FCN(fully CN)만 사용
- FCN이어서 input image의 size에 상관되지 않음
- 그러나 batch돌릴 때의 편리함도 그렇고, 모든 image가 같은 height와 width를 가지는 게 여러모로 편리함
-CN 75개
- skip connection
- upsampling layer
- downsampling layer: feature map을 downsample시키는 stride 2의 CN
- stride: downsampling factor
- 416Χ416 에서 stride가 32라면 output은 416/32=13Χ13임
- stride: downsampling factor
Interpreting the output
-CN에 의해 학습된 feature는 classifier/regressor로 감
- classifier/regressor: detection predict
- detection: bounding box의 좌표, class label 등
- predict: 1Χ1 CN으로 수행
- 이 prediction의 output: feature map
- 1Χ1 CN이므로 feature map size는 이전것과 똑같이 유지됨
- 이 map의 각 cell(=unit=neuron)은 일정 개수의 bounding box를 예측 가능
- B*(5+C) entry를 가짐
- B: 각 cell이 예측가능한 BB개수
- B개의 BB가 한 종류의 object를 나타낼 수 있음
- YOLO에서 B=3
- 5+C: BB 1개가 가지는 attribute(중심좌표, 차원, objectness score, C(class confidence))
- B: 각 cell이 예측가능한 BB개수
- object 중심이 cell의 receptive field에 들어온다면 그 cell들 1개당 object 1개를 predict할 것
- 이를 위해, 1)이 BB가 어느 cell의 것인지 알아야 함
- 그를 위해, input image를 최종 feature map과 같은 수치로 grid를 나눈다.
- BB의 center가 위치한 cell이 그 object를 predict하는 cell이 된다.
- 2)그 cell을 feature map에 detector로서 assign
- 3)그 cell(feature map의 것)은 3개의 BB예측 가능.
- 3개 중 어느 BB가 truth label일까? 이를 알기 위해, anchor를 알아야 한다.
- 이를 위해, 1)이 BB가 어느 cell의 것인지 알아야 함

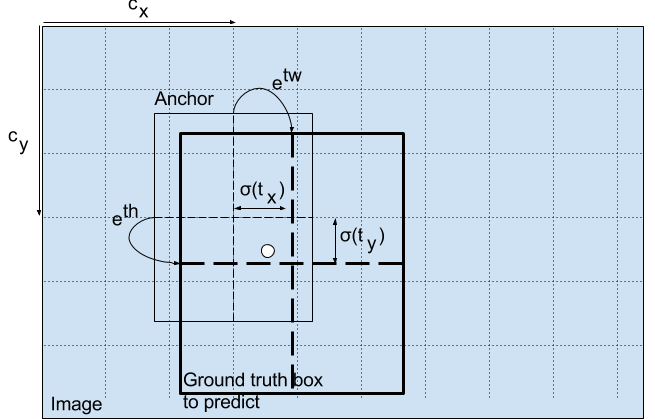
Anchor Boxes
- anchor: 예측하는 BB의 수치.
- Default BB를 기준으로 한 offset 또는 log-space transform
- YOLO v3: 3개의 anchor
- truth label을 나타내는 BB는, 그 BB의 anchor가 ground truth box와 가장 많이 겹치는 IoU를 가지고 있는 경우이다.
Making Predictions
-아래는 output이 prediction을 얻는 과정이다.
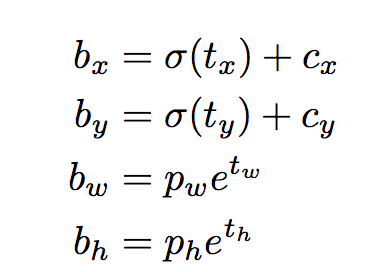
-bx,by,bw,bh: 중심좌표 x, y, width, height
-tx,ty,tw,th: network output에서의 중심좌표 x, y, width, height
-cx,cy: grid의 왼쪽 상단 x,y좌표
-pw,ph: box의 anchor dimension
중심 좌표
-sigmoid function을 통해 predict(output이 0~1이 되도록)
-보통 YOLO는 중심 좌표가 아닌 왼쪽 상단 좌표의 offset을 predict
Dimensions of the Bounding Box
-BB의 dimension: output에 log-space transform한 후 anchor곱하기
-결과 bw, bh: normalized된 것
Objectness Score
-object가 BB안에 있을 확률
-sigmoid를 거쳐감으로서 확률로 계산됨
Class Confidences
-그 class가 실제 object대로 분류됐을 확률
-sigmoid 사용(non-exclusive class)
Prediction across different scales
-YOLO는 3개의 다른 scale로 predict
-detection layer: detection을 3개의 다른 size로 수행
- stride가 각각 32,16,8
- input image downsample-->첫번째 detection layer(stride 32)에서 detect-->upsampling by 2-->이전 layer와 같은 수치를 가지는 feature map과 concatenate(합치기)-->두번째 detect(stride 16)-->upsampling by 2-->final detection(stride 8)
- 각 detect마다, 각 cell은 3개의 anchor를 사용해 3개의 BB예측
- 1개의 cell이 총 9개의 BB예측

Output Processing
-총 BB개수=((52x52)+(26x26)+(13x13))x3=10647
-그러나 object는 1개. 1개의 object에는 1개의 BB가 있어야 함. 10647개를 어떻게 1개로 만들 수 있을까?
Thresholding by Object Confidence
threshold objectness score보다 낮은 BB는 ignore
Non-maximum Suppression(NMS)

Our Implementation
-detector로 official weight를 사용할 것
-weight: COCO dataset으로 train
-80개의 object 종류
