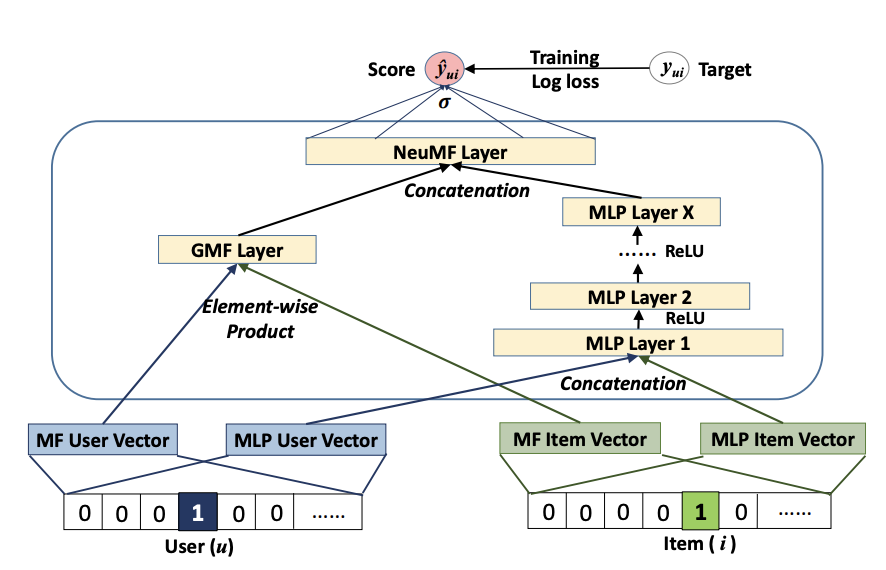
📌 Neural Collaborative Filtering
📖 Abstract
해당 논문은 암시적 피드백을 기반으로 추천의 주요 문제를 해결하기 위해 신경망 기반 기술을 개발한다.
기존의 방식인(MF) 내적 곱을 사용하여 사용자와 특성 사이의 상호 작용을 모델링하는 대신, 저자들은 신경망 구조로 내적 곱을 대체함으로써 NCF라는 범용적 프레임워크를 제안한다.
NCF는 프레임워크 내에서 행렬 인수분해를(MF) 표현하고 일반화할 수 있으며, NCF 모델에 비선형성을 더하고자 다층 퍼셉트론을 활용하여 사용자-항목 상호작용 함수를 학습하는 것을 제안한다.
📖 Introduction
Netflix Prize로 인해 유명해진 MF는 협업 필터링에서 효과적이지만, 내적 곱이라는 간단한 상호작용 함수 선택으로 인해 성능이 제약될 수 있다.
내적 곱은 잠재 특성의 곱을 단순한 선형 방식으로 결합하는 것으로, 사용자 상호작용 데이터의 복잡한 구조를 완벽하게 표현하기에는 부족할 수 있다.
본 논문은 협업 필터링을 위한 신경망 모델링 접근 방법을 형식화함으로써 MF의 한계점을 개선하고자 한다.
Contribution
- 사용자와 항목의 잠재적 특성을 모델링하기 위해 신경망 구조를 제시하고, 신경망을 기반으로 한 협업 필터링을 위한 NCF라는 범용 프레임워크 개발
- MF를 NCF의 특수화로 해석할 수 있음을 보여주고, 다층 퍼셉트론을 활용하여 NCF 모델링에 높은 수준의 비선형성을 부여
- 두 개의 실제 데이터셋에서 실험을 수행하여 NCF의 효과를 입증함으로써 협업 필터링을 위한 딥러닝의 잠재 능력 보임
📖 Background
1. Learning from Implicit Data
!

암시적 피드백이란 비디오 시청, 제품 구매 및 항목 클릭과 같은 행동을 통해 간접적으로 사용자의 선호도를 반영할 수 있는 신호를 의미한다.
등급, 리뷰와 같은 명시적 피드백과 대조된다.
이러한 특징으로 인해 암시적 데이터를 학습하는 데에는 몇가지 어려움이 발생한다.
- 사용자 i와 아이템 j간의 상호작용이 존재한다는 것의 의미는 사용자 i가 아이템 j를 좋아한다는 의미가 아닐 수 있다.
- 사용자 i와 아이템 j간의 상호작용이 존재하지 않는다는 것의 의미는 반드시 좋아하지 않는다는 것을 의미하는 것은 아니며, 사용자 i가 아직 아이템 j를 발견하지 못했을 가능성이 있다.
암시적 피드백과 관련된 추천 문제는 Y의 관찰되지 않은 항목에 대한 점수를 추정하는 문제로 정의되며, 이 점수는 항목을 순위 지정하는 데 사용된다.
모델 기반 접근 방식은 를 학습하는 것으로 추상화할 수 있다.
상호작용의 예측된 점수
모델 매개변수
모델 매개변수를 에측된 점수로 매핑하는 함수(상호 작용 함수)
모델의 매개변수 를 추정하기 위해 목적함수를 최적화하는 유형은 다음과 같다.
- pointwise loss : 일반적으로 와 목표 값인 차의 제곱 손실을 최소화하는 회귀 프레임워크를 따른다.
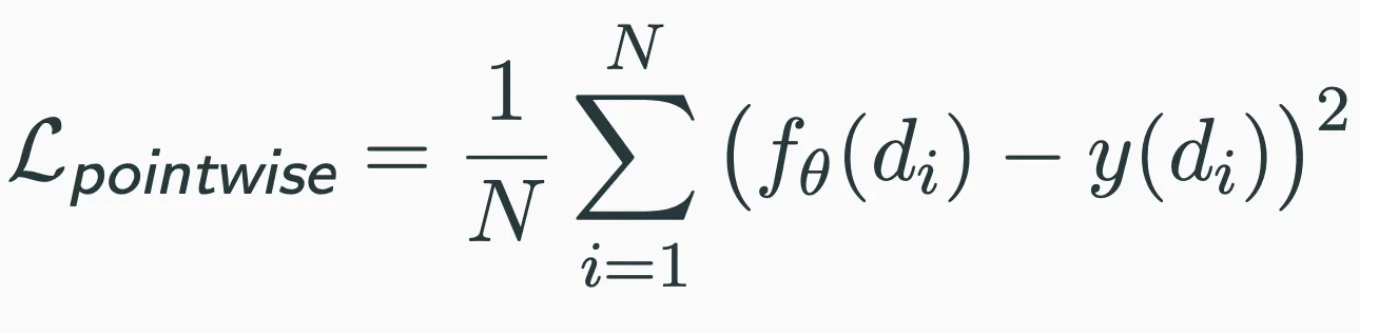
- pairwise loss : 관찰된 item은 관찰되지 않은 item보다 높은 순위여야 한다는 아이디어에 따라, 관찰된 항목의 와 관찰되지 않은 항목의 사이의 마진을 최대화하는 방식을 따른다.
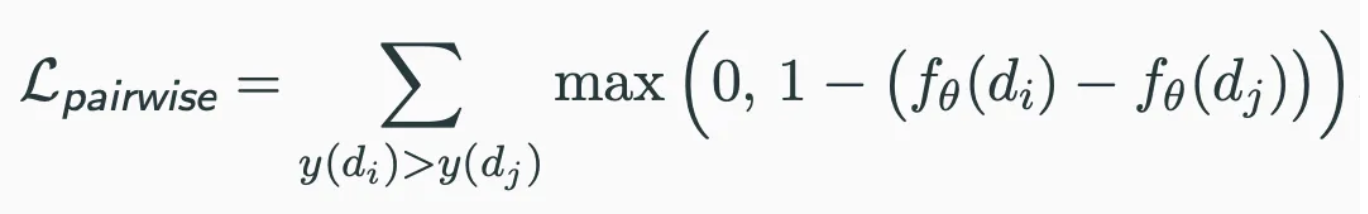
NCF 프레임워크는 신경망을 로 사용하여 pointwise loss와 pairwise loss 모두 지원한다.
2. Matrix Factorization
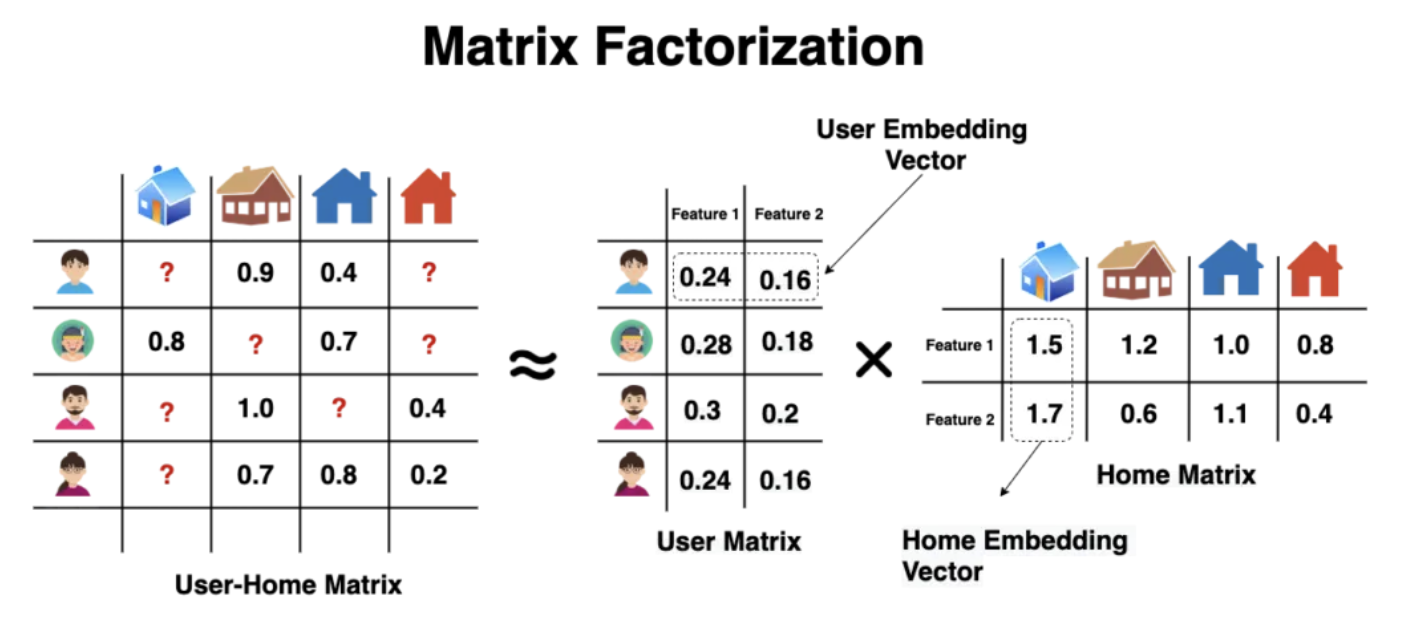
잠재 벡터
잠재 벡터
: 잠재 공간의 차원
MF는 상호작용 를 와 의 내적으로 추정한다.
MF는 user와 item의 잠재적인 요소 간의 양방향 상호작용을 모델링하며,
잠재 공간의 각 차원이 서로 독립이며 동일한 가중치로 선형적으로 결합된다고 가정한다.
따라서 MF는 잠재적인 요소의 선형 모델로 간주될 수 있다.
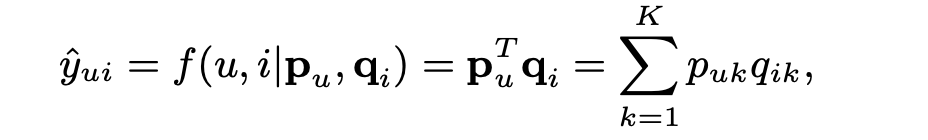
다음의 그림은 내적 곱 함수가 MF의 표현력을 제한함을 보여준다.
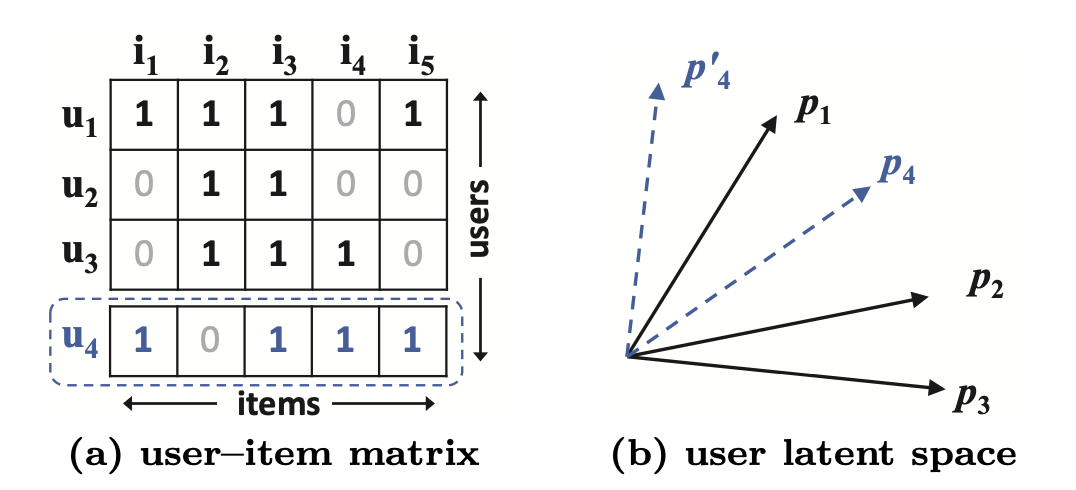
다음의 유사도는 Jaccard similarity를 따른다.
: 사용자 u가 상호 작용한 item 집합
user 1, 2, 3은 의 관계를 따르기에 잠재 공간에서 기하학적으로 표현하면 그림 (b)와 같다.
문제는 새로운 user 4를 고려할 때 발생한다.
의 관계를 가진다는 것은 user 4가 user 1, 3, 2의 순서로 유사하다는 것을 의미한다.
그러나 MF 모델이 user 4를 user 1에 가장 가까이 배치하는 경우 user 4가 user 3보다 user 2에 가까워지게 됨을 그림 (b)에서 확인할 수 있다.
위의 예시는 낮은 차원의 잠재 공간에서 복잡한 user-item 상호작용을 추정하기 위해 내적 곱을 사용함으로써 발생하는 MF의 한계점을 보여준다.
해당 문제를 해결하기 위한 방법은 2가지가 있다.
1. 큰 수의 잠재 공간의 차원 K를 갖는 것이지만, 이 경우 데이터에 과적합될 수 있다.
2. DNNs를 사용하여 상호작용 함수를 학습함으로써 문제를 해결한다.
해당 논문은 2번째 방법을 통해 MF의 한계점을 극복한다.
📖 Neural Collaborative Filtering
1. General Framework
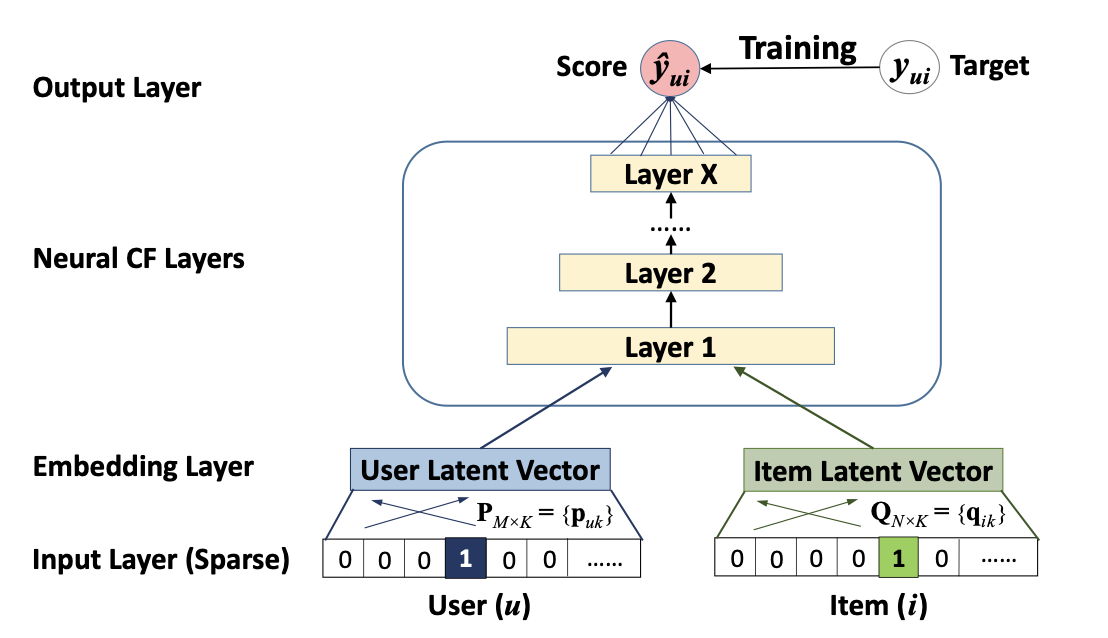
Input Layer
입력층은 각각 사용자 와 아이템 를 설명하는 두 개의 특성 벡터 와 로 구성된다.
특성 벡터는 사용자 및 항목의 다양한 모델링을 지원하도록 사용자 정의될 수 있으며, 연구에서는 협업 필터링 설정에 중점을 두고 있기 때문에 입력 특성으로 원-핫 인코딩을 이용해 사용자와 항목의 신원 정보만 사용하고 있다.
Embedding Layer
임베딩층 희소한 특성을 밀집된 벡터로 변환하는 fully connected layer이다.
이를 통해 얻어진 사용자 또는 아이템 임베딩은 잠재 요인 모델의 맥락에서 사용자 또는 아이템 잠재 벡터로 볼 수 있다.
Neural CF Layers
Neural CF layers의 각 층은 사용자와 항목 간 상호 작용의 특정 잠재 구조를 발견하는 데 맞춤 설정될 수 있다.
은닉층의 마지막 층 X의 차원이 모델의 성능을 결정하는데 이는 각 층이 모델링 과정에서 어떤 유형의 정보나 패턴을 추출하는지 조절할 수 있으며, 모델의 복잡성과 성능이 그에 따라 달라진다는 것을 의미한다.
Output Layer
출력층은 예측된 점수 이며, 훈련은 와 목표 값 간의 pointwise loss를 최소화하여 수행된다.
NCF 예측 모델
: 사용자 잠재 요인 행렬
: 아이템 잠재 요인 행렬
: 다층 신경망
: Neural Collaborative Filtering의 매핑 함수
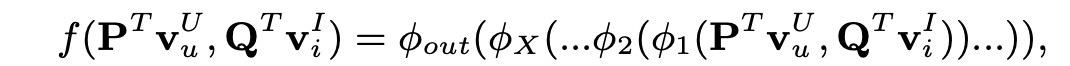
Learning NCF
: 관찰된 상호작용의 집합
: 미관찰된 상호작용의 집합
: 인스턴스 의 가중치를 나타내는 하이퍼파라미터
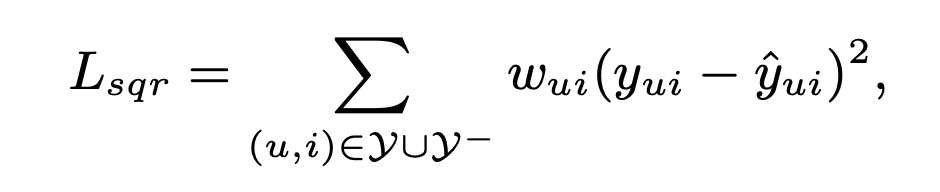
다음의 식은 모델 매개변수를 학습하기 위한 기존의 pointwise 방법이다.
하지만 암시적 데이터의 경우 대상값 은 와 가 상호 작용했는지 여부를 나타내는 이진화 된 1 또는 0이기 때문에 기존의 pointwise 방법이 알맞지 않다.
따라서 저자는 암시적 데이터의 이진 특성에 주목하여 NCF를 학습하기 위한 확률론적 접근 방식을 제시한다.
NCF에 확률적 설명을 부여하기 위해 를 [0,1]범위로 제한한다.
이는 출력 레이어의 매핑 함수 에 대한 활성화 함수로 확률 함수를 사용함으로써 쉽게 달성할 수 있으며, 가능도의 마이너스 로그를 취하는 방식으로 정의할 수 있다.
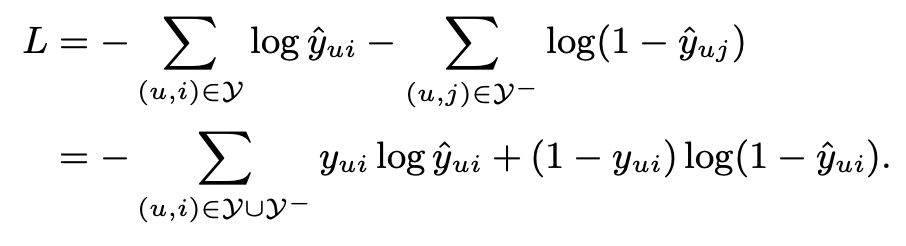
이것은 NCF 방법을 최적화하기 위해 최소화해야 하는 목적함수이며, 확률적 경사 하강법(SGD)를 통해 수행된다.
사실 해당 목적함수는 binary Cross entropy loss와 동일하다는 것을 알 수 있다.
2. Generalized Matrix Factorization (GMF)
논문은 MF가 NCF의 특수한 경우로 해석될 수 있음을 보인다.
: 사용자 잠재 벡터
: 아이템 잠재 벡터
: element-wise product of vectors
: activation function
: edge weights
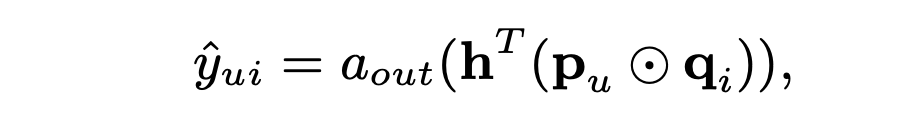
NCF의 첫 번째 층의 매핑 함수를 ⊙로 정의하고, 을 항등 함수로, 를 값이 모두 1인 균일한 벡터를 사용하면 MF 모델을 정확하게 재현할 수 있다.
해당 연구에서는 으로 sigmoid function 을 사용했으며,
위에서 정의한 로그 비용 함수와 데이터로부터 학습하는 를 사용한 NCF내에서의 MF의 일반화 버전을 사용한다.
3. Multi-Layer Perceptron (MLP)
기존의 multimodal deep learning 연구에서 적용한, 단순히 벡터를 연결하는 것은 user와 item의 잠재적 특징 사이의 상호작용을 고려하지 못하다는 한계점을 극복하기 위해 MLP를 사용함으로써 GMF보다 모델에 높은 수준의 유연성과 비선형성을 부여하여 와 사이의 상호작용을 학습할 수 있도록 한다.
: 가중치 행렬
: 편향 벡터
: 활성화 함수
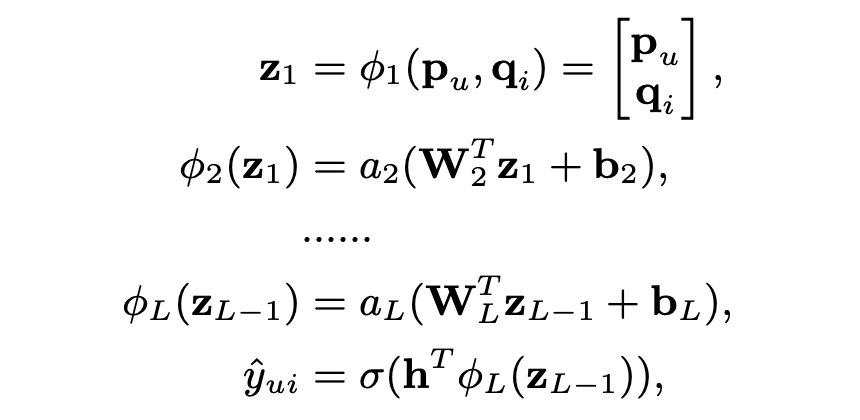
저자는 경험적인 결과를 통해 희소한 데이터에 적합하고 모델이 과적합하게 만들 가능성이 덜 한 활성화 함수 가 와 sigmoid보다 성능이 더 좋음을 이야기한다.
4. Fusion of GMF and MLP
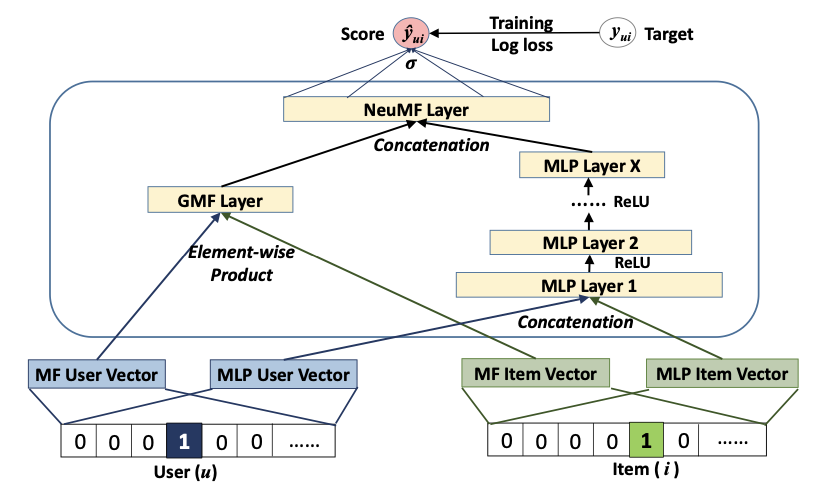
저자는 잠재 기능 상호작용을 모델링하기 위해 선형 커널을 적용한 GMF와 데이터로부터 상호작용 함수를 학습하기 위해 비선형 커널을 사용하는 MLP의 결합을 다음과 같이 진행한다.
저자는 다음의 모델을 "NeuMF"라 명명했다.
와 : GMF와 MLP에 대한 사용자 임베딩
와 : GMF와 MLP에 대한 아이템 임베딩
: 활성화 함수
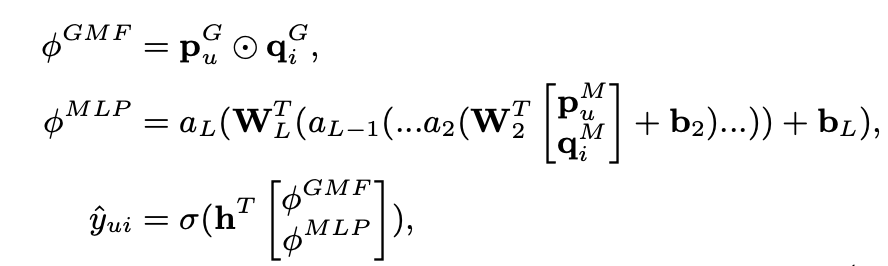
GMF와 MLP의 임베딩을 공유하는 것은 융합된 모델의 성능을 제한할 수 있기 때문에 융합된 모델의 유연성을 제공하고자 저자는 두 모델이 별도의 임베딩을 학습하게 하고, 그들의 마지막 은닉층을 연결하여 결합한다.
Pre-training
저자는 NeuMF가 GMF와 MLP의 앙상블이므로, 두 모델의 사전 학습된 모델을 사용하여 NeuMF를 초기화할 것을 제안한다.
이를 통해 유일한 수정 사항은 두 모델을 어떤 비율로 결합할지 결정하는 가중치 가 된다.
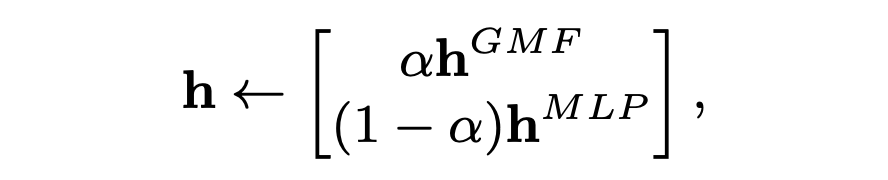
📖 Experiments
저자는 다음의 데이터 셋을 이용해 실험을 진행했다.

1. Performance Comparison
NDCG : 가장 이상적인 추천 조합 대비 현재 모델의 추천 리스트가 얼마나 좋은지를 나타내는 지표이다.
HR : 전체 사용자 수 대비 적중한 사용자 수를 의마한다.
BPR과 eALS는 MF 방법이다.
1. 예측 요인 수에 따른 모델별 추천 성능
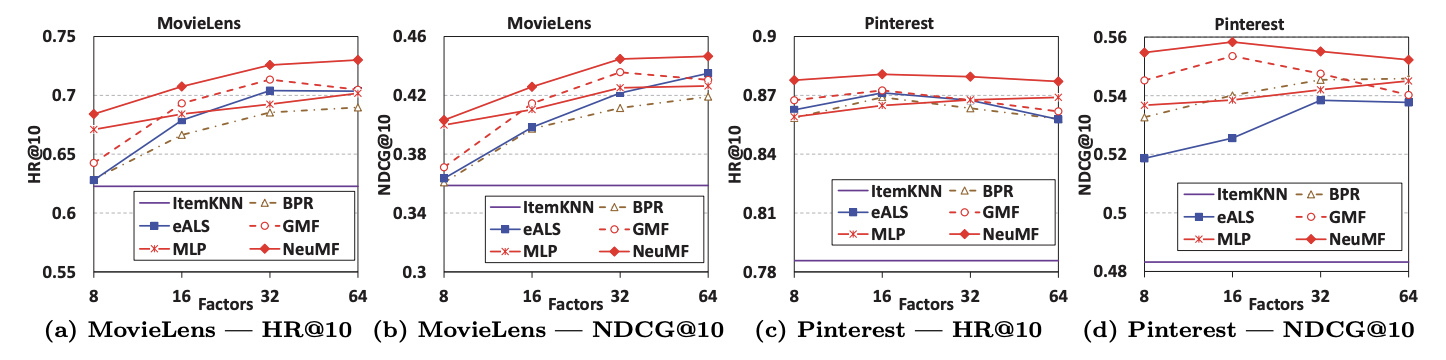
- NeuMF가 두 데이터셋 모두에서 최상의 성능을 달성했다.
- NCF 방법인 GMF와 MLP도 상당한 성능을 보이며, MLP는 GMF에 비해 약간의 성능이 떨어지지만 레이어를 더 추가함으로써 개선될 수 있다.
- GMF와 BPR은 동일한 MF 모델임에도 GMF가 BPR의 성능을 능가함으로써 추천 작업에서 classification aware log loss의 효과를 입증했다.
2. 랭킹 K의 범위 [1~10]에 따른 모델별 추천 성능
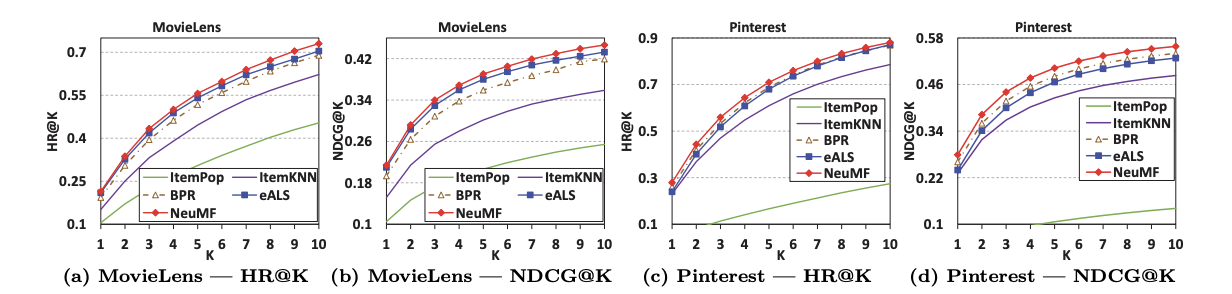
NeuMF는 다양한 K에서 다른 방법들에 비해 일관된 성능 향상을 보여주며, 모든 향상이 통계적으로 유의미하다는 것을 1-sample paired t-tests를 통해 입증했음을 말한다.
3. Pre-training 의 활용성
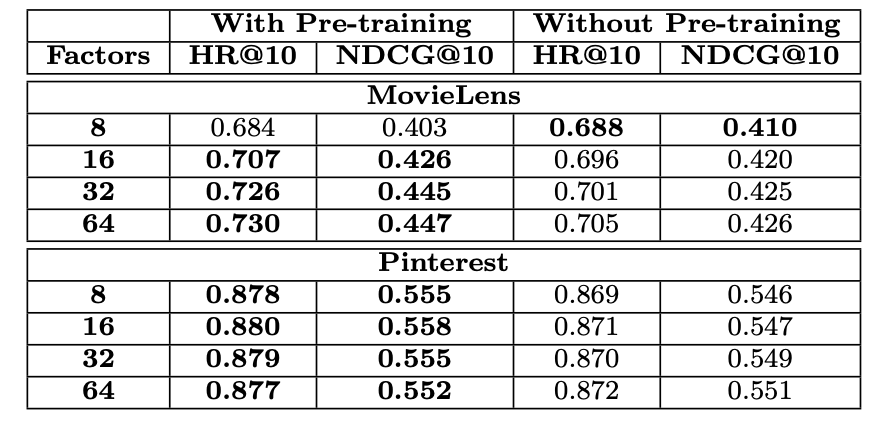
표를 통해 알 수 있듯 사전 학습된 NeuMF가 대부분의 경우에 더 나은 성능을 보인다.
다만 작은 예측 요인 8을 가진 MovieLens 데이터셋의 경우에만 사전 학습이 없는 NeuMF가 더 나은 성능을 보이는 것을 알 수 있다.
결과적으로 해당 실험은 NeuMF 초기화를 위한 사전 학습 방법의 유용성을 정당화한다고 말한다.
2. Log loss with Negative Sampling
1. iterations 수에 따른 모델 별 training loss
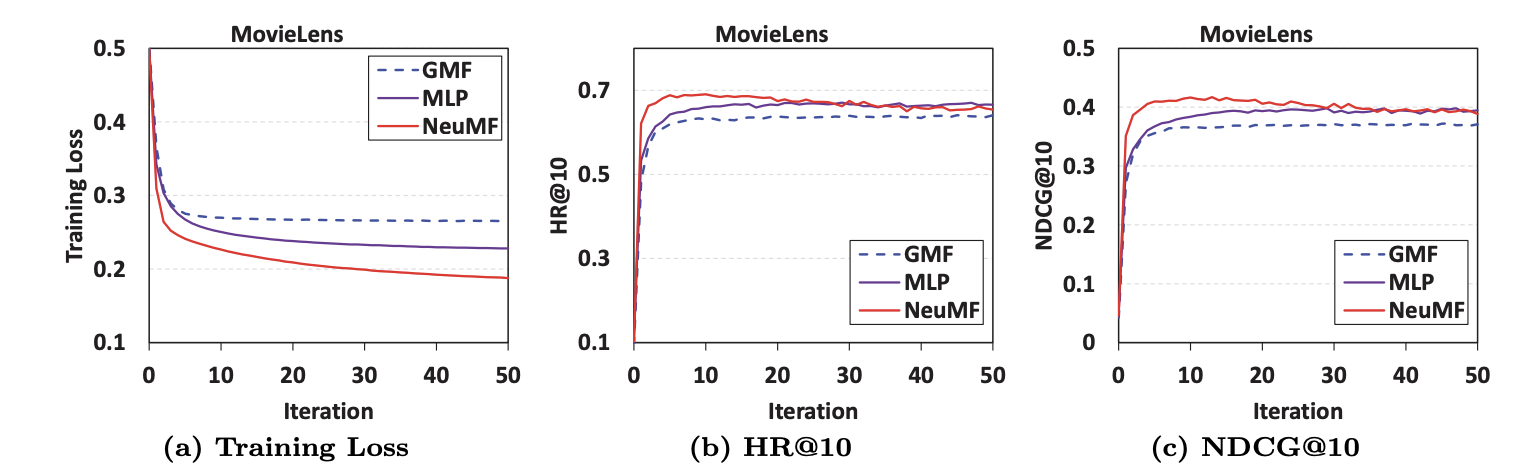
1. 더 많은 반복을 통해 NCF 모델의 training loss가 점차 감소하고 추천 성능이 향상되는 것을 볼 수 있으며, 가장 효과적인 업데이트는 10번의 반복임을 알 수 있다.
더 많은 반복은 모델을 과적합되게 만든다.
2. 세가지 NCF 방법 중 NeuMF가 training loss가 가장 낮으며, 그 다음이 MLP이고 GMF가 마지막이다.
추천의 성능도 다음의 순서를 따른다.
2. the nember of nagative sample per positive instance

pairwise-loss와 비교할 때 pointwise-loss의 장점 중 하나는 Negative instance의 유연한 샘플링 비율이다.
pairwise-loss는 긍정적 인스턴스와 하나의 샘플링된 부정적 인스턴스만 짝을 이룰 수 있지만 pointwise-loss의 샘플링 비율은 유연하게 제어할 수 있다.
따라서 부정 샘플링이 NCF에 미치는 영향을 확인하기 위해 위의 그림은 부정 샘플링 비율에 대한 NCF 방법의 성능을 보여준다.
그림을 통해 알 수 있듯이 긍정적 인스턴스 하나당 하나의 부정적 샘플만으로는 최적의 성능을 얻을 수 없으며, 더 많은 부정적 인스턴스를 샘플링하는 것이 유익한 것으로 볼 수 있다.
이는 poinwise-loss가 pairwise-loss에 비해 장점을 보여주는 것으로 보여진다.
두 데이터셋 모두에서 최적의 샘플링 비율은 약 3~6이다.
3. Is Deep Learning Helpful?
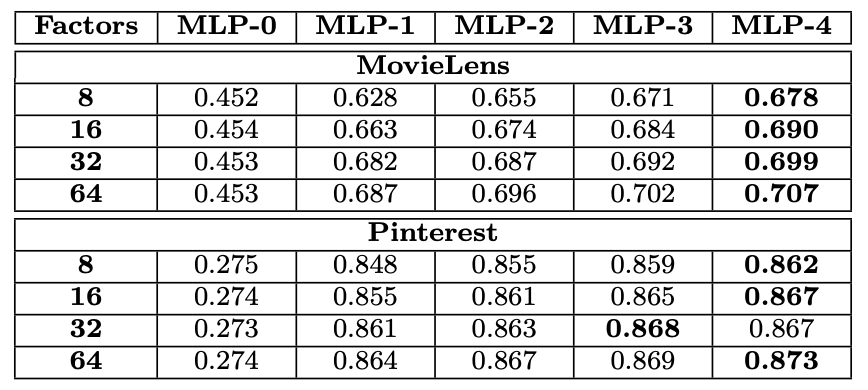
위 표는 다양한 은닉층의 수를 가진 MLP를 조사한 결과이다.
표를 통해 알 수 있듯 같은 용량을 가진 모델에서도 더 많은 레이어를 쌓는 것이 성능에 도움이 된다는 것을 확인할 수 있다.
📖 Conclusion
해당 논문을 읽는데 인상깊었던 부분은 마지막 Experiments였다.
자신들이 개선한 부분들이 모두 모델의 더 나은 성능을 발휘하는데 도움이 된다는 것을 입증하기 위해 다양한 실험을 진행했다는 것이 돋보였다.
아직 논문을 많이 읽어본 경험이 없어 다른 논문들 또한 이와 같이 꼼꼼하게 실험을 거쳐 자신들의 주장을 입증하는지 모르겠지만 해당 논문은 실험에 있어서 귀감이 되는 논문이라고 생각한다.
Reference
Neural Collaborative Filtering
NDCG, HR
[논문리뷰]Neural Collaborative filtering
