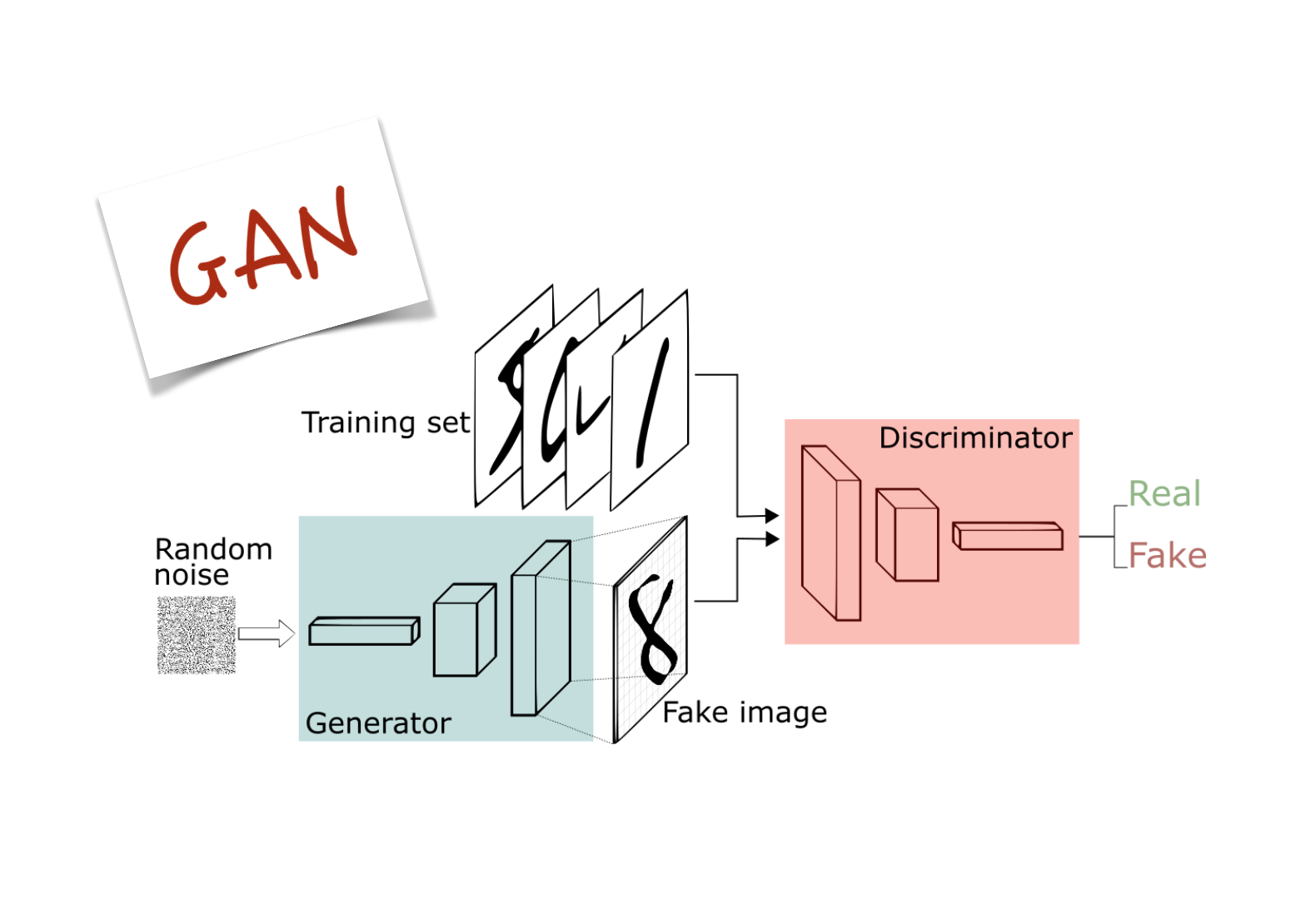
GAN
GAN은 적대적인 생성 모델(생성자)와 판별 모델(판별자)네트워크 두 개가 경쟁하는 것입니다. 생성자는 랜덤한 잡음을 원본 데이터셋에서 샘플링한 것처럼 보이는 샘플로 변환하고, 판별자는 원본 데이터셋에서 추출한 샘플인지 생성자가 만든 가짜인지를 구별합니다. 훈련을 할수록 생성자가 좀 더 실제 데이터에 근접하게 데이터를 생성해내고, 판별자는 점점 더 실제 데이터와 생성자가 만들어낸 데이터를 구분하는 능력을 발전시키기 때문에 서로 적대적인 경쟁자로 인식하여 모두 발전하게 됩니다.
생성 모델은 진짜 데이터와 유사한 가짜 데이터를 만들 수 있게 되고, 판별 모델은 진짜 데이터와 가짜 데이터를 구분 할 수 없게 됩니다. 즉, GAN은 생성 모델은 분류에 성공할 확률을 낮추려하고, 판별 모델은 성공할 확률은 높이려 하면서 서로 적대적으로 발전시키는 구조입니다. 단순하게 창과 방패를 떠올리시면 쉽게 이해가 됩니다.
GAN의 핵심은 두 네트워크를 어떻게 교대로 훈련하는지에 있습니다.
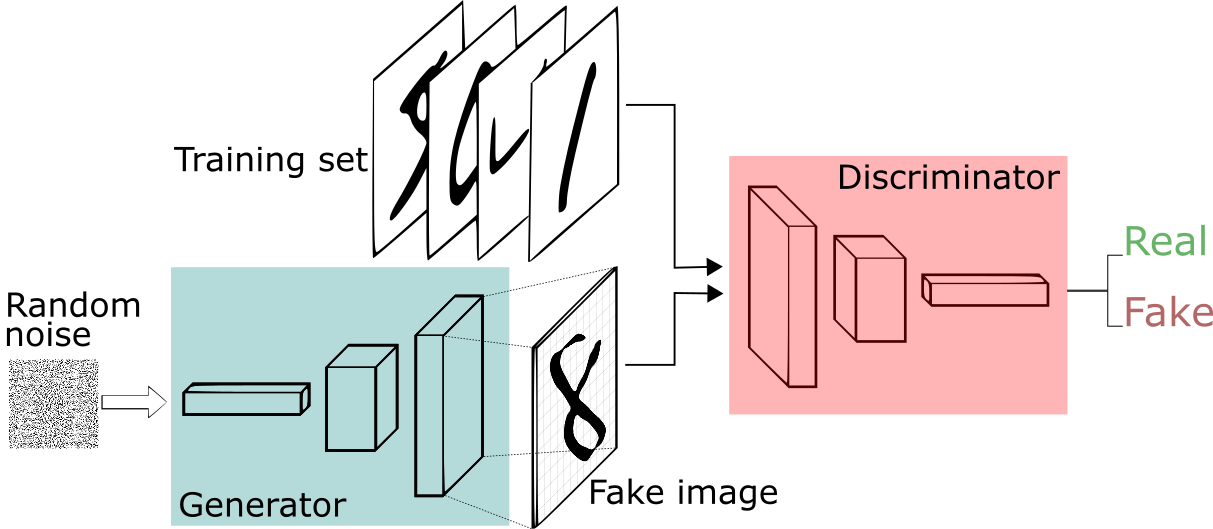
원본 논문에서는 conv층 대신 fc층을 사용했습니다. 하지만 합성곱 층이 판별자의 예측 성능을 크게 높여 준다고 밝혀졌고, 이런 종류의 GAN을 DCGAN(deep convolutional adversarial network)이라고 부릅니다. 이제는 기본적으로 GAN이 'DC'의 의미를 내포하고 있습니다.
- DCGAN

Train
훈련 세트에서 진짜 샘플을 랜덤하게 선택하고 생성자의 출력을 합쳐서 훈련 세트를 만들어 판별자를 훈련합니다.
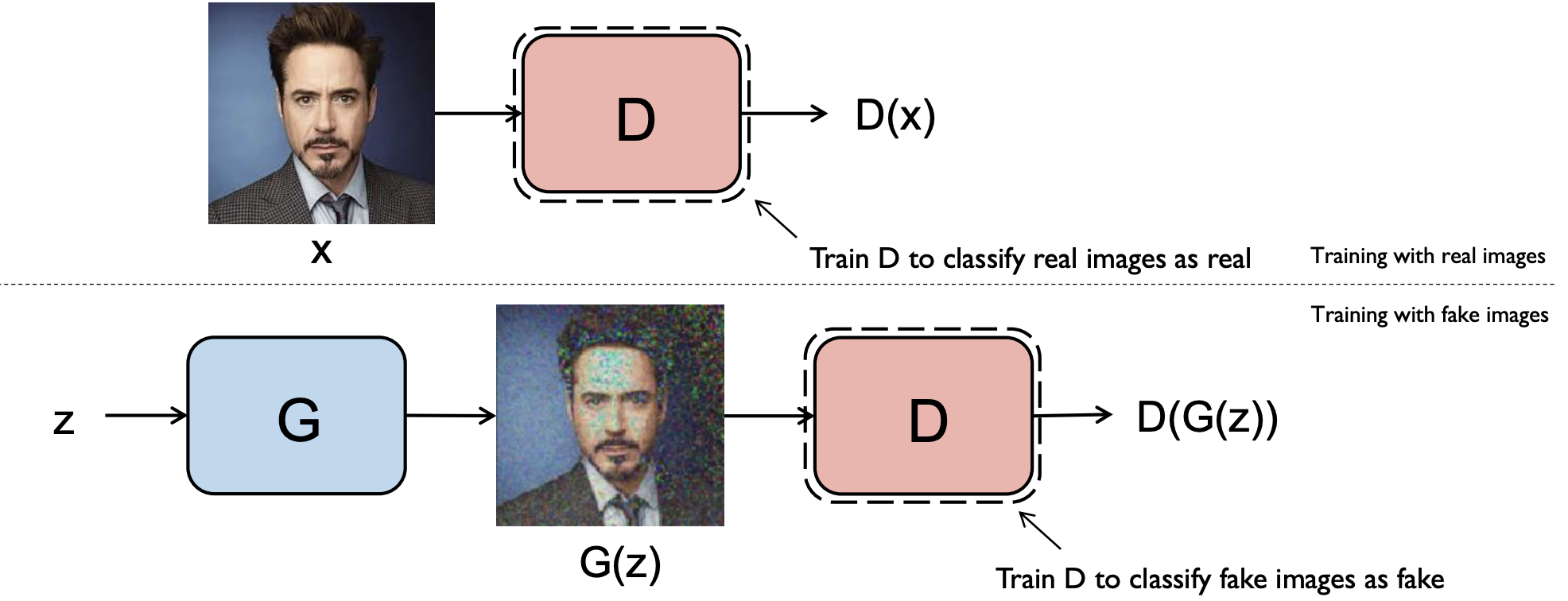
우리가 하고자 하는 것은 생성자를 학습을 시키는 것입니다. 하지만 그 전에 판별자를 학습을 시켜야 합니다. 판별자는 실제 training set인 경우 output이 sigmoid(binary classification이므로)를 통과해 1에 가까운 숫자가 나오도록 학습을하고 생성자가 만들어낸 Fake image가 들어갔을 때는 output이 0에 가까운 숫자가 나오도록 학습을 합니다.
즉, 판별자는 진짜 이미지는 진짜로 인식을하고, 가짜 이미지는 가짜로 인식하도록 학습을 하게 됩니다.
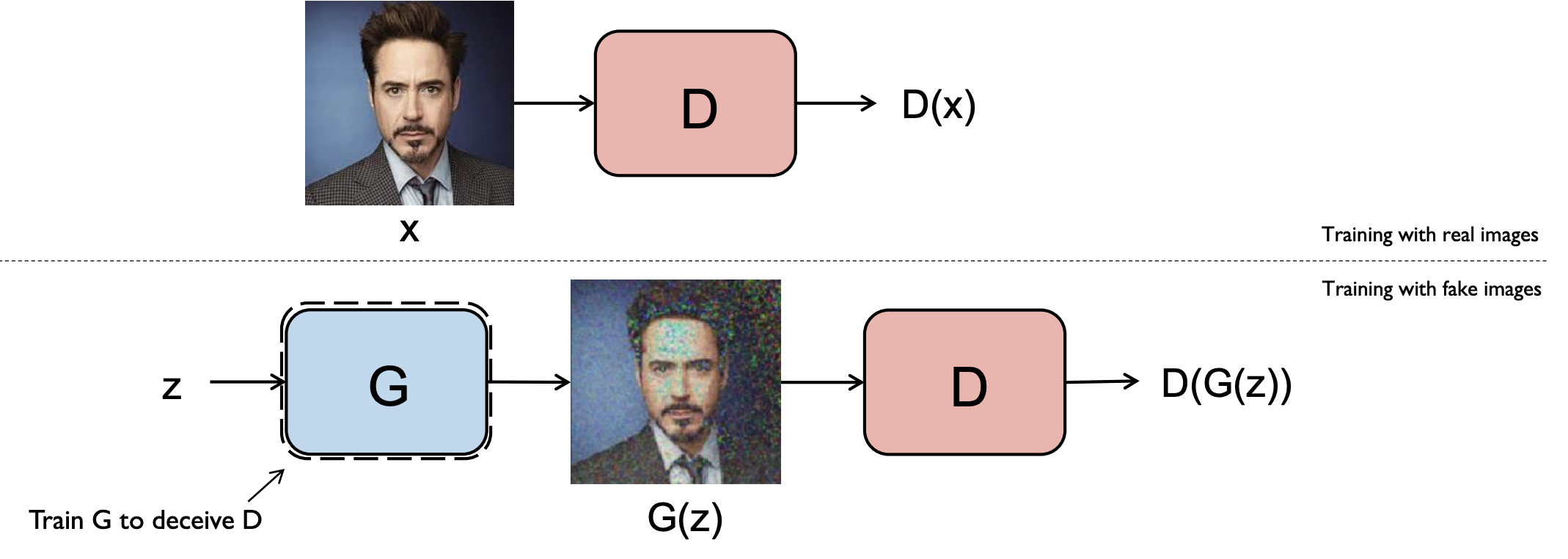
판별자가 학습이 진행이 끝난 후에 생성자를 학습시킵니다. 생성자의 훈련은 진짜 이미지가 잠재 공간의 어떤 포인트에 매핑되는지 알려 주는 훈련 세트가 없기 때문에 생성자 훈련은 더 어렵습니다. 그래서 판별자를 속이는 이미지를 생성합니다. 즉, 이 이미지가 판별자의 입력으로 주입될 때 1에 가까운 값이 출력되어야합니다. 그 이유는 진짜같은 가짜 이미지를 만들어야 하기 때문입니다. 그러므로 생성자를 훈련하기 위해 먼저 판별자를 연결한 모델을 만듭니다. 입력은 판별자의 경우 고정된 이미지의 벡터값이지만 생성자의 경우 랜덤하게 생성한 n차원의 잠재 공간 벡터입니다.
생성자(전체 모델)을 훈련할 때 생성자의 가중치만 업데이트되도록 판별자의 가중치를 동결하는 것이 중요합니다.
그렇지 않으면 생성자가 만든 이미지를 진짜라고 여기도록 조정되기 때문입니다. 판별자가 약해서가 아니라 생성자가 강하기 때문에 생성된 이미지가 1(진짜 이미지)에 가까운 값으로 예측되어야 합니다.
좀 더 수학적으로 보게 되면 아래와 같이 학습을 하게 됩니다.
판별자 Objective function

생성자 Objective function

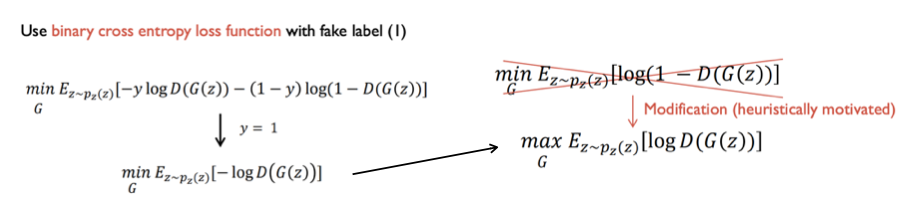
Objective function은 실제 구현시 결론적으로 binary cross entropy loss function을 사용합니다.
먼저 판별자 loss function 구현부터 보면 판별자의 objective function은 최대화가 목표이기 때문에 앞에 loss를 최소화 하게 됩니다. 즉 objective function을 최대화 하는 것과 entropy loss function을 최소화하는 것은 결국 같습니다.

이어서 생성자는 위 그림의 object function에서 두번째 항을 최소화 하는 것이 목표입니다. D(G(z))가 1(진짜 이미지)에 가까운 값을 내놓도록 학습해야 하기 때문에 loss function 은 y=1, p=D(G(z))를 넣게 되면 아래처럼 objective function의 두번째 항만 해당됩니다.

하지만 이부분을 실제로 최소화 하지는 않습니다.
생성자는 처음에 학습이 제대로 안되었기 때문에 형편없는 이미지를 만들어내므로 D(G(z))값이 거의 0에 가깝게 나옵니다. 그때 아래 사진처럼 기울기의 절대값이 크지 않습니다.

그래서 기울기의 크기를 크게 하기 위해 아래와 같이 바뀌게 되고, 기울기는 매우 커지게 되는데 이 의미는 초반에 생성자가 형편없는 이미지를 생성해서 판별자가 가짜로 확신하는 상황을 빠르게 벗어날 수 있도록 해줍니다. 참고로 이 내용은 휴리스틱하게 나오게 되었습니다.

compile 예시 코드 (keras)
get_opti함수에서 Adam을 불러옵니다.
def _build_adversarial(self):
### COMPILE DISCRIMINATOR
self.discriminator.compile(
optimizer=self.get_opti(self.discriminator_learning_rate)
, loss = 'binary_crossentropy'
, metrics = ['accuracy']
)
### COMPILE THE FULL GAN
self.set_trainable(self.discriminator, False)
model_input = Input(shape=(self.z_dim,), name='model_input')
model_output = self.discriminator(self.generator(model_input))
self.model = Model(model_input, model_output)
self.model.compile(optimizer=self.get_opti(self.generator_learning_rate) , loss='binary_crossentropy', metrics=['accuracy']
, experimental_run_tf_function=False
)
self.set_trainable(self.discriminator, True)학습 순서는 아래와 같은 방식으로 진행됩니다.
def train_discriminator(self, x_train, batch_size, using_generator):
valid = np.ones((batch_size,1))
fake = np.zeros((batch_size,1))
# 진짜 이미지로 훈련
idx = np.random.randint(0, x_train.shape[0], batch_size)
true_imgs = x_train[idx]
self.discriminator.train_on_batch(true_imgs, valid) # 1
# 생성된 이미지로 훈련
idx = np.random.randint(0, 1, (batch_size, z_dim))
gen_imgs = generator.predict(noise)
self.discriminator.train_on_batch(gens_imgs, fake) # 2
def train_generator(self, batch_size):
valid = np.ones((batch_size,1))
noise = np.random.normal(0, 1, (batch_size, self.z_dim))
self.model.train_on_batch(noise, valid) # 3
epochs = 20000
batch_size = 64
for epoch in range(epochs):
train_discriminator(x_train, batch_size)
train_generator(batch_size)- 판별자의 훈련은 먼저 타깃 1과 진짜 이미지로 배치를 만들어 수행합니다.
- 그다음 타깃 0과 생성된 이미지로 배치 훈련합니다.
- 생성자의 훈련은 타깃1과 생성된 이미지로 배치를 만들어서 수행합니다. 이때 판별자는 동결되었기 때문에 가중치는 변하지 않고, 판별자가 1에 가까운 값으로 예측하는 이미지를 생성할 수 있도록 학습하게 됩니다.
어느 정도 학습을 하면 판별자와 생성자가 평형을 이루어 생성자가 판별자로부터 유용한 정보를 학습하고, 이미지 품질이 향상되기 시작할 것입니다.
신경망이 랜덤한 잡음을 의미 있는 어떤 것으로 바꾸게 되었습니다. 원본 픽셀 이외에는 모델에 어떤 추가적인 정보도 제공하지 않았지만 고수준 벡터(눈, 코, 입)들을 스스로 만듭니다. naive bayes모델은 고수준 특성을 구성하기 위한 픽셀 사이의 상호 의존 관계를 모델링 할 수 없기 때문에 이런 복잡한 수준을 달성할 수 없습니다.
참고
https://www.slideshare.net/NaverEngineering/1-gangenerative-adversarial-network
