[논문 리뷰] Bootstrapping User and Item Representations for One-Class Collaborative Filtering
Paper Review
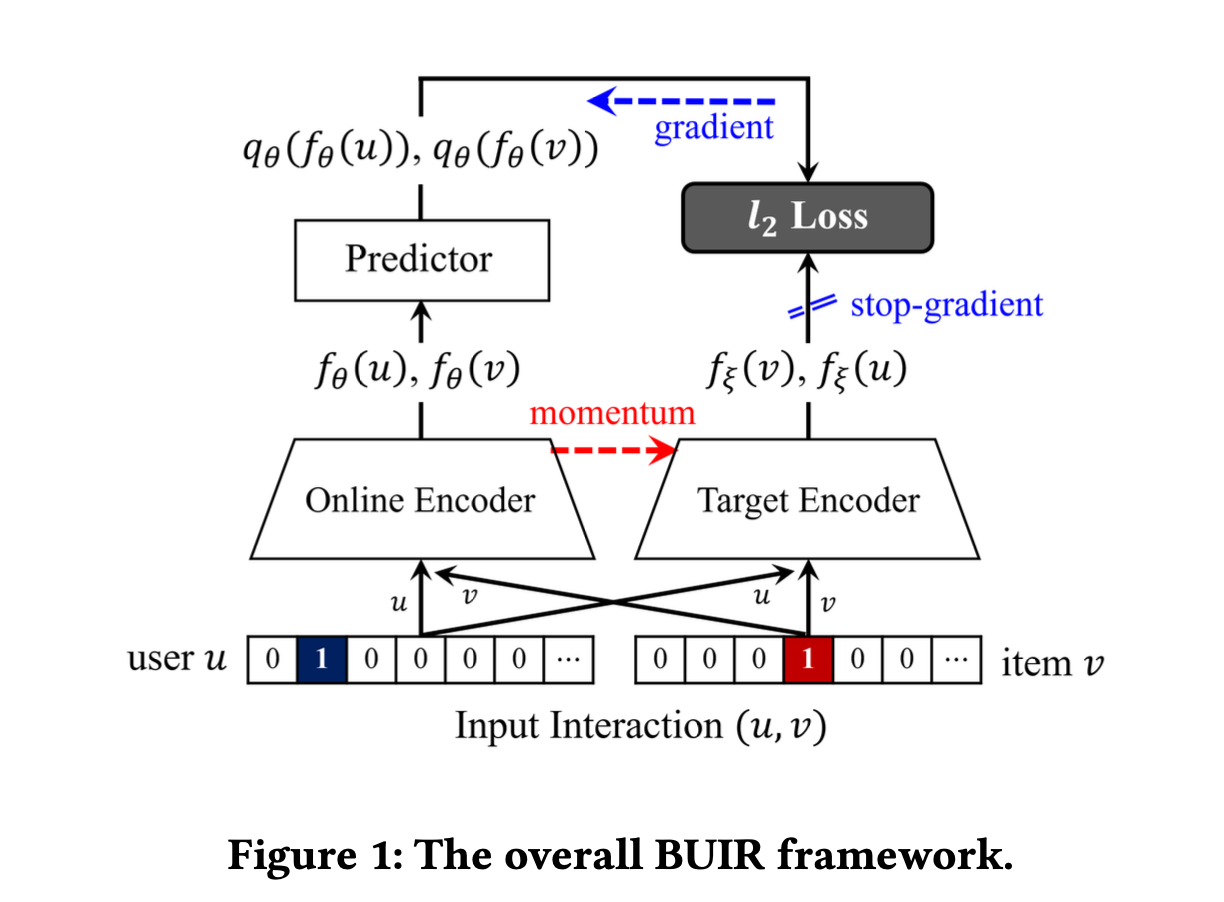
📌 Bootstrapping User and Item Representations for One-Class Collaborative Filtering
📖 ABSTRACT
-
본 논문은 부정적 상호 작용 샘플링이 필요하지 않은 BUIR이라는 새로운 OCCF 프레임워크를 제안한다.
-
BUIR는 양적으로 관련된 사용자와 아이템의 표현을 서로 유사하게 만들기 위해 서로로부터 학습하는 두 가지 다른 인코더 네트워크를 사용한다.
-
BUIR는 OCCF의 데이터 희소성 문제를 완화하기 위해 인코더 입력에 확률적 데이터 증강을 적용한다.
📖 INTRODUCTION
기존 OCCF 모델 한계점
One-class collaborative filtering(OCCF)의 목표는 아래 그림과 같이 일부 관측된(양적으로 레이블이 지정된) 상호 작용만을 사용하여 관측되지 않은 상호작용 중 가장 가능성이 있는 양적 사용자-아이템 상호 작용을 식별하는 것이다.
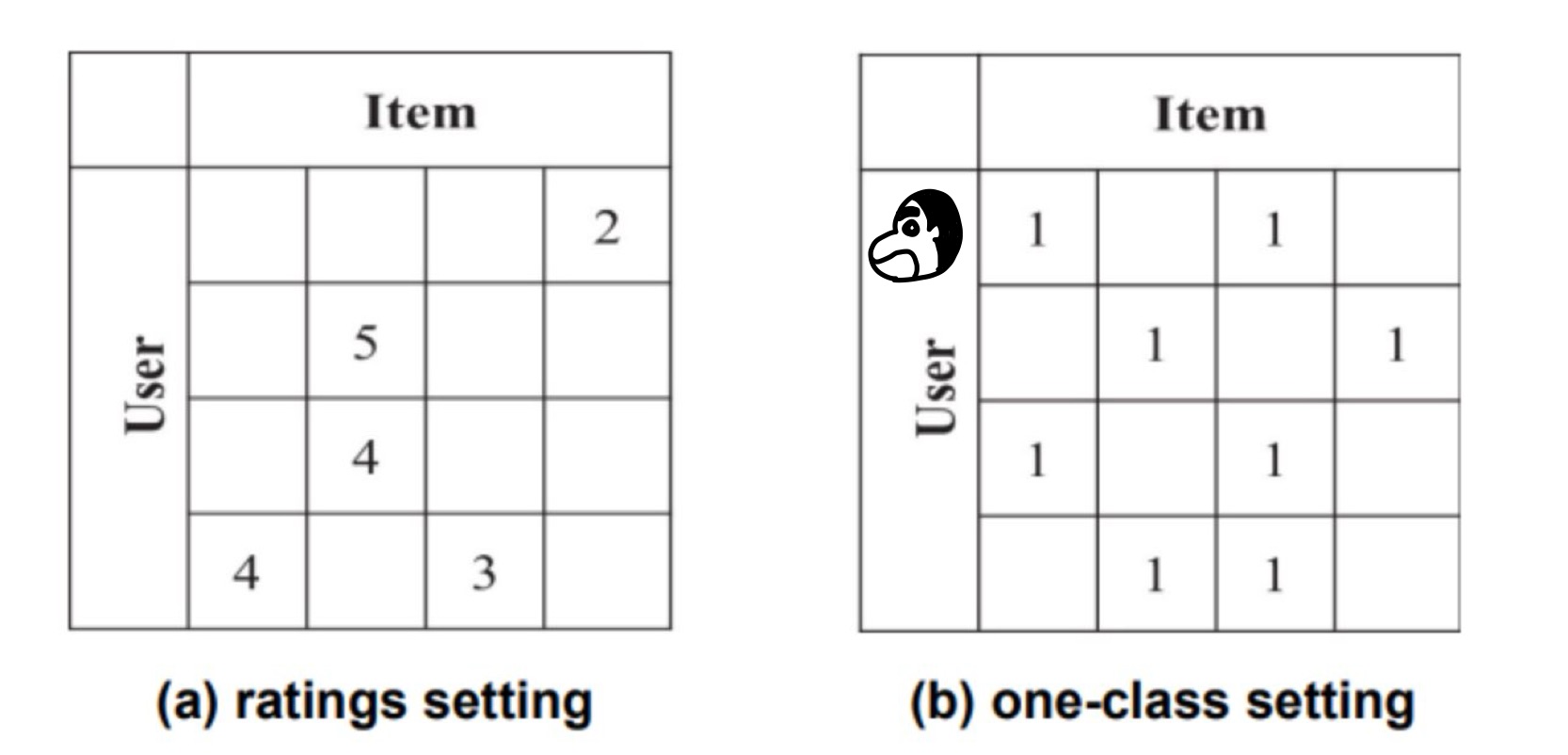
예를 들어 위 그림의 (b) one-class setting의 사용자 1인 짱구의 관측된 상효작용 아이템 1과 아이템 3을 통해 모델을 학습시킨 후 관측되지 않은 아이템 2와 4의 가능성을 점수로 나타내는 것이다.
OCCF 문제에 대한 가장 주요한 접근 방식은 NCF와 NGCF같은 구별적 모델링이다.
이 방식은 양적인 사용자-아이템 상호 작용 뿐만 아니라 부정적인 상호 작용까지 고려한다.
구별적 모델링에서는 각 사용자와 각 아이템의 표현 간의 유사성을 기반으로 이 둘이 상호 작용할 가능성을 나타내는 상호 작용 점수를 정의한다.
상호 작용 점수가 정의되면 모델은 이를 최적화하기 위해 아래와 같은 손실함수를 사용하여 최적화한다.
- Pointwise Prediction Loss: 양적 상호 작용에 대한 예측된 점수와 실제 간의 차이를 최소화한다.
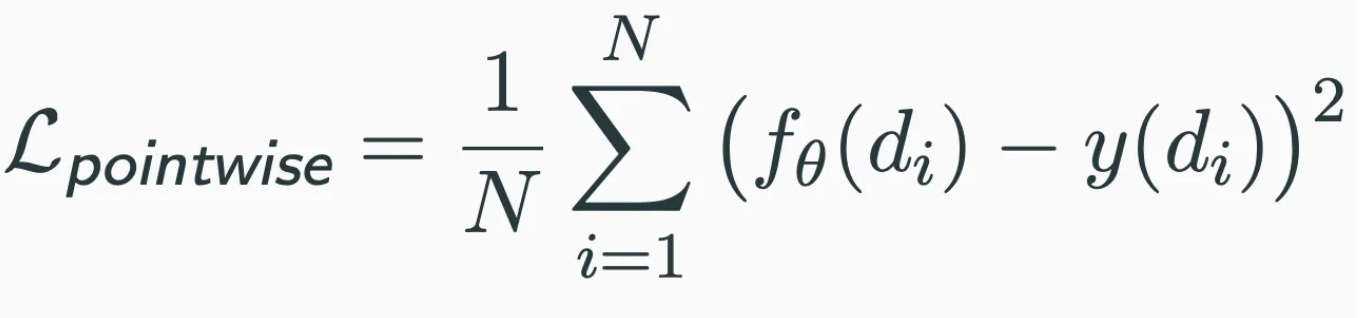
- Pairwise Ranking Loss: 양적 상호 작용과 부정적 상호 작용 간의 차이를 강조한다.
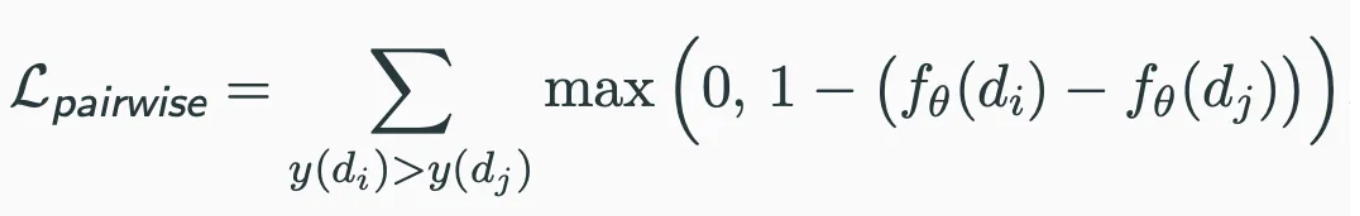
그렇다면 기존 모델들은 부정적 상호 작용을 무엇으로 정의할까?
기존 모델들의 경우 모든 과측되지 않은 상호 작용을 부정적으로 가정하며, 계산의 부담을 줄이기 위해 샘플링을 채택하기도 한다.
본 논문은 기존 모델들이 채택하고 있는 부정적인 상호 작용 샘플링에서 아래와 같은 한계점이 발생한다고 지적한다.
- 적은 양적 상호 작용이 관측될수록 "양적이지만 관측되지 않은" 상호 작용의 수가 증가하여 올바른 부정적 상호 작용을 샘플링하기 어려워진다.
- 모델의 수렴 속도와 최종 성능은 부정적인 상호 작용 샘플링을 위한 분포 선택에 따라 달라진다.
이러한 한계점을 극복하기 위한 해결책으로 본 논문은 BUIR이라는 새로운 OCCF 프레임워크를 제안한다.
BUIR 한계점 해결
BUIR의 주된 아이디어는 양적인 사용자-아이템 상호 작용 이 주어졌을 때, 와 의 표현을 서로 유사하게 만들어 선호 정보를 표현에 인코딩하는 것이다.
하지만 어떠한 부정적인 상호 작용도 사용하는 않는 단순한 end-to-end 학습 프레임워크는 모든 사용자 및 아이템을 동일한 표현으로 출력하게 만드는 으로 수렴할 수 있음을 언급한다.
따라서 BUIR는 이에 대한 해결책으로 두 개의 다른 인코더 네트워크를 사용하여 사용자와 아이템의 표현을 부트스트랩한다.
[참고]
bootstrapping은 추정된 값(네트워크의 출력)을 사용하여 대상 값(네트워크의 업데이트를 지도하는 값)을 추정하는 것을 나타낸다.
예를 들어, 예측된 pseudo-labels을 기반으로 한 semi-supervised learning도 부트스트랩 방법으로 간주될 수 있다.
이를 통해 BUIR는 기존 모델들의 한계점을 해결하면서도 으로 수렴하지 않을 수 있게 된다.
📖 BUIR: PROPOSED FRAMEWORK
Problem Formulation
OCCF의 목표는 앞서 말했듯이 사용자 와 아이템 가 상호 작용할 가능성을 나타내는 상호 작용 점수를 기반으로 각 사용자에 대해 가장 높은 점수를 가진 개의 아이템을 추천하는 것이다.
Bootstrapping the Representations
함수 는 사용자와 아이템의 표현을 생성하는 인코더 네트워크이다.
인코더의 가장 간단한 아키텍처인 임베딩 레이어는 각 사용자 ID(또는 아이템 ID)를 사용자(또는 아이템)의 잠재적인 요인을 나타내는 -차원 임베딩 벡터로 매핑한다.
각 인코더는 사용자 인코더와 아이템 인코더로 구성되며, 이들은 아래 그림에서 처럼 사용자 ID와 아이템 ID를 나타내는 원-핫 벡터를 입력으로 받는다.
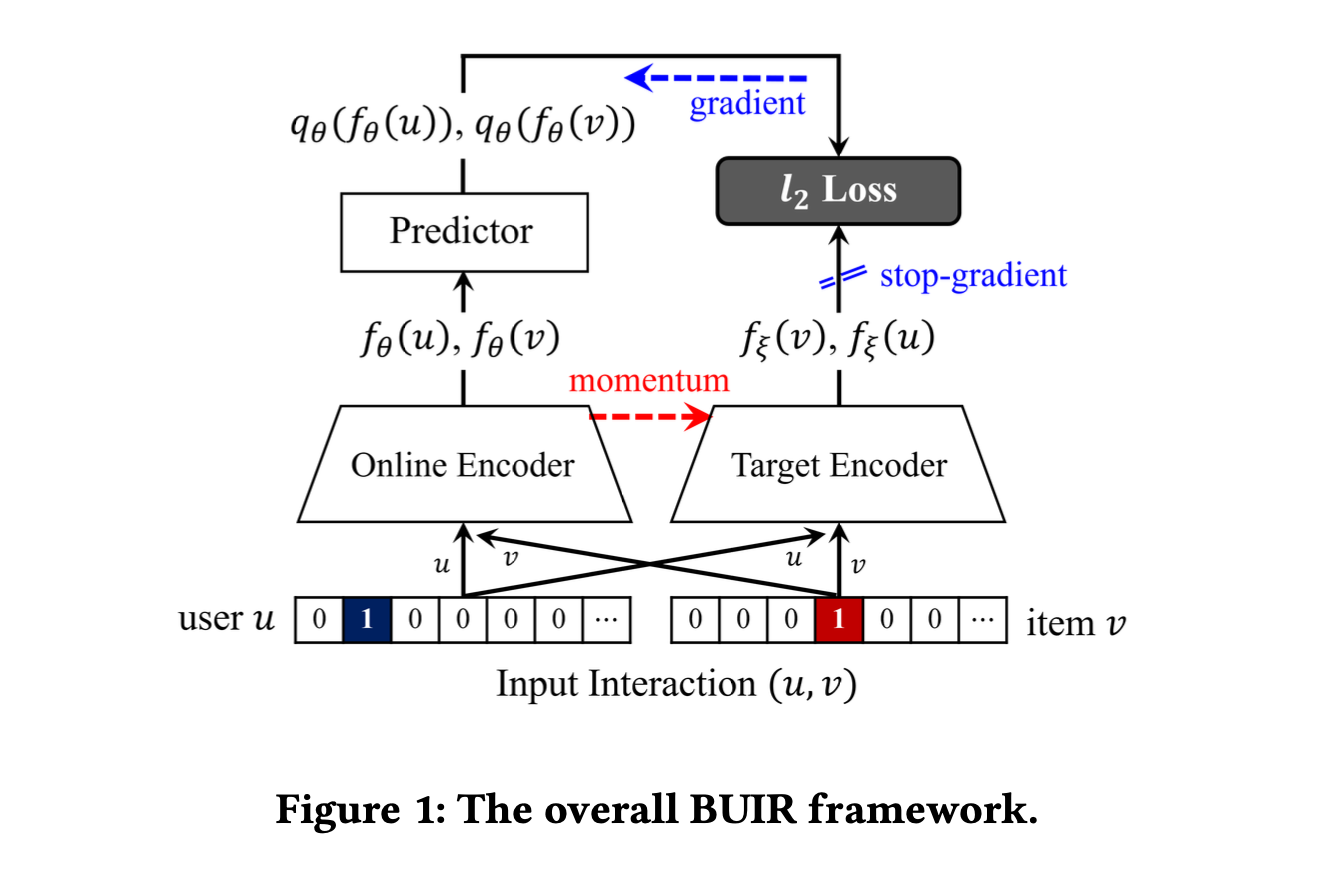
BUIR는 위에서 설명한 같은 구조를 가진 두 개의 인코더 네트워크를 활용한다.
온라인 인코더 와 타깃 인코더 는 각각 θ 및 ξ로 매개변수화되며, 아래와 같은 방식으로 각 인코더들이 최적화된다.
- 온라인 인코더는 사용자(및 아이템) 벡터가 타겟 인코더에 의해 생성된 아이템(및 사용자) 벡터에 일치하도록 평균 제곱 오차를 최소화하는 방향으로 최적화된다.
- 타겟 인코더는 모멘텀 기반의 이동 평균을 기반으로 업데이트되어 온라인 인코더를 천천히 근사하게 만든다.
최종 손실은 다음 두 개의 오류 항목을 포함하여 정의된다.
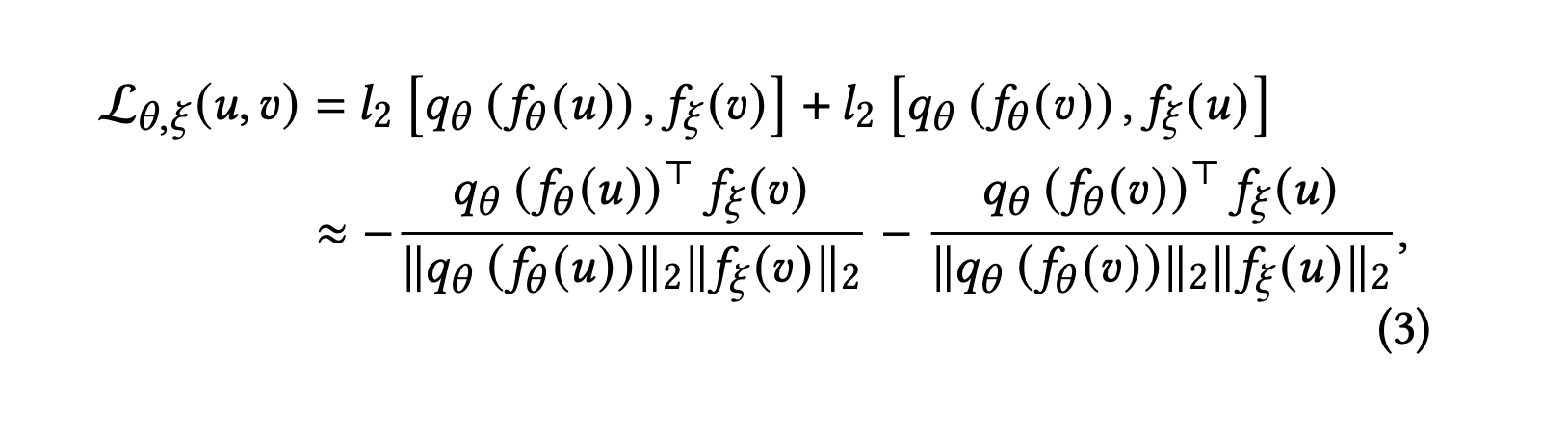
- 온라인 인코더의 각 사용자에 대한 출력 벡터 를 업데이트하여 타겟 인코더의 아이템 출력 벡터 를 예측하는 오류 항목
- 온라인 인코더의 각 아이템에 대한 출력 벡터 를 업데이트하여 타겟 인코더의 사용자 출력 벡터 를 예측하는 오류 항목
위 과정에서 온라인 인코더와 타겟 인코더의 매개변수는 아래과 같이 최적화된다.
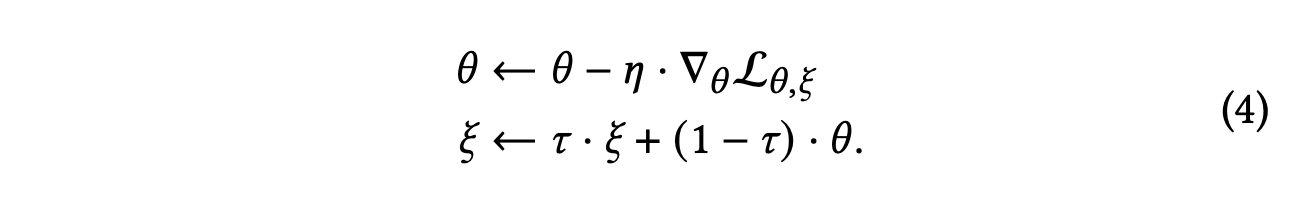
𝜂는 확률적 최적화를 위한 학습률이며, 𝜏 는 모멘텀 기반 이동 평균을 위한 모멘텀 계수이다.
온라인 인코더는 위에서 정의한 최종 손실 방정식으로부터 역전파 기울기를 통해 최적화되는 반면,
타겟 인코더는 온라인 인코더의 이동 평균으로 업데이트된다.
𝜏를 큰 값으로 설정 할 경우 타겟 인코더가 온라인 인코더를 천천히 근사화하도록 한다.
이러한 모멘텀 기반 업데이트는 ξ이 θ보다 더 느리게 진화하도록 만들어주어 온라인 인코더에게 향상되었지만 한편으로는 일관된 표현을 부트스트랩할 수 있도록 한다.
이러한 방식의 부트스트래핑 기반 표현 학습에 관한 몇가지 연구가 을 피할 수 있음을 실험적으로 입증했다고 한다.
Top-K Preferred Item Prediction
각 사용자에게 가장 선호할 것 같은 개의 아이템을 추천하기 위해 사용자와 아이템의 표현을 사용하여 상호 작용 점수 를 정의한다.
와 의 대칭적인 과계를 고려하기 위해 상호 작용 점수는 아래와 같이 크로스-예측 작업을 기반으로 정의한다.
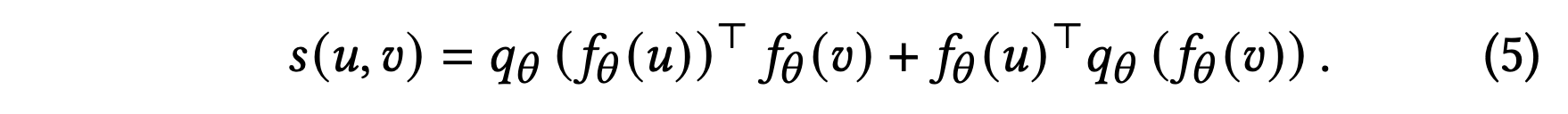
상호 작용 점수의 계산에는 온라인 인코더에서 얻은 표현만 사용하며, 타겟 인코더는 버려진다.
[참고]
BUIR 모델의 최적화 과정을 정리하면 같은 구성으로 이루어진 두 인코더는 한쪽이 사용자(혹은 아이템)의 임베딩 벡터 또 다른 한쪽이 아이템(혹은 사용자)의 임베딩 벡터를 출력하여 그 둘의 차이를 최소화하는 방향으로 진행된다.
이러한 과정에서 온라인 인코더는 기존의 역전파 기울기를 통해 최적화되는 반면, 타겟 인코더는 온라인 인코더가 모든 사용자(혹은 아이템)에 동일한 표현을 출력하는 것을 방지하는 역할로 조금씩 업데이트되는 출력을 내보낸다.
따라서 상호 작용 점수를 계산하는 데 온라인 인코더만 사용하는 것은 합당해 보인다.
Neighbor-based Data Augmentation
OCCF가 사용할 수 있는 정보로는 사용자와 아이템의 이웃 정보도 포함된다.
BUIR는 이러한 이웃 정보를 기반으로 증강된 더 많은 사용자-아이템 상호 작용을 고려한다.
BUIR에 적용한 데이터 증강 기술은 전처리 단계로써 사용하는 것이 아닌 훈련 중 각 입력 상호 작용에 확률적으로 적용된다.
사용자와 항목에 대해 이웃 인코더로 전달하기 전에 다음과 같은 증강 함수 𝜓를 적용한다.
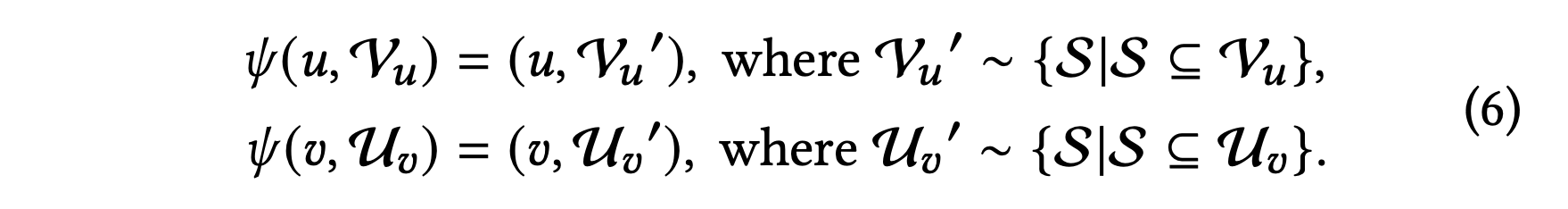
와 는 각 사용자(혹은 아이템)와 그에 대한 이웃의 쌍을 나타낸다.
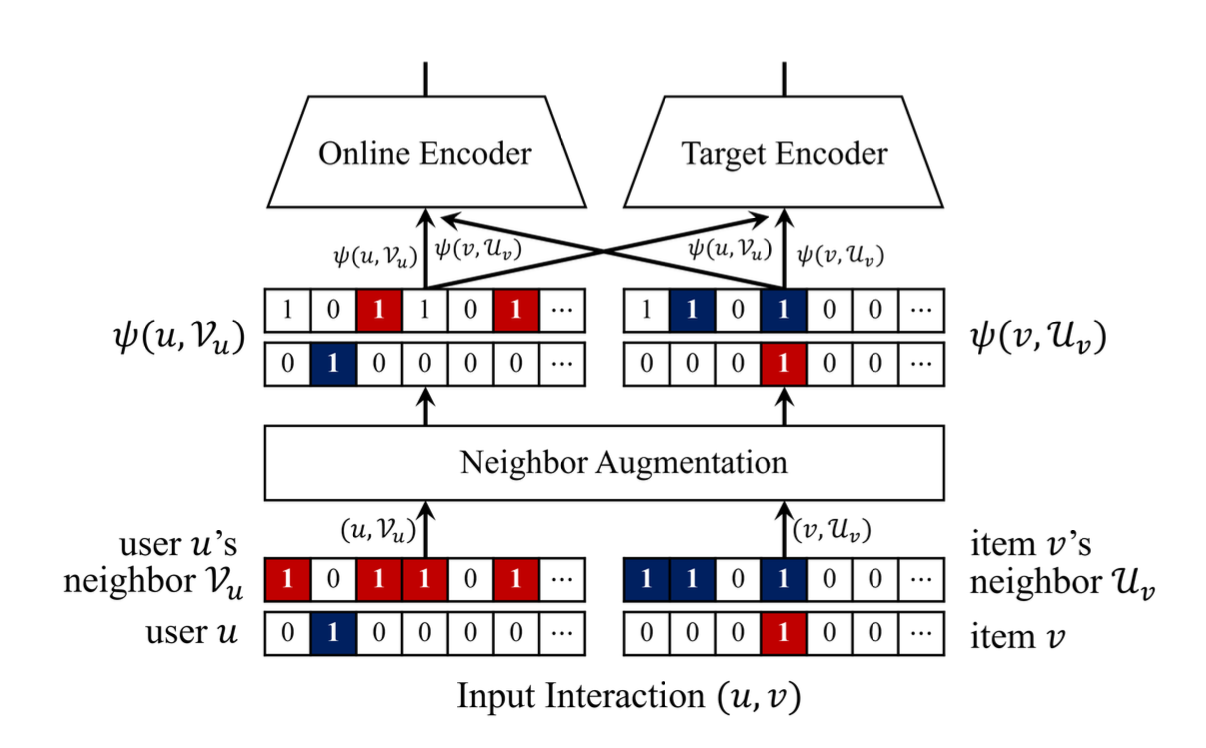
위 그림은 본래 데이터가 이웃 정보를 기반으로 어떻게 증강되는지를 잘 나타낸다.
📖 EXPERIMENTS
Comparison with OCCF Methods
다음의 표는 BUIR과 baseline 방법들의 top- 추천 성능을 비교한다.

BUIR는 모든 방법들 중에서 가장 우수한 성능을 보인다.
Comparison of different negative sampling strategies
부정적인 상호 작용의 샘플링 전략 선택이 추천 성능에 얼마나 영향을 미치는지 살펴본다.
실험은 부정 쌍을 긍정 쌍에 대해 샘플링하는 횟수를 {} 범위에서 설정하고 부정 샘플링에 대한 세 가지 다른 분포를 고려한다.
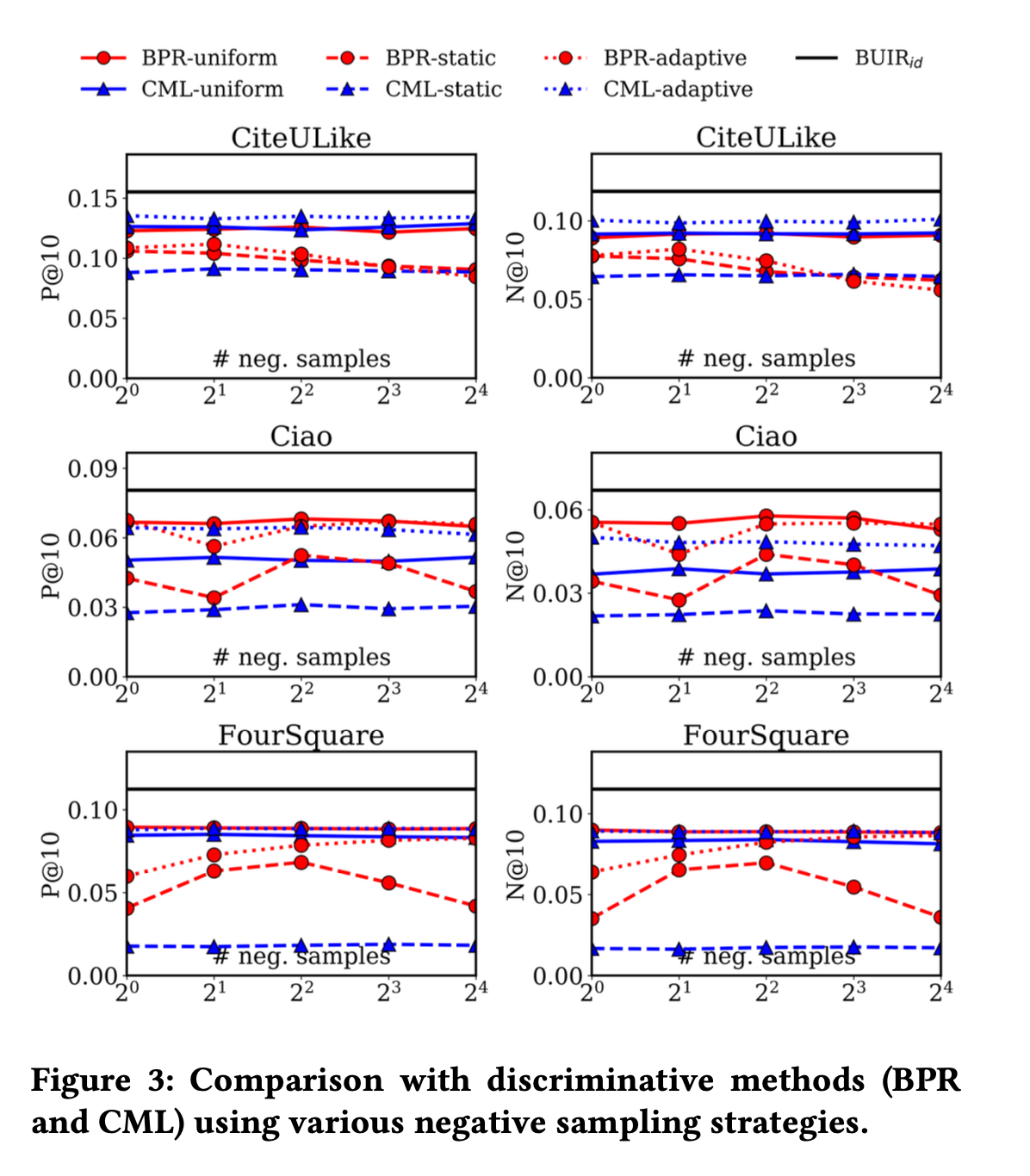
위 실험은 본 논문에서 언급한 기존 판별적 모델의 성능은 주로 샘플링 전략에 따라 크게 달라진다는 언급을 실험적으로 입증했다.
반면에 BUIR는 부정 샘플링에 의존하지 않으므로 부정적인 상호 작용의 샘플링 전략 선택에 영향을 받지 않고 판별적 모델보다 더 높은 성능을 보인다.
Ablation Study
다음 표는 BUIR 프레임워크 각 구성 요소의 효과를 검증하기 위해 몇 가지 구성 요소를 제거한 메서드의 성능을 보인다.
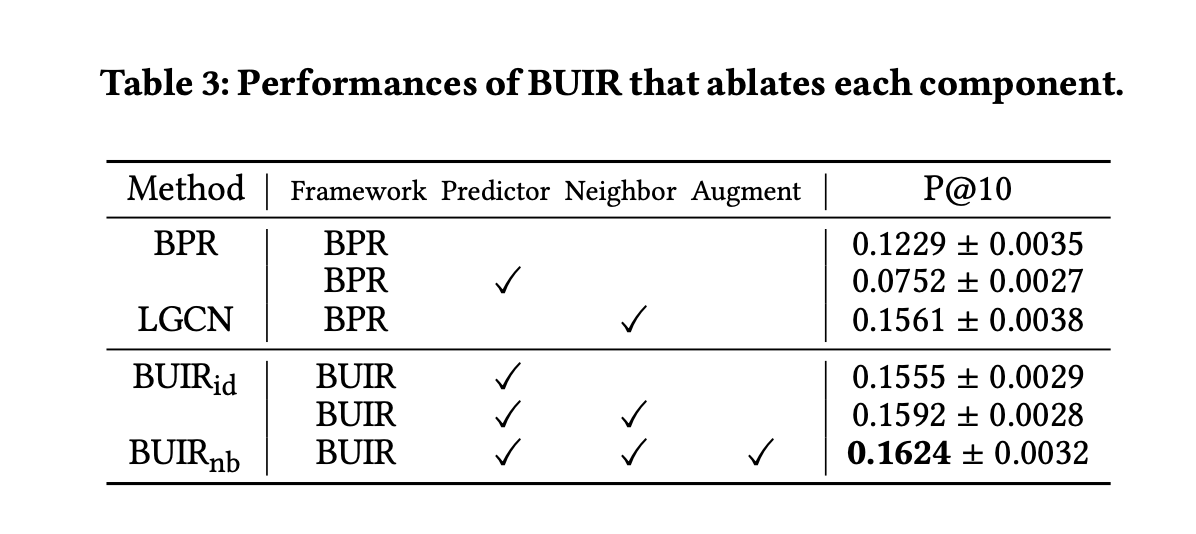
- BUIR가 이웃 정보를 기반으로 한 증강 요소를 포함하지 않더라도 BPR 프레임워크를 기반으로 한 LGCN보다 앞선 성능을 보임으로써 기존 모델들의 부정적인 상호 작용의 샘플링 문제를 해결했음을 나타낸다.
- BUIR이 이웃 정보를 기반으로 한 증강 요소를 포함함으로써 사용자-아이템 상호 작용의 다양한 뷰에서 이점을 얻어 성능을 더욱 향상시킴을 보인다.
Effect of Neighbor Augmentation
다음 표는 데이터 증강 기능에 대한 분석을 위해 확률적 데이터 증강 함수 ψ의 드롭 확률을 몇가지 범위 내에서 측정한 성능을 보인다.
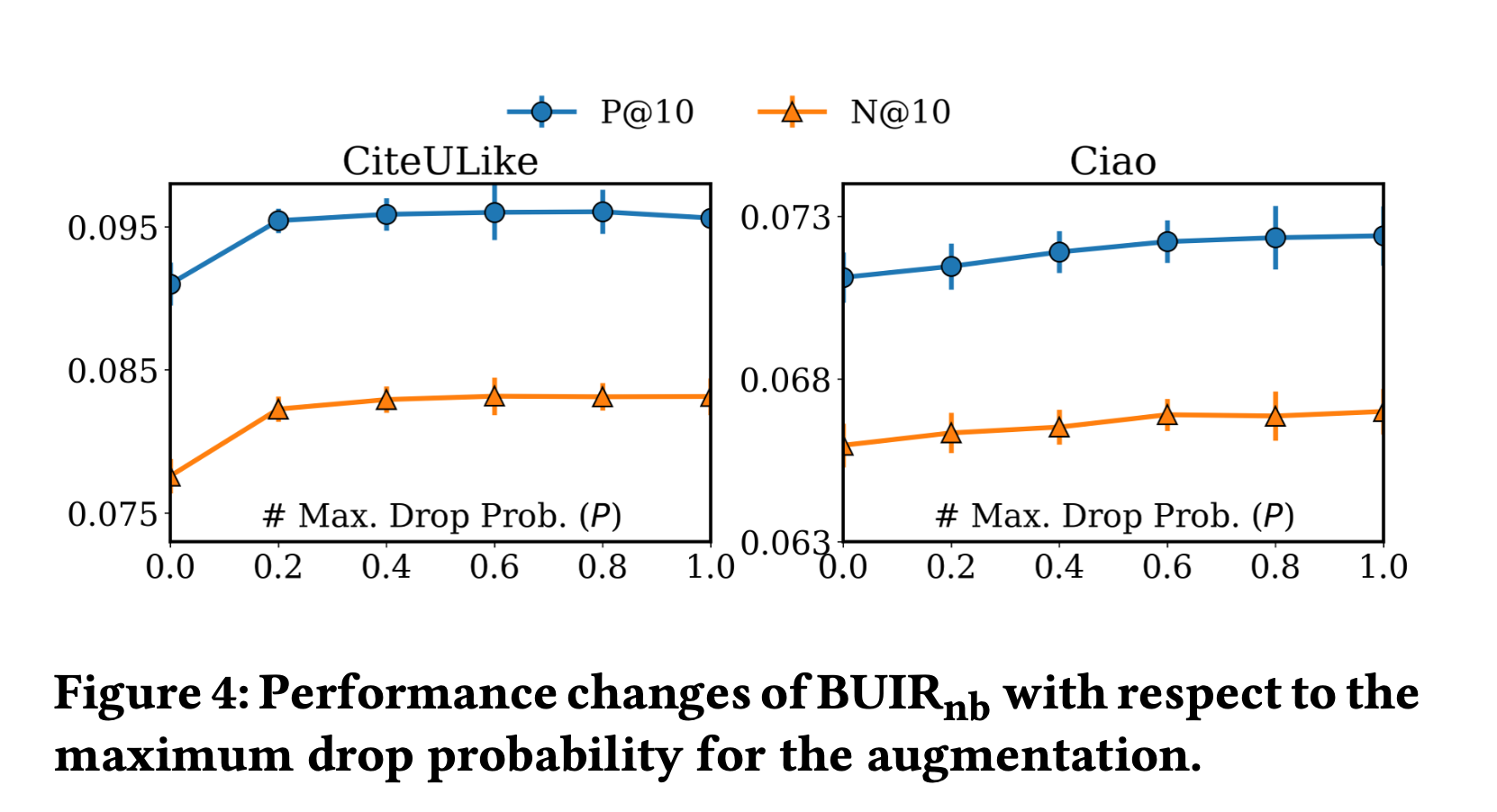
확률적 데이터 증강은 고정된 이웃 정보만을 사용하는 것보다 성능면에서 큰 개선을 가져왔음을 보인다.
Evaluation on Representation Quality
다음 그림은 모델로부터 획득한 표현의 품질을 평가하기 위해 다운스트림 작업의 성능을 비교한 것을 보인다.

BUIR은 다른 baseline 방법들보다 높은 분류 정확도를 달성했음을 보인다.
📖 CONCLUSION
LIGHTGCL 논문의 리뷰를 작성하는 과정에서 BUIR 프레임워크를 알게 됐다.
본 논문은 대조 대상으로 negative samples을 사용하지 않고 부트스트랩 방식을 통해 모델을 학습하여 보다 나은 성능을 실험적으로 입증했다는 점에서 contrastive learning의 새로운 관점을 제시한 의미있는 논문이라 생각한다.
개인적으로는 본 논문을 학습하는 과정에서 부트스트랩이라는 새로운 접근법을 배울 수 있어서 좋았다.
Reference
Bootstrapping User and Item Representations for One-Class Collaborative Filtering
Pointwise, Pairwise and Listwise Learning to Rank
