셀레니움 문서 for python
셀레니움 문서 all lang
selenium
셀레니움이 웹브라우저를 띄워주며, 화면 스크롤, 키이벤트 등 동적사이트에서 데이트 크롤링을 할수 있게 한다.
how to use
install selenium
pip install selenium
셀레니움은 프로젝트 폴더에 설치하도록 한다. 굳이 전역에 설치하지 않아도 된다.
install chrome driver

크롬브라우저를 열고 chrome://version 을 입력한뒤 현재 내 컴퓨터의 크롬 버전 정보를 확인한다. 나는 80버전~
chrome driver 사이트에 방문하고 내 크롬 버전에 맞는 chrome driver를 다운로드 한다.
다운로드한 디렉토리 위치를 잘 확인하도록 한다!(혹은 파일의 위치를 변경한다)
import
from selenium import webdriver # 브라우저를 띄우기 위해서 필요
from selenium.webdriver.common.keys import Keys # 키이벤트를 주기 위해 필요
import time # 스크롤 텀을 주기 위해 필요webdriver는 firefox, chrome, ie등 브라우저 선택이 가능하다.Keys클래스 는 키보드 키들을 제공한다(e.g.return, f1, alt, cmd, shift ...)
exam code
스택오버플로우 셀레니움 무한스크롤 스크롤이벤트 하는 법에서 다양한 방법이 제시되었다.
execute_script()
그중 가장 많이 제시했던 방법은 execute_script('js작성가능') 메서드를 사용하는 것이 었는데, js코드를 인자로 넣을 수 있어 브라우저 화면을 제어 할수 있게 된다. 스크롤을 하기 위해 뿐만아니라 다른 동적이벤트를 작성할 수 있다.
- 화면상 스크롤 위치 이동 :
scrollTo(x,Y),scrollTo(x,Y+number) - 화면 최하단으로 스크롤 이동 :
scrollTo(0, document.body.scrollHeight) - 화면을 움직이고 페이지 로드 기다리기 :
time.sleep(second)
SCROLL_PAUSE_TIME = 0.5
# Get scroll height
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
# Scroll down to bottom
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# Wait to load page
time.sleep(SCROLL_PAUSE_TIME)
# Calculate new scroll height and compare with last scroll height
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
break
last_height = new_heightsend_keys()
그리고 정말 단순해 보이는 send_keys(Keys.PAGE_DOWN) 키이벤트 방식이 있었다.send_Keys() 메서드를 적용하기 위해서는 요소를 가져와야 하는 제약이 있음에도 코드는 훨씬 간결하다(javascript를 안써도 되고)!
label.send_keys(Keys.PAGE_DOWN);전체 코드
이전 포스팅에서 실패한 빌보드차트 이미지크롤링을 하는 코드를 작성했다.
from bs4 import BeautifulSoup # 셀레니움으로 이벤트를 한뒤 beautifulsoup으로 요소 정리, 그냥 셀레니움으로 해도된당
from selenium import webdriver # 브라우저를 열수 있는 드라이브모듈
from selenium.webdriver.common.keys import Keys # 키이벤트를 돕는 키 모듈
import csv, time
# csv저장
output = 'test_crawling_02.csv'
csv_open = open(output, 'w+', encoding='utf-8')
csv_writer = csv.writer(csv_open)
csv_writer.writerow(('index','title','artist', 'image_url'))
# 크롤링 url, html 받아오기
orig_url = 'https://www.billboard.com/charts/billboard-200' # 크롤링 할 사이트
driver = webdriver.Chrome('/Users/hwang/dev/chromedriver') # 크롬 브라우저 선택
driver.implicitly_wait(10) # 숫자 크면 잘 읽히는 기붕..
driver.get(orig_url) # 입력한 경로의 정보 긁어볼까요~?
body = driver.find_element_by_css_selector('body') # send_keys()메서드 사용을 위한 body가져오기
for i in range(15): # 11번 ~ 최하단 20번
body.send_keys(Keys.PAGE_DOWN) # 페이지 다운 키를 20회 반복한다.
time.sleep(0.1) # 페이지 로드 대기, 숫자가 크면 안읽히는건 왤까요?
# beautifulsoup 사용 하기 준비
html = driver.page_source # html을 문자열로 가져온다.
driver.close() # 크롬드라이버 닫기
# beautifulsoup 사용하기
soup = BeautifulSoup(html,'html.parser')
top_200_list = soup.find_all( 'li', {'class' : re.compile('chart-list__element')} )
for li in top_200_list[:100]:
# 혹시라도 이미지가 비었을때를 대비 하여 아래 함수 추가
def check_image_url():
value = bool(li.find('span', {'class':'chart-element__image'})['style'] != 'display: inline-block;')
if value:
return li.find('span', {'class':'chart-element__image'})['style'].split('"')[1]
return None
# * re.compile() 과 class_='' 의 차이는 ?..
index = li.find('span', {'class':'chart-element__rank__number'}).text
title = li.find('span', {'class':'chart-element__information__song'}).text
artist = li.find('span', {'class':'chart-element__information__artist'}).text
image_url = check_image_url()
# CSV 에 저장하자
csv_writer.writerow((index, title, artist, image_url))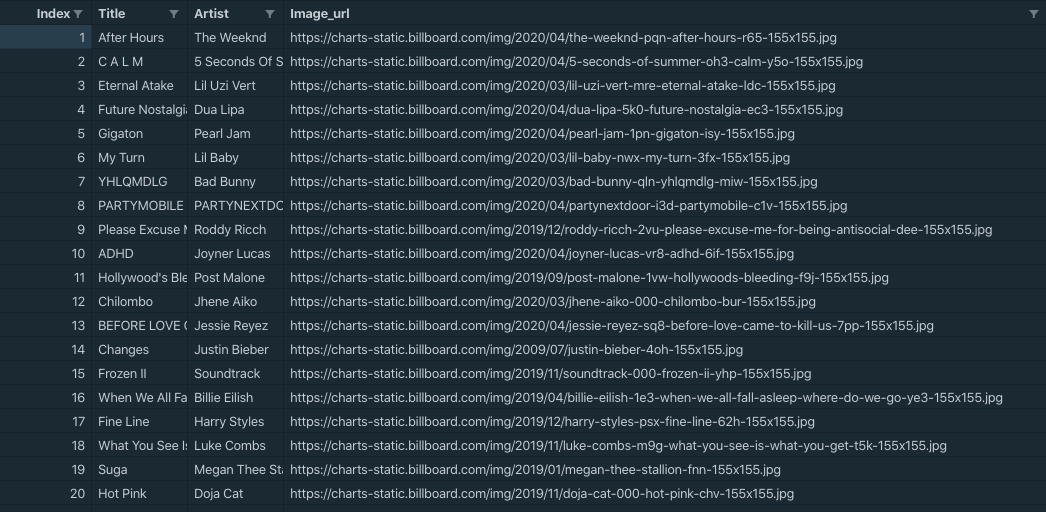
위와 같이 원하는 정보가 잘 들어왔다!

TIL 기록 블로그 :: 문제가 있는 글엔 댓글 부탁드려요!