SQL
: SQL이란 Structured Query Language의 약자다. 우리는 SQL을 사용하여, 데이터 베이스에서 저장된 데이터를 찾을 수 도 있고, 새로운 데이터를 만들고 삭제하고 업데이트를 할 수 있다(CRUD). 즉, SQL은 데이터 베이스와 대화할 수 있는 언어이다.
SQL 문법을 많이 알면 좋지만, 나와 같은 초보자들은 가장 많이 사용되는 것들을 먼저 알고 차차 알아가도록 하자.
문법을 알아보기 전에 알아두면 용어들
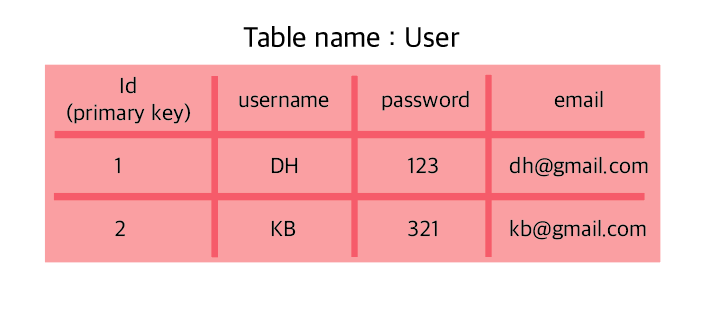
-
record(row) : 한 테이블의 모든 정보를 뜻한다. 위의 그림으로 봤을때,
[1, DH, 123 , dh@gmail.com]이 한줄이 record이고 row라고 부르기도 한다. -
column(field) : 칼럼 또는 필드라고 불리는것은 카테고리를 뜻한다. 위의 그림에서는
[id, username, password, email]이 해당된다. -
primary key(PK) : PK라고 불리는 이것은 record들의 고유 키이다. 즉 pk는 식별이 가능하게 해준다. 사람으로 예를 들면 사람들의 고유 키는 주민등록번호이다.
-
foreign key(FK) : FK는 1대n관계에서 다른 테이블의 값을 참조할때 사용한다.
SELECT
: SELECT 데이터 베이스에서 data를 선택하는 문법이다.
사용법
SELECT column1, column2, ... FROM table_name;
여기서 colum1과 column2는 데이터 베이스 테이블의 field names 이다.
만약에 데이터 베이스필드에서 모든것을 select하고 싶으면 *을 사용하면된다.
SELECT * FROM table_name
SELECT DISTINCT Statement
: SELECT DISTINCT는 데이터 베이스 테이블에서 중복되어지는것들을 제외한것들만 보여주는 역할을 한다.
사용법
SELECT DISTINCT column1, column2, ... FROM table_name;
WHERE Clause
: WHERE는 필터링 효과를 가지고 있다. SELECT로 원하는 카테고리(field)를 선택한 후 카테고리 안에서 내가 원하는 정보(record)만 골라서 볼 수 있다.
사용법
SELECT column1, column2, ... FROM table_name WHERE condition;
AND, OR and NOT Operators
: 위의 연산자는 WHERE와 같이 사용되어진다.
또한 위의 연산자들을 같이 사용 할 수 도 있다.
(연산자들 같이 사용된 예시 보기)
사용법
- AND Syntax
SELECT column1, column2, ... FROM table_name WHERE condition1 AND condition2 AND condition3 ...;
-
OR Syntax
SELECT column1, column2, ... FROM table_name WHERE condition1 OR condition2 OR condition3 ...; -
NOT Syntax
SELECT column1, column2, ... FROM table_name WHERE NOT condition;
ORDER BY Keyword
: ORDER는 정보(records)를 정렬해주는 키워드이다. defualt값으로 오름차순이고, 만약 내림차순으로 하고싶으면 DESC 라는 키워드를 사용하면 된다.
사용법
SELECT column1, column2, ... FROM table_name ORDER BY column1, column2, ... ASC|DESC;
INSERT INTO Statement
: INSERT INTO는 새로운 정보들(records)을 데이터 베이스 테이블에 추가 시켜주는 기능을 가지고 있다.
2가지 사용법
-
첫번째 방법은 '지정해주기'다. fields와 values를 지정하면 된다.
INSERT INTO table_name (column1, column2, column3, ...) VALUES (value1, value2, value3, ...); -
두번째는 데이터 베이스 테이블에 존재하는 모든 field에 values를 넣고자 할때 사용한다.
INSERT INTO table_name VALUES (value1, value2, value3, ...);
구체적인 예제
INSERT INTO Customers (CustomerName, ContactName, Address, City, PostalCode, Country) VALUES ('Cardinal','Tom B. Erichsen','Skagen 21','Stavanger','4006','Norway');
순대서대로 짝을 이루어서 넣는다.
CustomerName = Cardinal,
ContactName = Tom B. Erichsen,
...
Country = Norway
이런 식으로 !
NULL Value
: NULL은 field가 value를 가지고 있지 않을때, null로 나타낸다.
여기서 주의점은 null은 zero value와 빈칸과는 다르다.
NULL을 테스트 하는방법
SELECT column_names FROM table_name WHERE column_name IS NULL; // 또는 WHERE column_name IS NOT NULL;
UPDATE Statement
: UPDATE는 말 그래도 정보(record)를 업데이트하는 기능을 가지고 있다.
사용법
UPDATE table_name SET column1 = value1, column2 = value2, ... WHERE condition;
UPDATE를 사용할때 주의점 !!
- WHERE을 생략하면 안됨 !! 생략하면 모든 colunm1과 colunm2의 value가 변경된다.
DELETE Statement
: 지우는데 사용된다.
사용법
DELETE FROM table_name WHERE condition;
모든 정보를 다 지우고 싶을땐,
DELETE FROM table_name;
이렇게 하면 데이터 베이스 테이블에 모든 records가 지워진다.
COUNT(), AVG() and SUM() Functions
: 이름 그대로 숫자를 세고, 평균을 내고, 더한 값을 리턴한다.
사용법
COUNT() Syntax
SELECT COUNT(column_name) FROM table_name WHERE condition;
AVG() Syntax
SELECT AVG(column_name) FROM table_name WHERE condition;
SUM() Syntax
SELECT SUM(column_name) FROM table_name WHERE condition;
LIKE Operator (공식문서 참고하기)
: LIKE 는 WHERE에서 사용되어지며, 좀 더 구체적인 정보를 찾기 위해서 사용한다.
좀 더 자세히 이야기하면 column에 특정한 패턴(예, a로 시작하는)에 맞는 정보를 찾아낸다.
패턴중에서 자주 사용되어지는 패턴은 % 와 _ 이다.
% - zero,one 또는 멀티플한 알파벳을 의미한다.
_ - 단 하나의 알파벳만 의미한다.
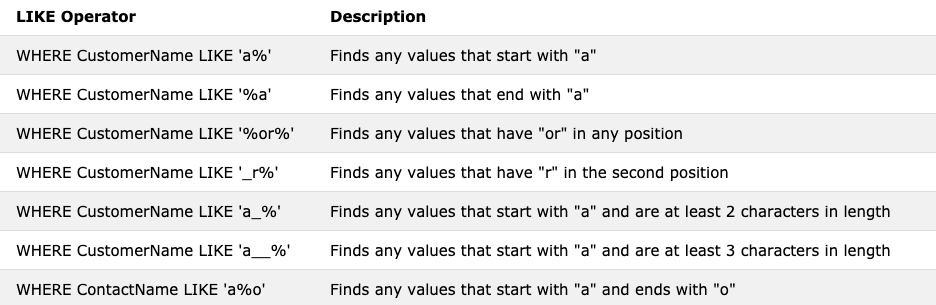
사용법
SELECT column1, column2, ... FROM table_name WHERE columnN LIKE pattern;
Aliases
: aliases 는 테이블, 필드(컬럼)에게 닉네임을 주는 역할을 한다. 닉네임을 주는 이유는 좀 더 읽기 쉽고, 알아보기 위해서 한다.
주의점은 aliases는 사용된 쿼리문에서만 효력을 발행한는점이다.
사용법
// 칼럼에 사용했을때, SELECT column_name AS alias_name FROM table_name; // 테이블에 사용했을때, SELECT column_name(s) FROM table_name AS alias_name;
Joins
: JOIN은 여러테이블의 rows들을 합치는데 사용된다.
JOIN에는 inner와 outer조인 이 두가지로 나눌 수 있다.
inner join : 이너 조인은 교집합이다. 두개의 테이블에서 조건이 맞는 레코드 또는 밸류를 리턴한다.
outer join
- left join and right join : 레프트와 라이트 조인의 작동하는 방식은 같다. 차이는 단순하게 어떤 테이블을 기준으로 할 것인지이다.
레프트 조인은 왼쪽 테이블의 레코드를 다 불러오고, 오른쪽으로 부터 조건이 맞는 밸류들을 가지고 온다.
반대로 라이트 조인은 오른쪽 테이블의 레코드느 다 가지고 오고, 조건이 맞는 왼쪽 밸류들만 가지고 온다.
**조건이 틀리면 NULL로 표기된다.

GROUP BY Statement
: Group by 는 같은 밸류를 가지고 있는 rows를 그룹화 한다. 이 statement 는 주로 count,max, min, sum 과 같이 사용된다.
group by 공식문서를 꼭 참조하자.
사용법
SELECT column_name(s) FROM table_name WHERE condition GROUP BY column_name(s) ORDER BY column_name(s);
공식문서의 첫번째 예로 보충 설명을 하자면,
3 - Argentina
2 - Austria
2 - Belgium
...
try를 눌러보면 위와 같은 결과를 얻을 수 있는데, 이 뜻은 아르헨티나 국적을 가진 사람이 3명이라는 뜻이다.
공부하고 나서 아래 튜토리얼로 나를 테스트해보자(참고로 나는 100점 !)
W3 페이지
