📌 Self-supervised Graph Learning for Recommendation
📖 ABSTRACT
-
기존의 PinSage 및 LightGCN과 같이 추천을 위한 그래프 합성 신경망 모델들은 큰 성공을 보였지만 몇 가지 한계점을 지닌다.
-
본 논문은 이를 해결하기 위해 LightGCN을 기반으로 기존 지도 학습에 보조적인 역할로 자기 지도 학습을 추가하여 노드 표현 학습을 강화한 SGL(Self-supervised Graph Learning)이라는 모델을 제안한다.
-
SGL은 자동으로 hard negatives를 발견할 수 있음을 보이며, 실험적으로 우수한 성능을 보인다.
📖 INTRODUCTION
기존 GCN 기반 추천 모델 한계점
앞서 언급한 기존 GCN 기반 추천 모델들의 한계점은 다음과 같다.
- Sparse Supervision Signal: 대부분의 모델은 지도 학습을 통해 추천 작업을 다루지만, 전체 상호 작용 공간에 비해 관찰된 상호 작용이 극히 희소하여 좋은 표현을 학습하기 어렵다.
- Skewed Data Distribution: 일반적으로 관찰된 상호 작용은 다음과 같이 멱법칙 분포를 보인다. 꼬리 부분의 낮은 차수 아이템은 감독 신호가 부족한 반면, 높은 차수 아이템은 이웃 집계에 더 자주 관여하여 표현 학습에 큰 영향을 미친다. 이에 따라 GCN은 쉽게 높은 차수 아이템으로 편향되어 버리며, 낮은 차수 아이템의 관여는 낮춘다.
- Noises in Interactions: 사용자가 제공하는 대부분의 피드백은 명시적인 것이 아닌 암시적인 것이며, 이는 잘못된 클릭과 같이 노이즈가 포함된 경우가 일반적이다. GCN의 이웃 집계 체계는 상호 작용이 표현 학습에 미치는 영향을 증폭시켜 학습하기 때문에 상호 작용 노이즈에 민감하다.
SGL 한계점 해결
SGL은 그래프 구조에 적용 가능한 SSL 그리고 GCN 기반 모델의 한계점을 해결하기 위해 두 핵심 요소로 이루어져있다.
- data augmentation: 각 노드에 대해 여러 뷰를 생성한다.
- contrastive learning: 동일한 노드에서 파생된 다른 뷰 간의 일치를 최대화하여 다른 노드와 비교한다.
다양한 뷰를 생성하는 operators로는 node dropout, edge dropout, random walk 방식이 있다.
SGL은 앞서 말했듯이 기존의 GCN 기반 추천 모델을 보충하는 형식이며, 다음의 측면에서 한계점들을 해결한다.
- node self-discrimination: 자가 지도 학습을 채택하여 고전적인 감독 학습에서 나오는 관찰된 상호 작용만큼의 보조 감독 신호를 제공한다.
- augmentation operators: edge drop을 통해 높은 차수 노드의 영향을 의도적으로 감소시킴으로써 차수 편향을 완화하는 데 도움이 된다.
- multiple view: 다양한 지역 구조와 이웃에 대한 노드의 여러 뷰는 모델이 상호 작용 노이즈에 대해 강력해지도록 한다.
📖 METHODOLOGY
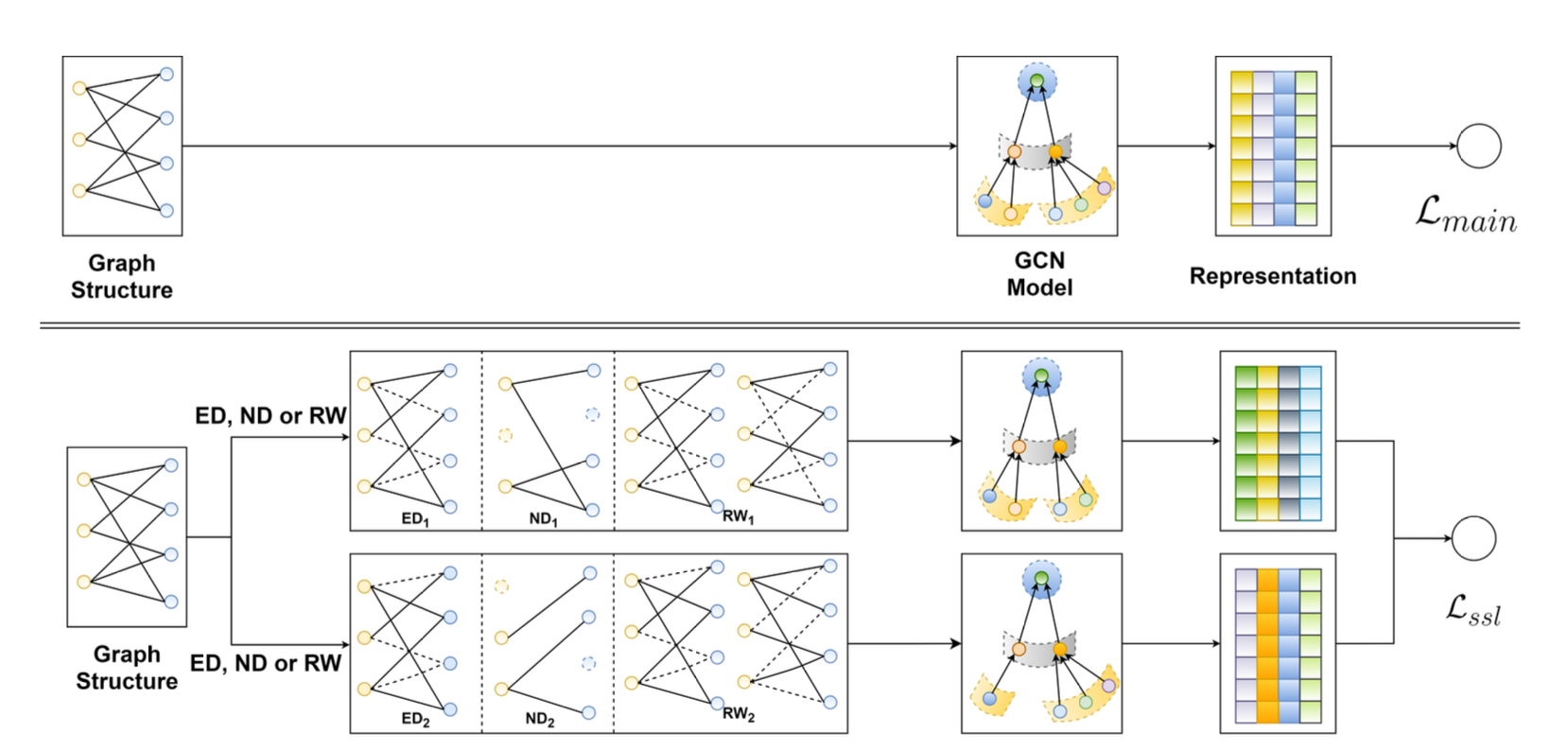
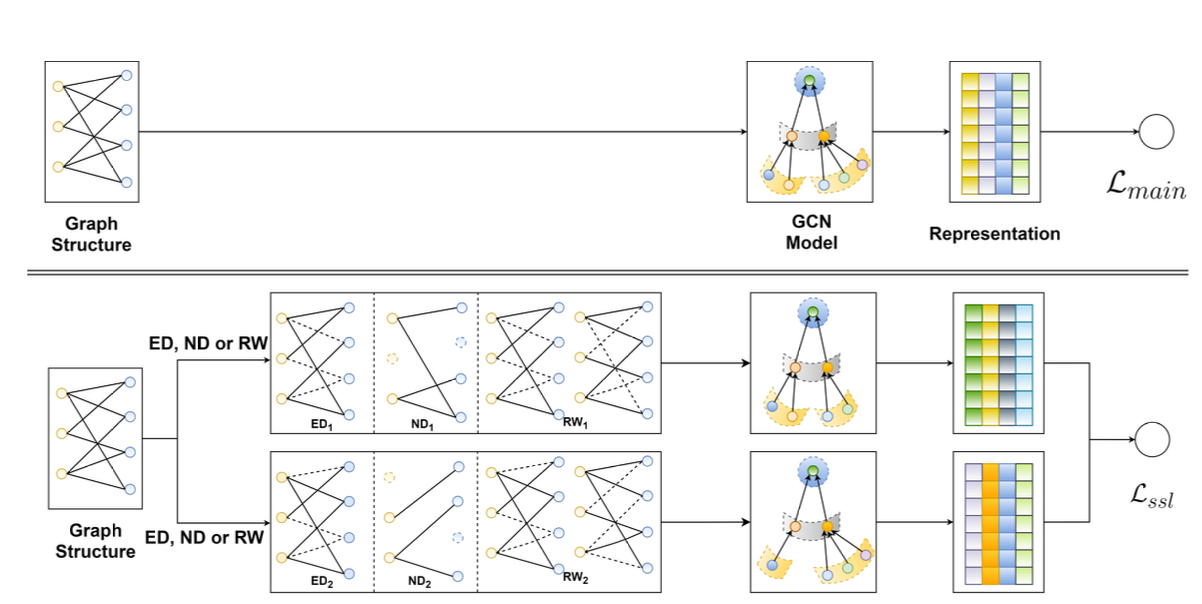
SGL은 지도 학습 작업에 자가 지도 학습을 결합하여 노드의 표현을 강화하는 방법이다.
위 그림은 SGL의 작동 흐름을 보인다.
Data Augmentation on Graph Structure
CV 및 NLP 작업에서 사용되는 데이터 증강을 직접 그래프 기반 추천에 적용하는 것은 다음의 이유로 인해 불가능하다.
- 이산적인 특성: 사용자와 항목의 특성은 원-핫 ID 및 기타 범주형 변수와 같이 이산적이기 때문에 이미지에 대한 무작위 자르기, 회전 또는 흐림과 같은 증강 연산자는 적용이 불가능하다.
- 연결성과 의존성: CV 및 NLP 작업은 각 데이터 인스턴스를 고립된 것으로 취급하는 반면, 상호 작용 그래프에서의 사용자 및 항목은 본질적으로 서로 연결되어 있고 의존적이다.
그렇기 때문에 그래프 기반 추천을 위해 특별히 설계된 새로운 증강 연산자로 앞서 언급한 node drop, edge drop, random walk가 사용된다.
수식적으로는 다음과 같이 표현한다.
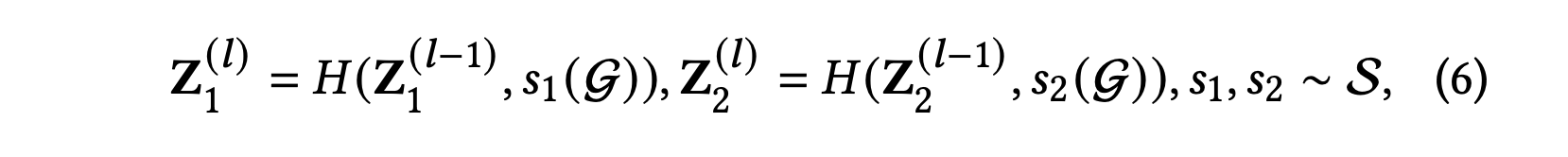
두 증강 연산자 과 는 그래프 에 독립적으로 적용되어 두 상관된 뷰 과 를 구성한다.
Node Dropout (ND)
확률 𝜌로 각 노드는 그래프에서 삭제되며, 해당 노드와 연결된 에지도 함께 제거된다.
과는 다음과 같이 표현한다.
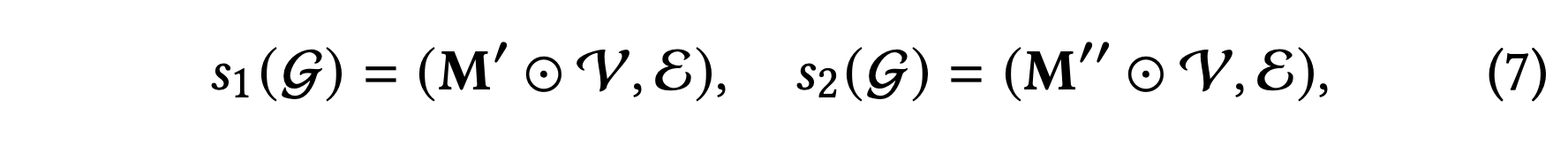
는 노드 집합 V에 적용되어 두 하위 그래프를 생성하는 마스킹 벡터이다.
이러한 증강을 통해 서로 다르게 증강된 뷰에서 영향력 있는 노드를 식별하고 표현 학습을 구조적인 변화에 덜 민감하게 만들고자 한다.
Edge Dropout (ED)
에지 드롭 아웃의 비율은 𝜌이며, 이로 인해 이웃 내의 부분적인 연결만이 노드 표현에 기여한다.
과는 다음과 같이 표현한다.
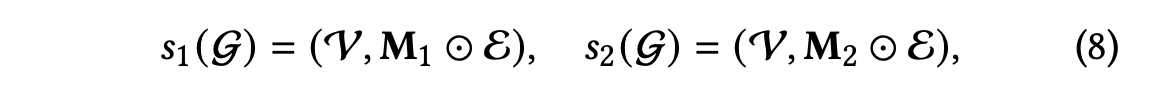
는 에지 집합 에 대한 두 가지 마스킹 벡터이다.
증강된 두 하위 그래프를 통해 노드의 지역 구조의 유용한 패턴을 포착하고, 노이즈가 있는 상호 작용에 대한 표현을 더 견고하게 만들고자 한다.
Random Walk (RW)
각 레이어에서 에지 드롭 아웃을 선택한다고 가정하면 마스킹 벡터를 레이어에 민감하게 만들어 랜덤 워크를 정의할 수 있다.
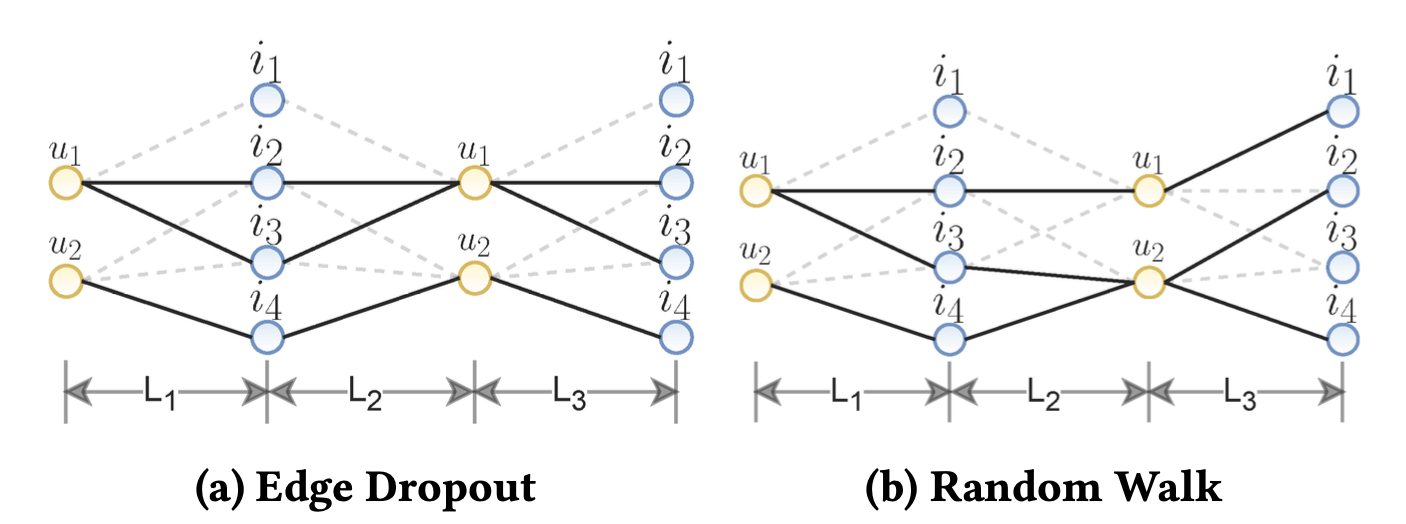
랜덤 워크의 경우 에지 드롭아웃과 달리 레이어 간에 그래프 구조가 계속 변경된다.
예를 들어 에지 드롭아웃의 경우 그래프 구조에서 사용자 는 아이템 과의 에지가 제거되어 세 번째 레이어에서도 해당 관계는 연결되어 있지 않다.
반면, 랜덤 워크 방식의 경우 세 번째 레이어에서 다시 사용자 과 아이템 이 연결되어 있는 것을 볼 수 있다.
과는 다음과 같이 표현한다.
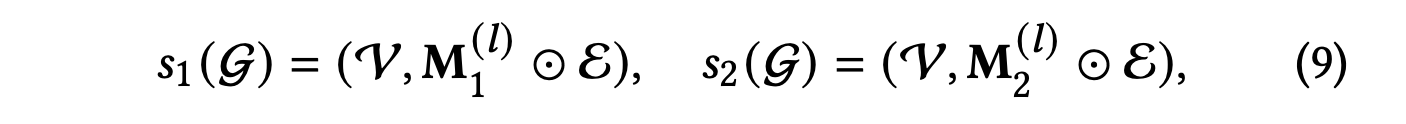
는 레이어 에서 에지 집합 에 대한 두 가지 마스킹 벡터이다.
Contrastive Learning
SGL은 CV에 Contrastive learning을 적용한 모델인 SimCLR을 따르며 대조 손실로 infoNCE를 채택하여 양성 쌍 간의 일치를 극대화하고 음성 쌍과의 일치는 최소화한다.
여기서 양성 쌍({})이란 동일한 노드에서 증강된 뷰를 의미하고,
음성 쌍({})이란 다른 노드에서 증간된 뷰를 의미한다.
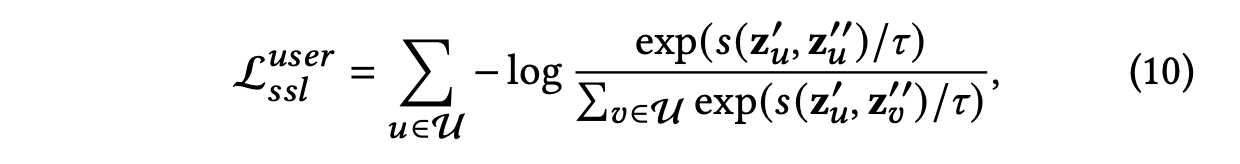
는 두 벡터 간의 유사성을 측정하는 함수로, 코사인 유사성 함수로 설정된다.
𝜏는 softmax에서의 하이퍼파라미터이다.
[참고] softmax의 하이어파라미터 𝜏
𝜏가 높을수록(양수이고 클수록) 확률 분포는 더 균일해지며, 모든 클래스에 대해 비슷한 확률을 가지게 된다.
𝜏가 작을수록(0에 가까울수록) 확률 분포는 뾰족해져 하나의 클래스가 높은 확률을 가지게 된다.
위 수식과 유사하게 아이템 측면의 대조 손실 도 얻을 수 있으며,
이 두 손실을 결합하여 자기 지도 학습 작업의 목적 함수인 을 얻는다.
Multi-task Training
SGL은 자기 지도 학습 작업을 활용하여 기존 추천 작업을 동시에 최적화하는 다중 작업 훈련을 채택한다.
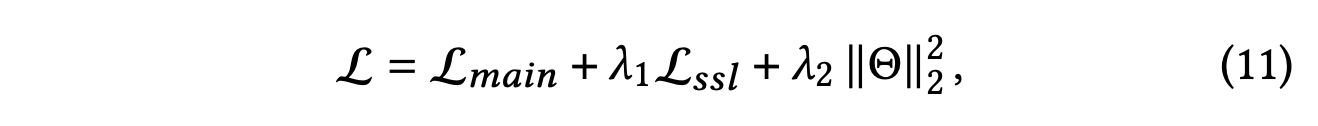
에는 추가적인 파라미터가 없기 때문에 는 에 해당하는 모델 파라미터의 집합을 나타낸다.
과 는 각각 SSL과 $L_24 정규화의 강도를 제어하는 하이퍼파라미터이다.
Theoretical Analyses of SGL
본 섹션에서는 자기 지도 손실을 조사하여 SSL 작업이 추천 모델에 어떤 이득을 제공하는지 조사한다.
결과부터 말하면 SSL 작업은 hard negative을 적절하게 선택하여 크고 의미 있는 경사 최적화에 기여하도록 노드 표현 학습을 안내하는 능력을 가지고 있다.
노드 에 대한 자기 지도 손실의 기울기는 다음과 같이 정의하며, 자기 지도 손실은 앞서 소개한 식 (10)에서 설명되어 있다.

와 는 각각 양성 노드 와 음성 노드 집합 {}가 의 기울기에 대한 기여를 나타낸다.
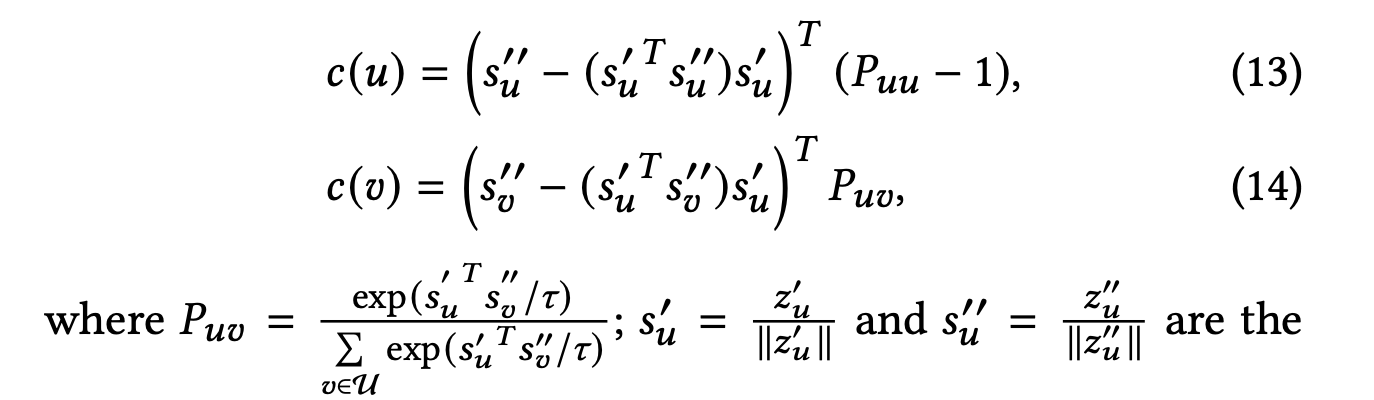
이 중 음성 노드 에 중점을 두며, 위 식 (14)는 다음과 같은 항에 비례하는 노름을 갖는다.
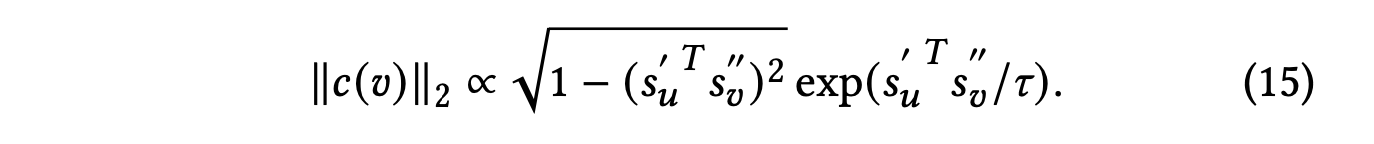
와 가 모두 단위 벡터이므로, 식 (15)를 간소화하기 위해 다음과 같이 변수
= 를 도입한다.

여기서 는 양성 노드 와 음성 노드 간의 표현 유사성을 직접 반영한다.
유사성 에 따라 음성 노드를 두 그룹으로 나눌 수 있다.
- hard negative nodes: 이들의 표현이 양성 노드 와 유사하기 때문에 잠재적 공간에서 를 와 구별하기 어려워진다.
- easy negative nodes: 이들의 표현이 양성 노드 와 유사하지 않기 때문에 쉽게 구별될 수 있다.
다음 그림은 위의 두 그룹의 기여를 조사하기 위해 𝜏를 1과 0.1로 설정하여 노드 유사성 의 변화에 따른 의 곡선을 나타낸다.
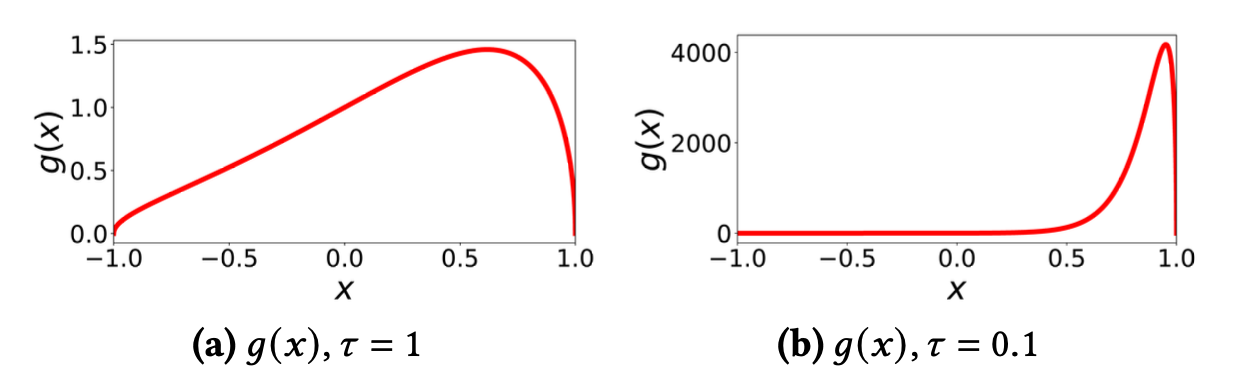
여기서 는 식의 정의에 따라 음성 노드들의 집합 {}가 사용자 노드 의 표현에 기여하는 정도를 노름으로 정규화 한 값이라 볼 수 있을 것 같다.
- 그림 (a) 𝜏가 1로 설정된 경우: 의 값은 범위 내에 속하고, 에 대한 반응의 변화가 조금 일어난 다는 것을 보인다.
이는 hard negative samples이든 easy negative samples이든 경사에 유사하게 기여한다는 것을 나타내며, 앞서 말했듯이 𝜏가 클수록 균일한 확률분포를 띄기에 이러한 특성이 나타나는 것으로 보여진다. - 그림 (b) 𝜏가 0.1로 설정된 경우: hard negative samples의 값이 4,000에 이를 수 있지만, easy negative samples의 g(x)는 거의 없다. 이는 hard negative samples이 최적화를 안내하기 위해 훨씬 더 큰 경사를 제공하며, 따라서 노드 표현을 더욱 구별력 있게 만들고 훈련 프로세스를 가속화한다는 것을 나타낸다.
나아가 저자는 𝜏가 의 최대값에 미치는 영향을 조사했다.
의 도함수를 0에 가깝게 만들어 그에 해당하는 값을 얻은 후 최대값인 의 로그를 다음과 같이 나타낸다.
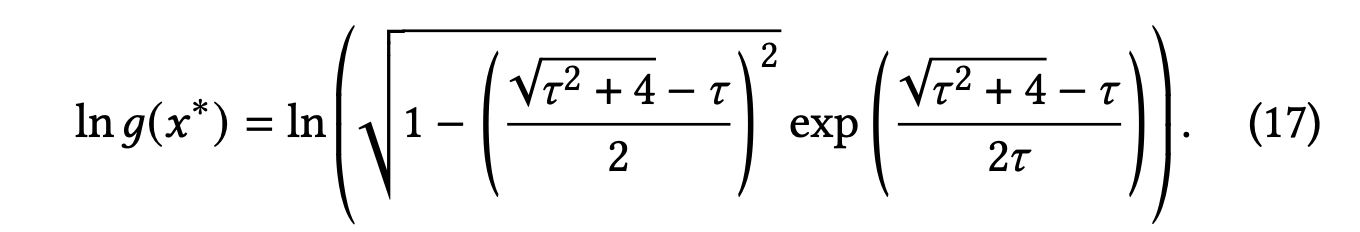
그림 (c)와 (d)에서 각각 와 ln의 곡선을 제시한다.
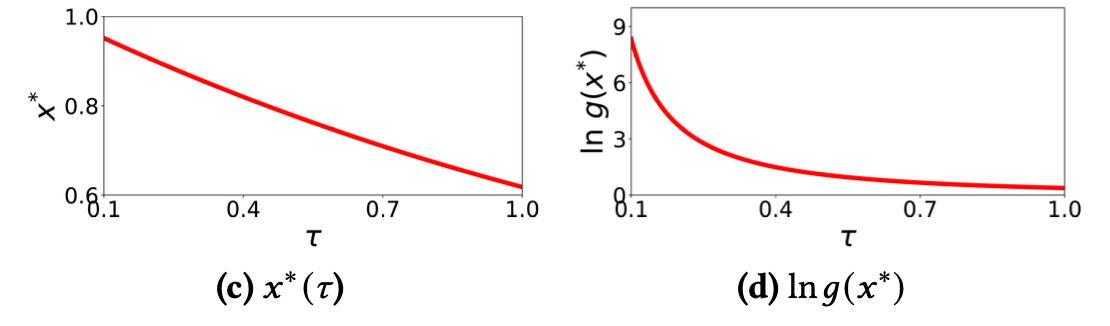
𝜏가 감소함에 따라, 가장 영향력 있는 negative nodes들은 양성 노드와 더 유사해지게 되며, 그에 따라 이들의 기여는 기하급수적으로 증폭되는 것을 보인다.
따라서 적절한 𝜏 설정은 SGL이 자동으로 어려운 부정적인 샘플을 찾아낼 수 있도록 한다.
📖 EXPERIMENTS
Performance Comparison
1. Comparison with LightGCN
다음 표는 SGL과 LightGCN 간의 결과 비교를 보인다.
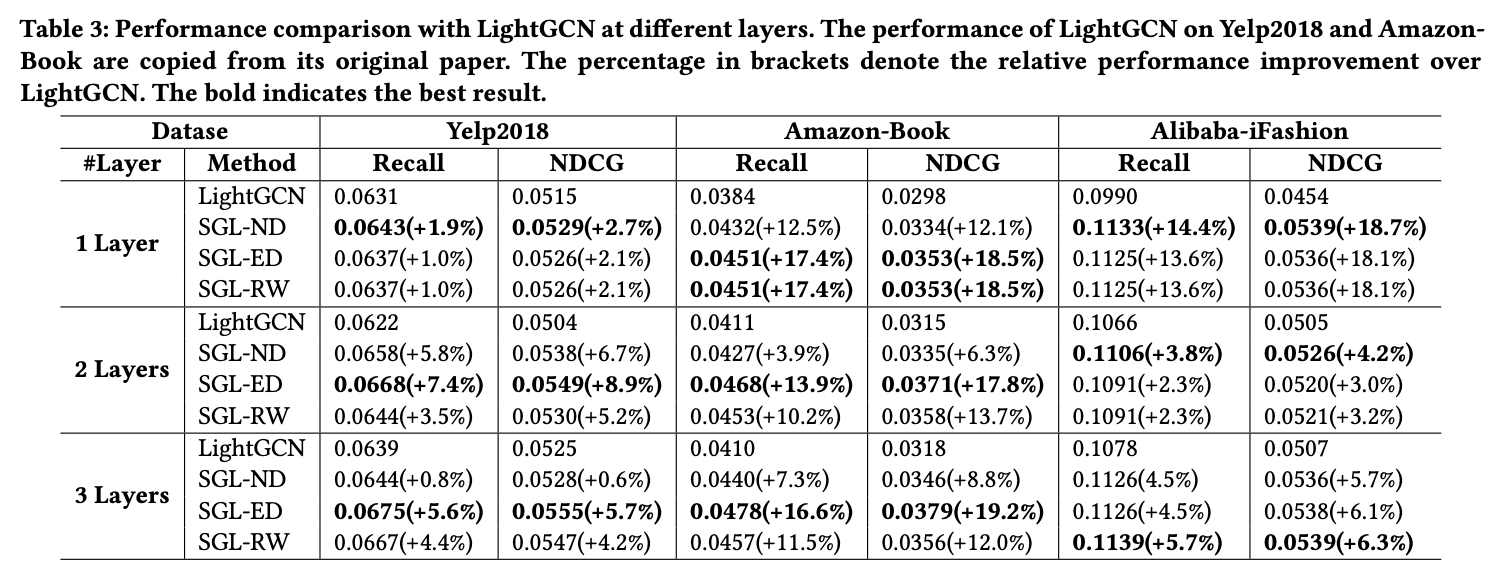
대부분의 경우 세 가지 SGL 구현은 LightGCN을 큰 폭으로 능가하며, 자기 지도 학습을 추천 작업에 보완하는 우수성을 나타내며 몇가지 통찰을 보인다.
- SGL 모델 중 SGL-ED는 18가지 경우 중 10가지에서 가장 우수한 성능을 보이며, SGL-RW 또한 모든 데이터셋에서 SGL-ND보다 더 나은 성능을 보인다.
- SGL-ED와 SGL-RW의 결과는 레이어가 깊어짐에 따라 증가하는 반면, SGL-ND는 다른 패턴을 보이는 것을 보아 비교적 불안정한 것으로 보인다.
- 모델 깊이를 1에서 3으로 증가시키면 SGL의 성능이 향상되는 것으로 보아 SSL을 활용하면 GCN 기반의 추천 모델의 일반화 능력을 강화할 수 있음을 보인다.
2. Comparison with the State-of-the-Arts
다음 표는 SOTA 모델과의 성능 비교를 보인다.
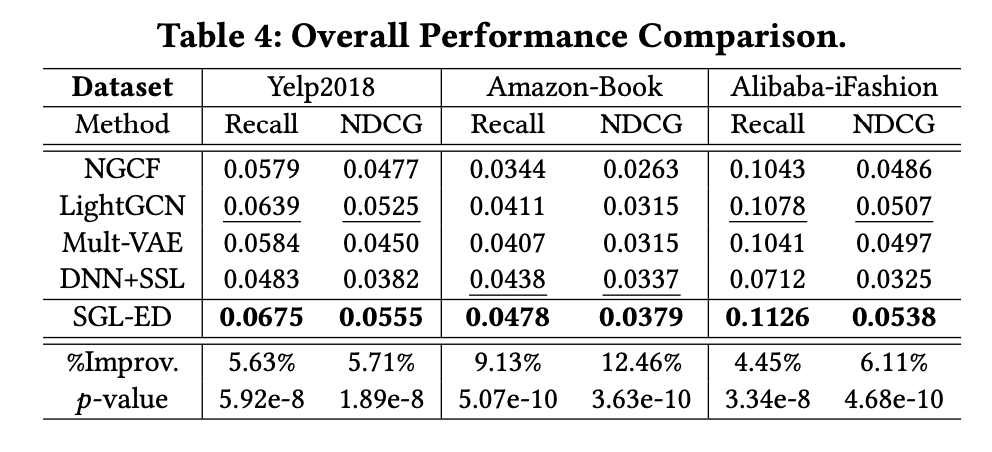
SGL-ED는 일관되게 모든 기준을 넘어서 우수한 성능을 보이며, 이는 자기 지도 학습을 통합하는 것의 타당성과 효과를 확인한다.
Benefits of SGL
Long-tail Recommendation
SGL이 롱테일 문제 해결에 유용한지 확인하기 위해 인기도를 기반으로 항목을 열 개의 그룹으로 나누고 각 그룹의 전체 상호 작용 수를 동일하게 유지했다.
이에 따라 인기가 낮은 그룹에는 더 많은 아이템을 포함시켜 상호 작용을 증가시킨 것으로 보인다.
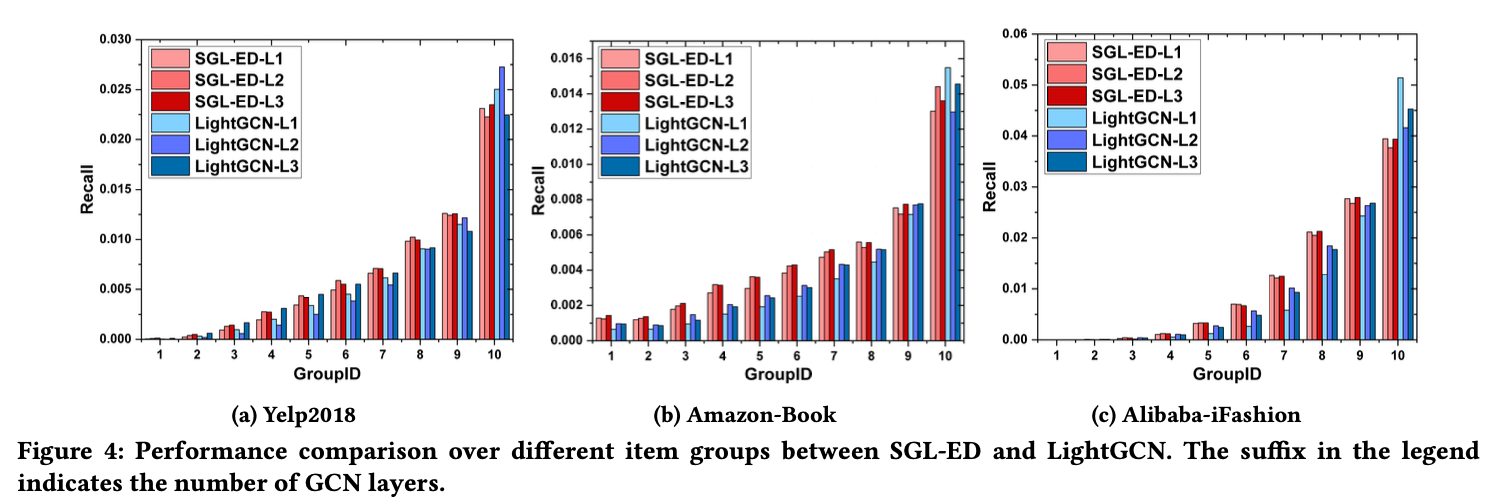
LightGCN은 고차수 항목을 추천하는 경향이 있으며 롱테일 항목은 덜 노출시킨다.
항목 공간의 0.83%, 0.83% 및 0.22%만 포함하고 있는 10 그룹은 각각 세 데이터셋에서 전체 Recall 점수의 39.72%, 39.92% 및 51.92%를 기여한다.
반면, SGL은 10 그룹의 기여는 각각 세 데이터셋에서 36.27%, 29.15%, 35.07%로 감소한 것으로 보인다.
Training Efficiency
다음 그림은 각 데이터 셋에서 SGL-ED 및 LightGCN의 훈련 곡선을 보인다.
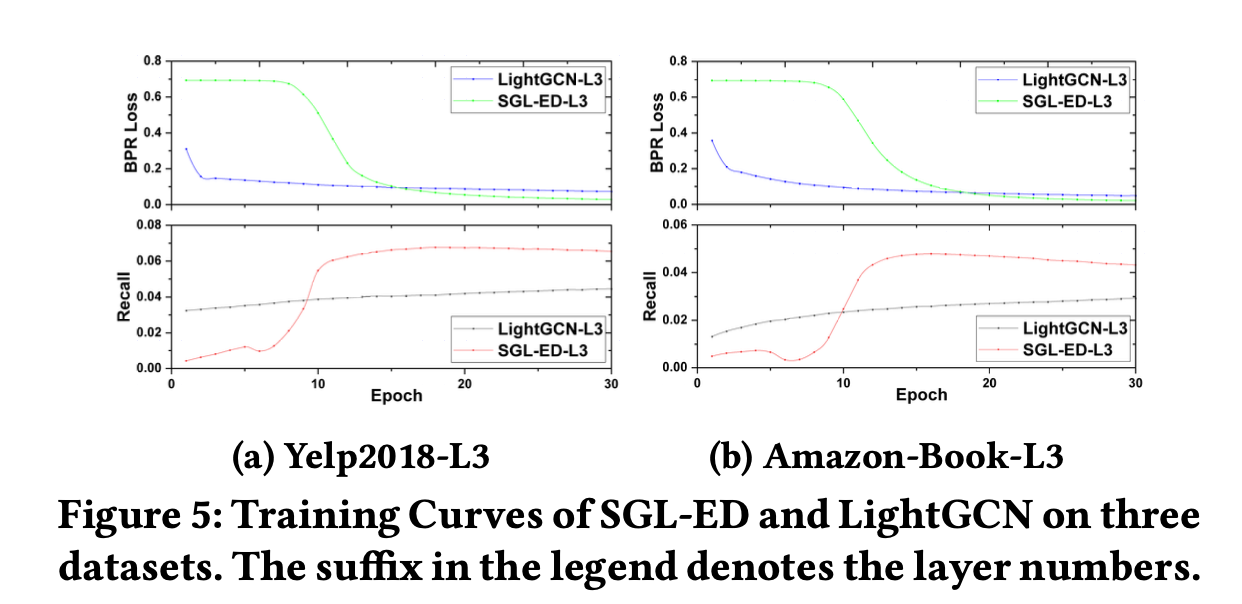
SGL은 두 데이터셋 모두에서 LightGCN에 비해 수렴하는 속도가 훨씬 빠름을 보인다.
SGL은 각각 18번째 및 16번째 에포크에서 최상의 성능을 달성하는 반면, LightGCN은 각각 720번과 700번의 에포크가 걸린다.
Robustness to Noisy Interactions
다음 그림은 적정 비율의 적대적 예제를 추가하여 훈련 셋을 오염시킨 학습의 결과이다.
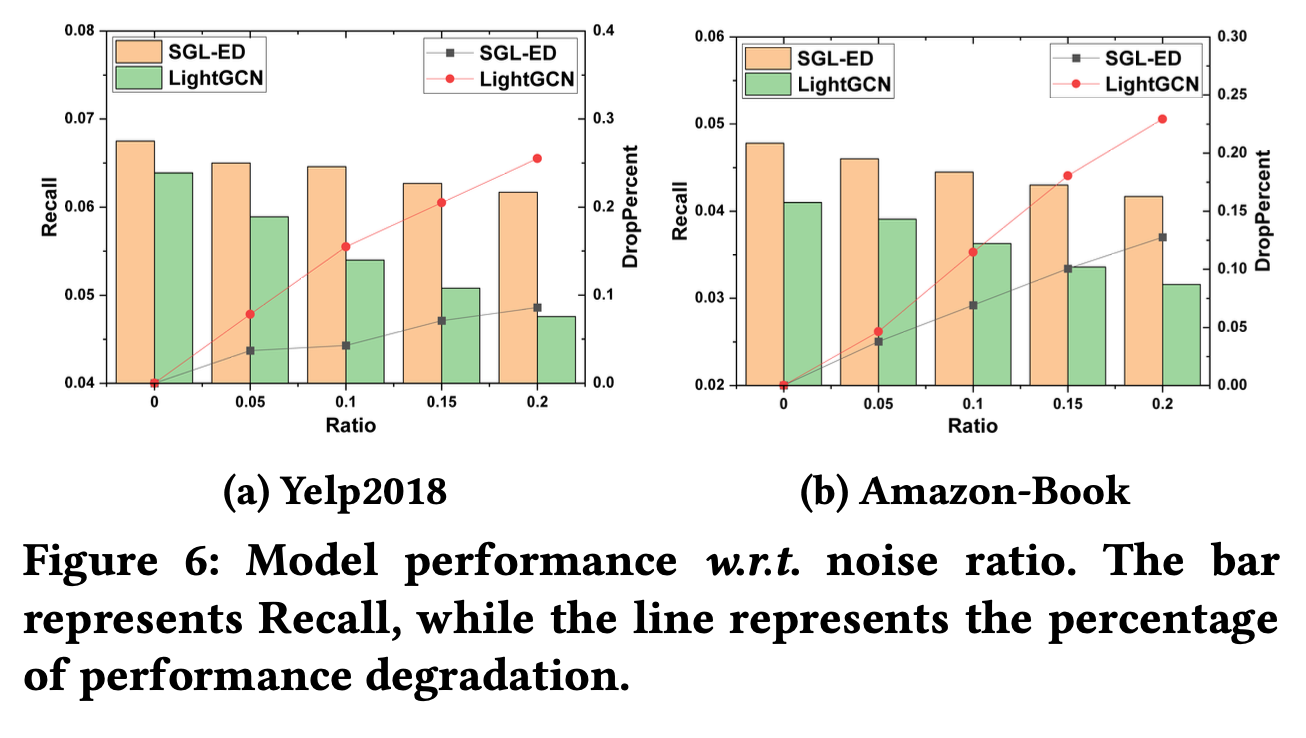
잡음 데이터를 추가하면 SGL과 LightGCN 모두의 성능이 감소한다.
하지만 SGL의 성능 저하는 LightGCN보다 낮음을 보인다.
Study of SGL
Effect of Temperature 𝜏
다음 그림은 𝜏에 대한 모델 성능 곡선을 보여준다.
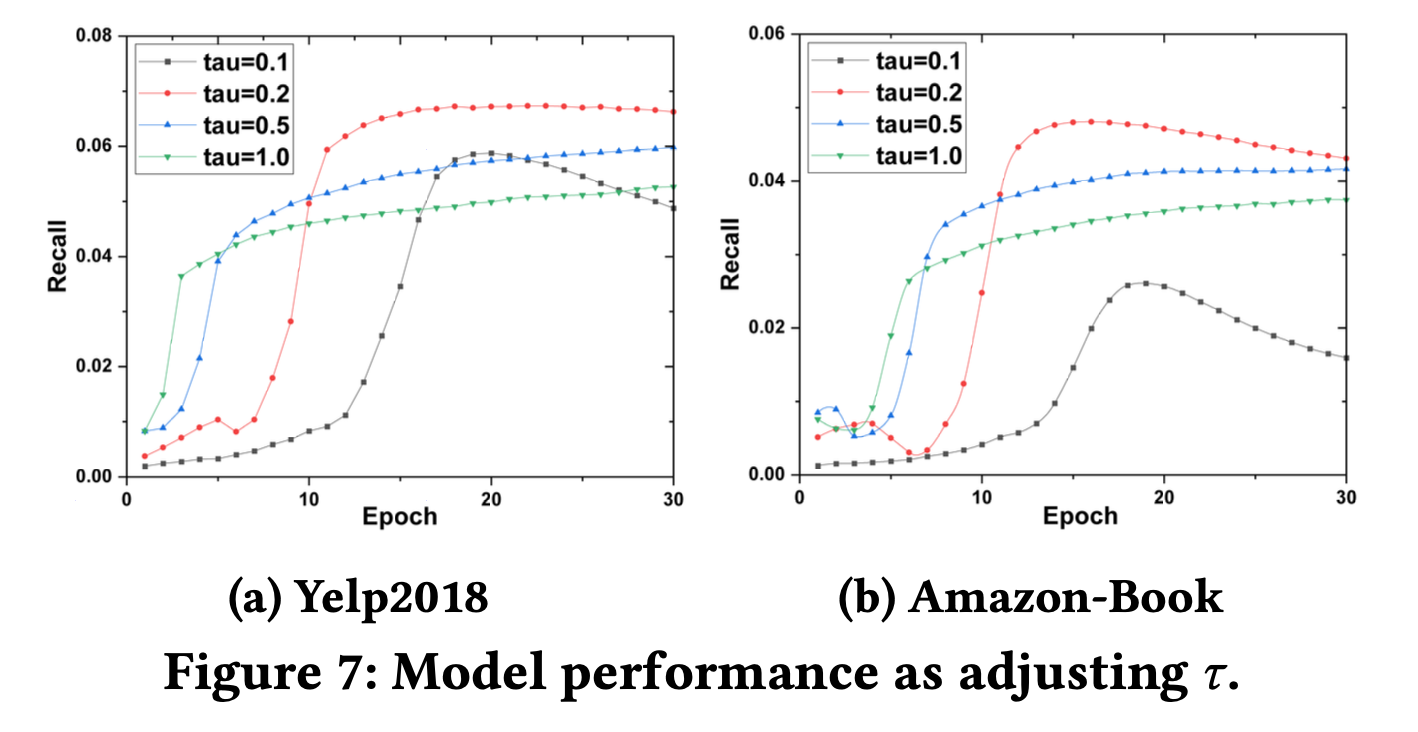
- 𝜏의 값을 너무 크게 하면 성능이 나빠지고 수렴하는 데 더 많은 훈련 에포크가 필요하다.
- 𝜏의 값을 너무 작게 하면 모델 성능이 나빠지고 몇 가지 부정적인 샘플의 기울기가 최적화를 지배하여 SSL 목적에서 여러 부정적인 샘플을 추가하는 우세성을 잃게 된다.
따라서 𝜏을 신중하게 조정하는 것이 좋다.
Effect of Pre-training
다음 표는 자기 지도 학습 작업을 사전 훈련하여 모델 매개변수를 얻고 이를 사용하여 LightGCN을 초기화한 다음, 주 작업을 최적화하여 모델을 세밀 조정한 SGL-pre의 결과를 보인다.
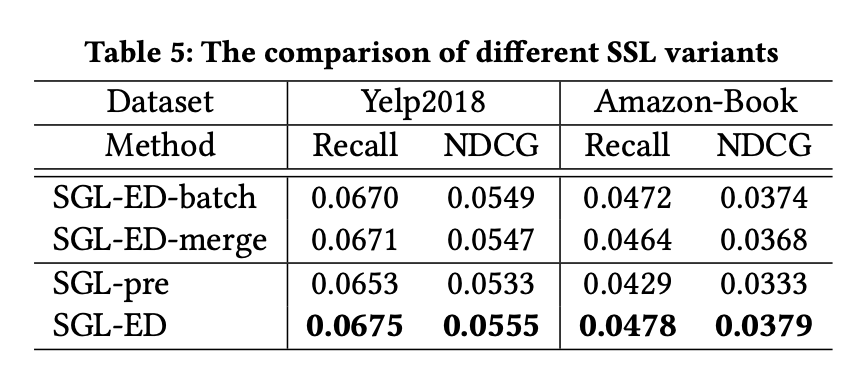
SGL-pre는 모든 데이터셋에서 SGL-ED보다 성능이 떨어지지만, LightGCN의 결과보다 우수한 결과를 보인다.
📖 CONCLUSION
본 논문은 SSL을 추천 모델에 도입함으로써 성능 향상을 달성할 수 있음을 입증했다.
대조 손실로 infoNCE를 도입하는것에서 그치지 않고 softmax의 하이퍼파라미터 𝜏를 조절함으로써 노드 표현 학습의 성능을 높일 수 있음을 실험적으로 보인 것이 인상깊었다.
Reference
Self-supervised Graph Learning for Recommendation
SimCLR v1 & v2 리뷰
