인지 기술
자율주행 인지 단계는 자율주행 차량이 주변 환경을 이해하고 파악하는 단계로, 다양한 센서들을 활용해 주변 환경을 감지하고 이해하는 과정이 이루어진다. 구체적으로 객체를 검출하여 인식하고, 인식한 객체의 움직임을 추적/예측하는 모든 과정이 포함된다.
동적 객체 검출/추적, 예측
동적 객체라 하면 시간에 따라 움직임을 갖는 객체로, 주변 차량이나 보행자 등을 의미한다. 인지 단계에서는 동적 객체에 대해 인식하여 어떤 객체인지 판별하고 기준 차량으로부터의 거리 등을 계산해 객체를 검출한다. 검출한 객체를 대상으로 t 시점 해당 객체와 t+1 시점의 객체를 연결지어 객체를 추적한다.
이렇게 추적한 동적 객체의 tracking을 바탕으로 분석하여 해당 객체가 미래에 어떻게 움직일 것인지를 예측한다. 이를 바탕으로 자율주행의 판단 및 계획을 수립할 수 있다.
정적 객체 인식
정적 객체라면 시간에 따라 움직이지 않는 객체로, 신호등과 표지판, 횡단보도 등을 말한다. 인지 단계에서 이런 정적 객체의 종류와 위치를 파악하여 인식한다. 인식된 상황을 바탕으로 주행을 하도록 하거나 정밀지도 제작에 기여할 수 있다.
자율주행 센서 구성
자율주행을 위한 대표적인 센서는 다음과 같다.
카메라
주변 환경의 광학적 이미지를 전기적 신호로 변환하는 장치로,
빛이 렌즈를 통해 들어오면 이미지 센서(CCD, CMOS)를 통해 빛의 강도와 색을 전기적 신호로 변환하여 2차원 배열로 저장
- ↑ : 고해상도 이미지 제공, 비교적 저렴한 가격
- ↓ : 고해상도 이미지에 따른 많은 계산량, 외부 요인에 민감
레이다 (RADAR)
전자기파(마이크로파)를 발사하여 반사파를 분석함으로써 객체의 위치, 속도를 파악
- ↑ : 외부 요인에 강인, 비교적 저렴한 가격
- ↓ : 주변 환경의 반사 신호로 인해 간섭(클러터)으로 오탐률, 낮은 해상도
라이다 (LIDAR)
레이저 펄스를 주변으로 발사해 객체에 반사되어 되돌아오는 시간을 측정해 거리를 계산하여 객체의 위치, 모양, 크기를 파악
- ↑ : 정밀한 측정 가능, 외부 요인에 강인
- ↓ : 비싼 가격, 습기가 있을 경우 산란되어 성능 저하
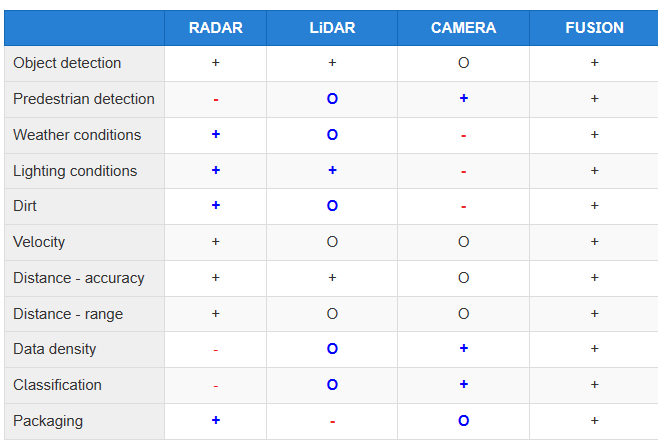
센서 퓨전
위 각각의 센서는 고유의 한계를 가진다. 예를 들어 카메라는 조명이나 반사로 인해 정보가 왜곡될 수 있고, 레이다는 날씨 조건에 강하지만 낮은 해상도를 갖고, 라이다는 고해상도 거리 측정에 유리하지만 높은 비용을 수반한다.
따라서 여러 센서로부터 얻은 데이터를 통합해 사용하는 센서 퓨전(Sensor Fusion)을 통해 보다 정확한 수 있는 정보를 생성할 수 있다. 센서 퓨전은 크게 세 가지 수준으로 분류될 수 있다.
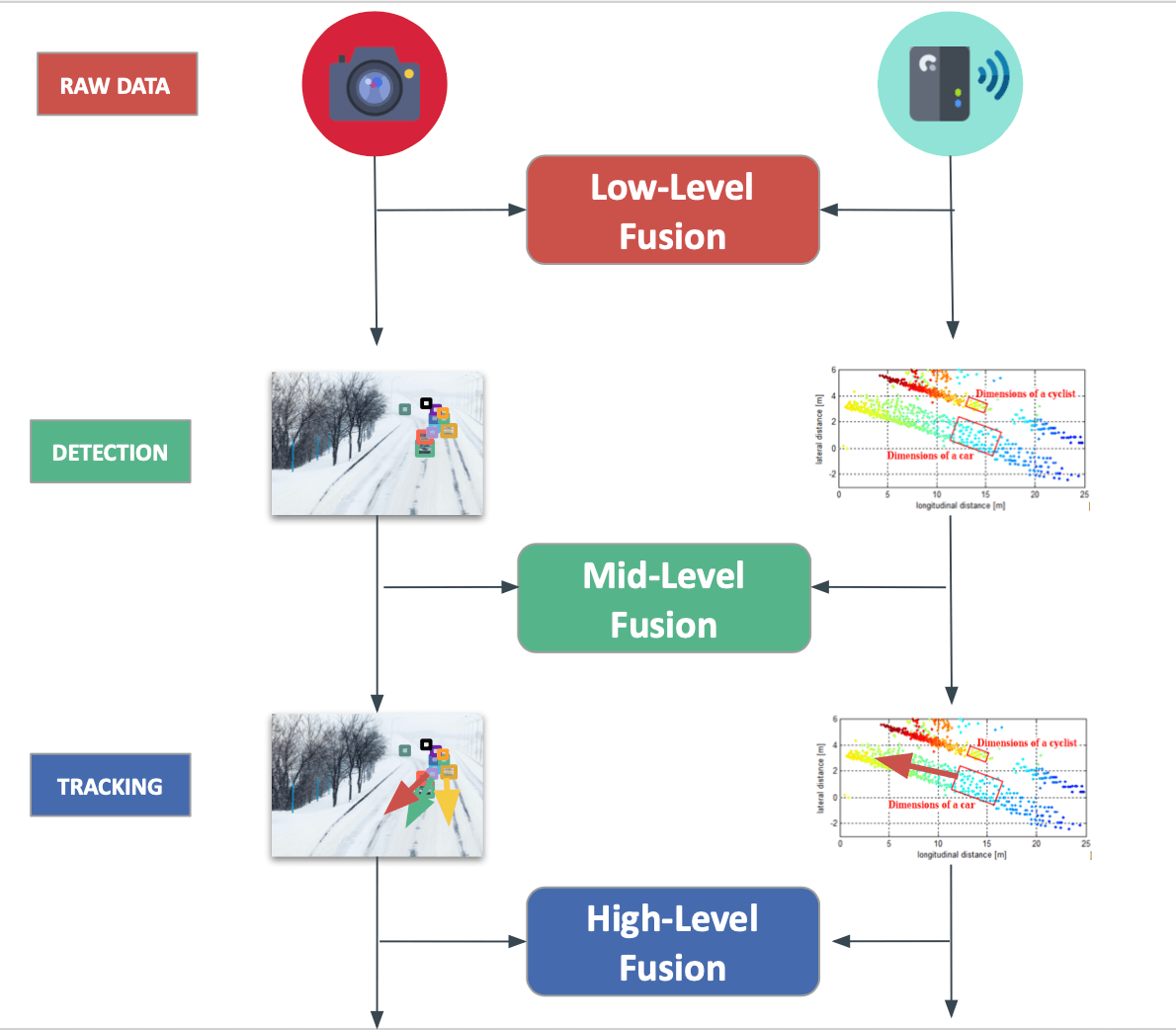
- Low-level Fusion : 여러 센서로부터 얻은 데이터를 직접 통합한다. 복잡한 알고리즘의 필요 없이 단순한 통합으로 실시간 처리에 유리하지만 데이터 중복과 병합의 문제를 갖는다.
- Feature-level Fusion : 각 센서의 특징이 추출되고 이러한 특징들이 결합되어 더 유용한 정보를 생성한다. 더 복잡하고 효율적인 데이터 처리가 가능하며 센서에서 추출된 특징들의 결합으로 높은 신뢰성을 갖는다.
- Decision-level Fusion : 각 센서에서 독립적으로 내린 의사결정(객체 식별 등)을 통합하여 최종 의사결정을 내린다. 각 센서의 특성을 고려하여 보다 강력한 의사 결정을 할 수 있지만 통합 과정에서 복잡한 로직이 요구될 수 있다.
인지 기술의 과제
대부분의 자율주행 차량에서 발생한 사고에서, 정확한 인지 작업이 되지 않아 발생한다. 예측하기 힘든 다양한 도로 환경에 대해 여러 인지 오작동 발생 시 자율주행의 모든 프로세스가 무력화되어 사고가 발생하기 때문에 100%에 가까운 정확도를 필요로 한다.
- 다양한 환경 조건에서도 안정적으로 작동할 수 있는 센서 기술과 함께 센서 데이터를 보정/최적화하는 알고리즘 개발
-동적 환경에서도 정확한 인식과 예측을 위해 딥러닝 기반 고급 인지 알고리즘 개발 - 효율적인 센서 퓨전 기술 개발
딥러닝 활용
CNN (Convolutional Neureal Network)
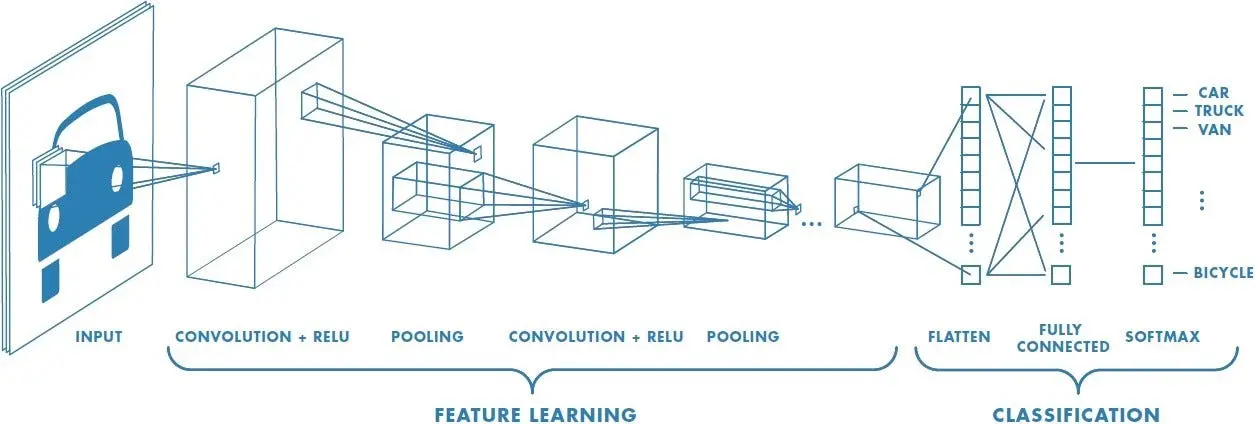
CNN은 다층 구조를 통해 여러 계층에서 이미지의 다양한 특징을 계층적으로 학습할 수 있어 특히 이미지 인식 및 이해에 있어 강점을 갖는 신경망이다. 자율주행 환경에서 카메라 영상을 입력으로 하여 공간적 이미지의 특징을 추출함으로써 목적에 맞게 사용할 수 있다. 따라서 CNN을 인지 기술에서 활용하는 예는 다음과 같다.
- 객체 인식, 분류 : 주변 환경에서 동적, 정적 객체의 다양한 객체를 인식하고 분류할 수 있다. YOLO(You Only Look Once), SSD(Single Shot MultiBox Detector)는 실시간 객체 감지를 위해 흔히 사용되는 신경망 아키텍쳐이다.
- 차선 검출 : 입력 이미지에서 차선의 형태와 경계를 인식할 수 있다.
- 환경 인지 및 3D 매핑 : 공간적 특징을 추출해 주변 환경의 3D 구조를 재구성하여 주변 환경을 정확히 이해할 수 있도록 한다.
RNN (Recurrent Neural Network)
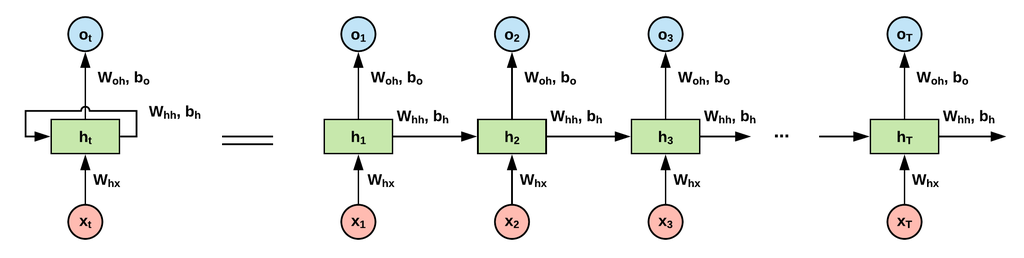
RNN은 순환 구조를 갖고 있어 순차적인 데이터나 시계열 데이터를 처리하는 데 특히 효과적인 신경망으로, 이러한 특성을 활용하여 자율주행에서 다양한 응용이 가능하다.
- 주행 경로 예측 : 차량 위치, 속력, 주변 차량의 위치와 같은 시계열 데이터를 입력으로 받아 패턴을 학습하고, 이전 시간 단계의 정보를 현재 시간 단계의 예측에 활용하여 주행 경로 예측에 활용된다.
LSTM (Long Short Term Memory)
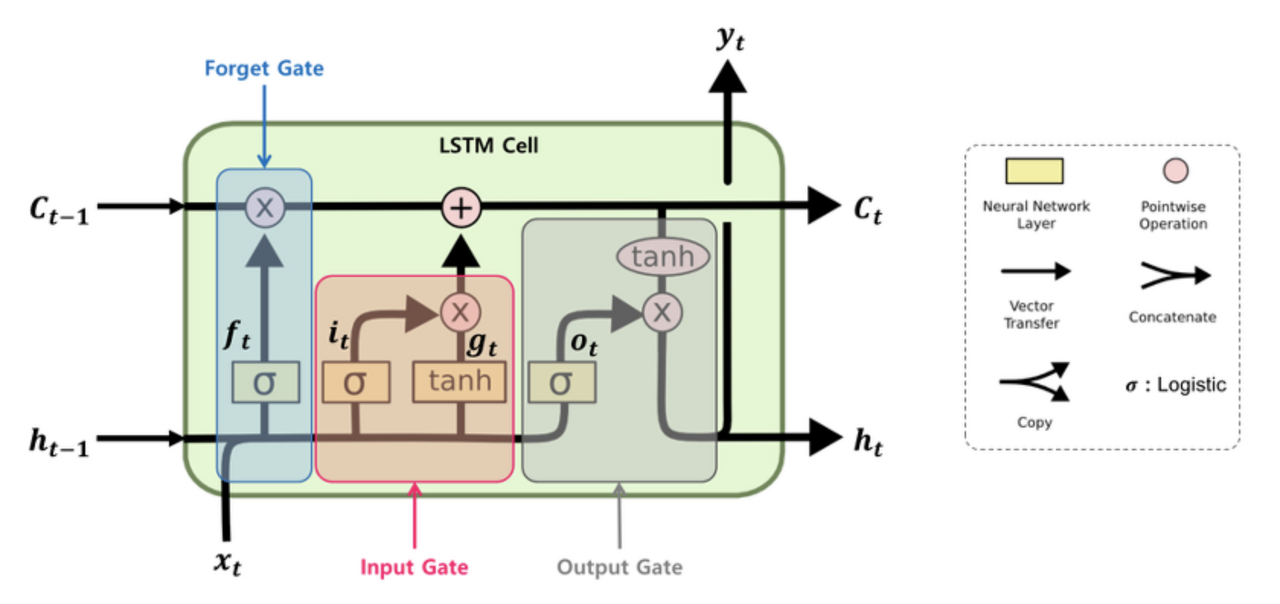
전통적인 RNN에서는 입력 시퀀스 길이가 길어지면 시간에 따라 장기 의존성(Long-Term Dependencies)으로 인해 학습이 제대로 되지 않아 이를 해결하기 위해 LSTM이 개발되었다.
LSTM은 위와 같이 두 벡터(Ct : Cell state, ht : hidden state)와 3개의 게이트(input, forget, output gate)를 갖는다. 다음은 각 요소에 대한 설명이다.
- Cell state : 셀 상태는 LSTM의 핵심 메모리 부분으로, 장기적인 정보를 저장하고 전달한다. Gate 메커니즘에 의해 업데이트된다.
- hidden stae : 현재 시점 단계의 출력으로 사용된다. LSTM은 입력 x(t)와 h(t-1)를 기반으로 h(t)를 계산한다. 이는 다시 t+1 단계의 입력으로 사용된다.
- Input gate : 현재 시점 단계의 입력에 대한 가중치를 결정 (이번 입력을 얼마나 반영할지)
- Forget gate : 이전 셀 상태에서 어떤 정보를 정보를 망각할지 결정하여 불필요한 정보 제거 (과거 정보를 얼마나 까먹을지)
- Output gate : 다음 시점 단계의 hidden state에 대해 가중치를 결정하여 다음 단계로 전달 (이번 정보를 얼마나 내보낼지)
측위 기술
측위 기술은 자율주행 차량이 현재 위치를 정확하게 파악하는 데 사용된다. 측위 정보를 활용해 센서가 감지하는 정보를 보완할 수 있다.
GPS (Global Positioning System)
GPS는 위성을 통해 전 세계적으로 정확한 위치 정보를 제공하는 인공위성 네비게이션 시스템으로, 전파 상황에 따라 정밀도가 좌우되고 위치 오차가 미터 단위이기 때문에 자율주행에 직접적으로 활용하기는 어렵다.
GNSS (Global Navigation Satellite System)
GNSS는 GPS뿐만 아니라 GLONASS, Galileo, BeiDou 등과 같은 다른 위성 네비게이션 시스템을 포함하여 다양한 시스템을 결합하여 위치 정확성을 향상
IMU (Inertial Measurement Unit)
IMU는 가속도계와 자이로스코프를 포함하여 차량의 가속도와 각속도를 측정하는 장치이다. IMU를 사용하여 초기 위치 추정 및 주행 중의 위치 보정에 활용할 수 있지만, 시간이 지남에 따라 오차가 누적되므로 정확한 위치 추정을 위해서는 다른 측위 기술과 결합되어 사용해야 한다.
Odometry
Odometry는 바퀴의 회전량과 이동 거리를 측정하여 차량의 상대적인 위치와 이동 경로를 추정한다. 상대적 위치 추정에 사용되므로 초기 위치 정보가 필요하며 시간이 지남에 따라 오차가 누적되므로 보통 다른 측위 기술과 결합하여 사용한다.
고정밀 지도 기반 측위 기술
cm 단위 정확도를 갖는 고정밀 지도를 사전에 구축한 뒤 활용함으로써 인지 기술의 부담을 덜어줄 수 있다. 도로 주행 환경이 바뀔 때마다 OTA(Over The Air)를 통해 새로운 지도 정보를 차량에 무선 전송하여 이용할 수 있다.
사전 정의된 고정밀 지도를 기반으로 센서 정보를 맵매칭하여 측위를 수행한다. 센싱 정보에만 의존하여 위치를 파악하는 방법보다 정확한 로컬라이제이션이 가능하다. 또한 정밀 지도에 정의된 차로 정보나 교통 정보를 반영하여 주행 상황을 예측할 수 있다는 장점을 갖는다.
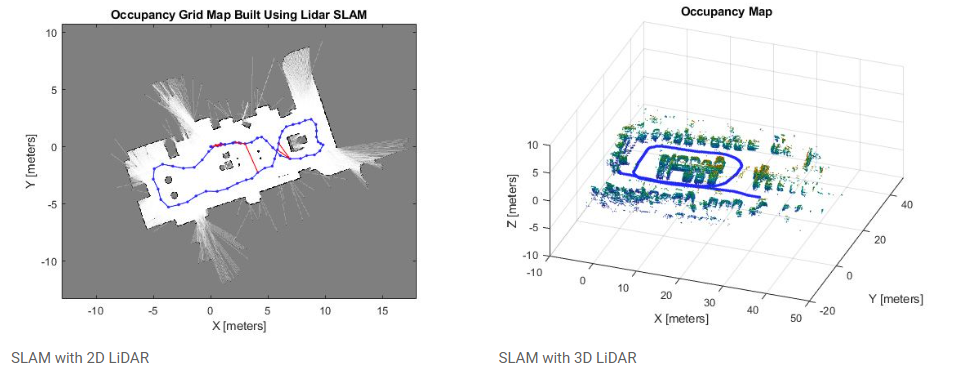
SLAM (Simultaneous Localization And Mapping)
SLAM은 자율주행 차량이 자신의 위치를 추정하는 동시에 주변 환경의 지도를 작성하는 기술로, 차량이 이동하면서 주변 환경을 탐색하고 이 정보를 사용하여 자신의 위치를 파악하고 주변 환경의 지도를 작성하는 것을 의미한다.
SLAM = Localization + Mapping
-
환경 탐색 및 데이터 수집 : 차량이 이동하며 주변 환경을 탐색하면서 센서들을 통해 주변 환경의 지형, 건물, 장애물 등의 정보를 수집한다.
-
Loacalization : 수집된 센서 데이터를 기반으로 자율주행 차량이 자신의 현재 위치를 추정한다.
-
지도 작성 : 수집된 데이터를 기반으로 주변 환경의 지도를 작성한다. 이는 주변 환경의 지형, 건물, 도로, 장애물 등의 정보를 포함한다. 이러한 지도는 이후의 위치 추정에 사용된다.
-
지도 업데이트 : 이동하면서 새로운 데이터를 수집하면, 이를 사용하여 지도를 업데이트한다. 이를 통해 SLAM은 환경의 변화를 감지하고 지도를 최신 상태로 유지할 수 있다.
위와 같은 과정을 통해 진행되며 사용되는 센서의 종류에 따라 Visual SLAM, LIDAR SLAM 등으로 분류할 수 있다.
