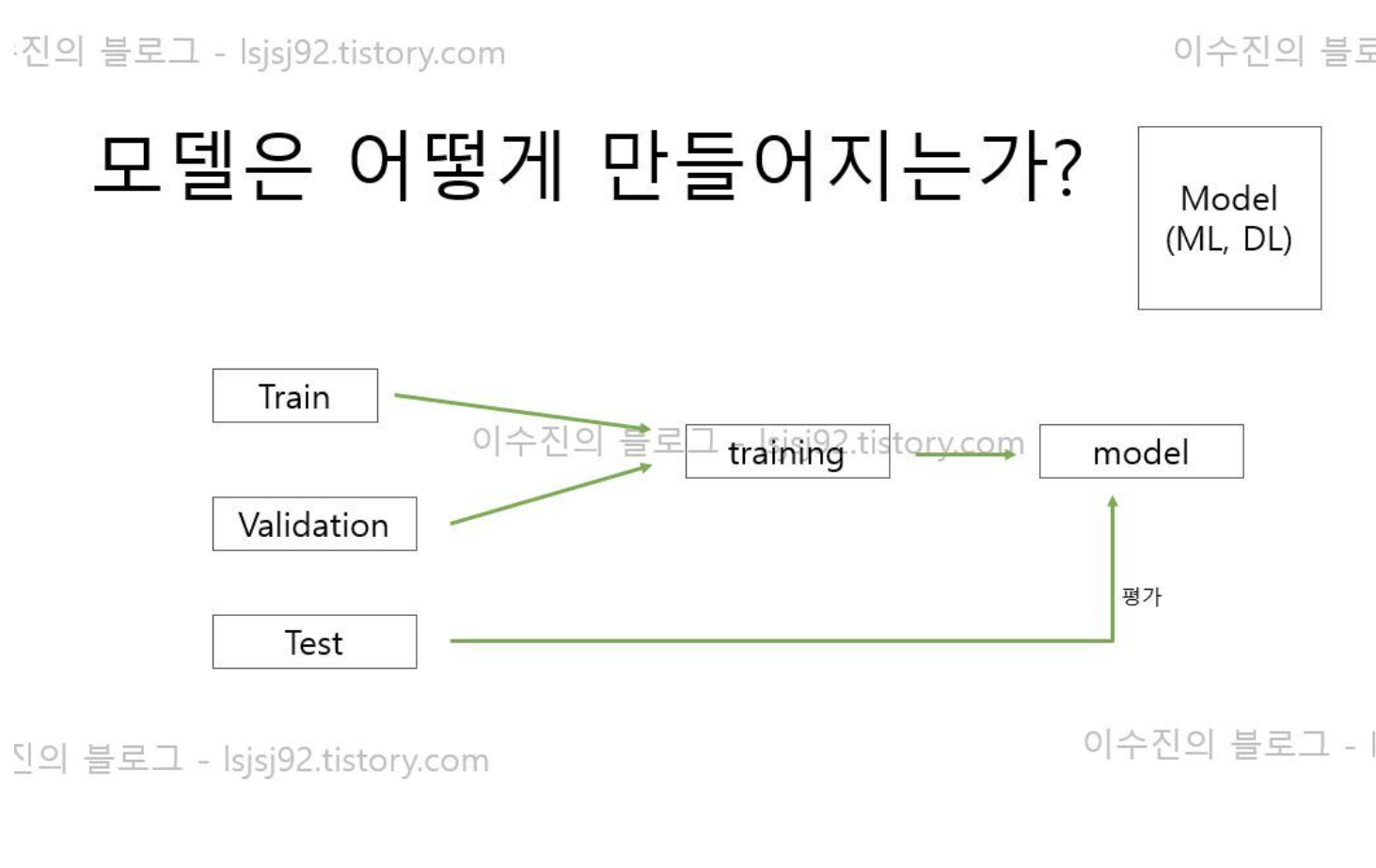
데이터 전처리 및 모델(사이킷런 활용)
Machien_Learning2에 이어서!
df 변수는 데이터를 저장한 dataframe 약자 입니다
- 사이킷런(sklearn) 라이브러리 활용하기
- 데이터 전처리 : 범주형 데이터
- 데이터 전처리 : 수치형 데이터
- 사이킷런에서 제공하는 데이터셋 활용
- 머신러닝 (사이킷런에서 제공하는 모델 활용)
1. 사이킷런(sklearn) 라이브러리 활용하기
1) 사이킷런(sklearn) 이란? (학습: fit, 예측: predict)
- 파이썬을 활용한 머신러닝 도구
- 데이터 분석(예측)을 위한 간단하고 효율적인 도구
- 누구나 쉽게 다양한 상황에서 활용 가능
- 오픈 소스
2) 사이킷런으로 할 수 있는 것
- 분류 (ex.스팸문자)
- 회귀 (ex.가격 예측)
- 클러스터 (ex. 고객 세그먼트, 비지도학습)
- 차원축소 (ex. 변수(컬럼)의 수를 줄임)
- 모델 선택 (ex. 모델 튜밍, 평가)
- 전처리 (ex. 데이터 가공/변환)
2. 데이터 전처리 : 범주형 데이터
-
머신러닝은 숫자형 밖에 받을 수 없다!!!
-
레이블 인코딩 : 숫자로 변환하기 위한 방법1. 값의 종류 별로 0~n 까지 변환
-
원-핫 인코딩 (one-hot) : 숫자로 변환하기 위한 방법2. 0,1로 이진 법으로 값을 변환
1) 데이터 변경
df.loc[인덱스명,'컬럼 명'] = '변경할 컬럼 명'
2) 활용할 데이터 선택 (.copy로 사본에다가 작업)
df[['컬럼명','컬럼명1','컬럼명2','컬럼명3','컬럼명4'...]].copy # 데이터 프레임 형태라 대괄호 2개
3) 레이블(label) 인코딩
-
type 확인
df.info()
-
사이킷 런 호출
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder() # 변수에 담기 -
해당 컬럼 인코딩 변환
le.fit(df['컬럼 명'])
le.tranaform(df['컬럼 명'])
df['컬럼 명'] = le.fit_transform(df['컬럼 명']) # 위 2줄을 한줄로 표현할 수 있다 -
여러개의 컬럼을 한번에 인코딩 하기
from skearn.preprocessing import LabelEncoder # 맨위에 한번만 호출 해도 됨
cols = ['컬럼 명', '컬럼 명1', '컬럼 명2', ...] # 인코딩 할 컬럼 리스트 만들기
for col in cols: # 컬럼에 인코딩 작업 반복하기 위해 반복문 사용
le = LabelEncoder()
df[col] = le.fit_transform(df.[col]) -
컬럼이 많을 때, 리스트 없이 인코딩 방법 (.select_dtypes(), .columns)
중요! object type 값들을 숫자형으로 바꿔야 한다
df.info() # type 확인
cols = df.select_dtypes(include='object').columns # type에서 'object'를 고르고, columns 명 출력4) 원핫(one_hot) 인코딩
from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder(sparse=False) # sparse=False 해야 array 형태로 반환된다
cat = ohe.fit_transform(df[['컬럼 명']]) # 원핫 인코딩은 데이터 프레임 형태가 필요함 [[]]- 카테고리 확인 (원핫 인코딩 시 종류 수만큼 이진법 표현으로 컬럼이 많이 생성 된다)
ohe.categories_. # 인코딩 시 나오는 컬럼 명
- 피처(컬럼) 이름과 카테고리 (이걸 위주로 사용한다. 종류가 너무 많아 질 경우)
ohe.get_feature_names_out() # 인코딩 시 컬럼 명 들
- 데이터 프레임으로 변환
df_cat = pd.DataFrame(cat, columns=ohe.get_feature_names_out()) # columns = 컬럼 명까지 붙이기 위함
- 데이터 프레임 합치기 (기존 데이터 프레임 + 원핫 인코딩 데이터 프레임)
pd.concat([df,df_cat],axis=1). # 기준 축(열) 옆에 합치기 axis=1
- 변환 되어 필요없는 기존 컬럼 삭제
df = df.drop(['해당 컬럼명'],axis=1)
- 카테고리 확인 (원핫 인코딩 시 종류 수만큼 이진법 표현으로 컬럼이 많이 생성 된다)
5) 원핫(one_hot) 인코딩 심화
- 여러개 컬럼 한번에 인코딩 하기
인코딩 할 컬럼 명 확인하고 cat에 인코딩한 컬럼 담고, df_cat에 데이터 프레임화한 것을 담는다(컬럼 이름명까지 더해서)
cols = df.select_dtypes(include='object').columns
ohe = OneHotEncoder(sparse=False)
cat = ohe.fit_transform(df[cols])
df_cat = pd.DataFrame(cat,columns=ohe.get_feature_names_out())원핫 인코딩 된 데이터프레임과 합치기
df = pd.concat([df, df_cat], axis=1)
df = df.drop(cols, axis=1). # 인코딩 되기 전 기존 컬럼 삭제
6) pandas를 활용해서 한 줄로 원핫 인코딩 하기 (데이터가 단순해야 가능하다)
-
get_dummies 는 인코딩 시 컬럼의 수가 달라질 수 있어서 머신러닝에서는 적합하지 않다 (머신러닝에 train, test 데이터들의 컬럼 수가 같아야 한다)
pd.get_dummies(df) # 위 과정을 그대로 원핫 인코딩한 출력과 같다
3. 데이터 전처리 : 수치형 데이터
1) 표준화 (StandardScaler) : 머신러닝 이해하기 좋은 데이터로 변환하기 위함
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit_transform(df[['컬럼 명']]) # 해당 컬럼 표준화
- StandardScaler 여러 변수(컬럼)에 적용
cols = ['컬럼명', '컬럼명1', '컬럼명2',..]
scaler = StandardScaler()
df[cols] = scaler.fit_transform(df[cols])
2) 정규화 (MinMaxScaler) : 0~1 사이 값으로 변환해서 데이터 사이즈 축소
-
표준화 시키고 해도 되고 정규화(MinMaxScaler) 먼저 해도 됩니다. 상황에 따라 모델 성능에 맞게 사용할 것!
from sklearn.preprocessing import MinMaxScaler
cols = ['컬럼명', '컬럼명1', '컬럼명2',..]
scaler = MinMaxScaler()
df[cols] = scaler.fit_transform(df[col])
4. 사이킷런에서 제공하는 데이터셋 활용
1) 사이킷런에서 제공하는 데이터셋 불러오기
1-1) 유방암 데이터셋 호출/활용
from sklearn.datasets import load_breast_cancer # 유방암 데이터셋 호출
dataset = load_breast_cancer()
- 필요한 것만 뽑아내기
dataset.feature_names # 컬럼 명 확인
dataset.target # 타겟 값 확인
dataset.data # 데이터 확인
- 원하는 출력값 데이터 프레임 형태로 바꾸기 (data= ? / columns= ?)
cancer_df = pd.DataFrame(data=dataset.data , columns=dataset.feature_names) # data= 뭐, columns = 뭐~ 를 데이터 프레임 형태로 바꾸기
- 타겟 추가하기
cancer_df['target'] = dataset.target # target 열 생성 후 target 값 대입
1-2) 당뇨병 데이터셋 호출/활용
from sklearn.datasets import load_diabetes
dataset = load_diabetes()
dataset.feature_names
dataset.target
dataset.data
diabetes_df = pd.DataFrame(data=dataset.data, columns=dataset.feature_names)
diabetes_df['target'] = dataset.target
diavetes_df.head() # 상위 5개만 출력 해보기
5. 머신러닝 (사이킷런에서 제공하는 모델 활용)
1) 분류 문제 진행
- 유방암 검증 데이터 분리
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x,y, test_size=0.3, random_state=1004) #test_size = 0.3 (test_data 30%, train_data 70%/ random 스플릿 값 범위 고정, 모델 성능 확인 위함) - train 데이터 확인(x)
x_train.head()
- 데이터 크기
x_train.shape, x_test.shape, y_train.shape, y_test.shape
- 모델에다가 분리한 데이터 넣어서 학습(fit) 시키고 예측(pred) 시키기
from sklearn.tree import DecisionTreeClassfier # 모델 선택하기 (의사결정나무 모델)
model = DecisionTreeClassfier()
model.fit(x_train, y_train) # 학습
pred = model.predict(x_test) # 예측 - 평가 (accuracy)
from sklearn.metrics import accuracy_score
accuracy_score(y_test, pred) - (실제값 = y_test , 예측값 = pred) , 예측값이 실제값과 얼마나 매치가 잘 되어있는지 평가하는 것 (확률로 평가)
2) 회귀 진행
- 당뇨병 검증 데이터 분리
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x,y, test_size=0.3, random_state=1004) - train 데이터 확인(x)
x_train.head()
- 데이터 크기
x_train.shape, x_test.shape, y_train.shape, y_test.shape
- 모델에다가 분리한 데이터 넣어서 학습(fit) 시키고 예측(pred) 시키기
from sklearn.linear_model import LinearRegression # 모델 선택하기 (선형회귀 모델)
model = LinearRegression ()
model.fit(x_train, y_train) # 학습
pred = model.predict(x_test) # 예측
pred - 평가 (accuracy)
from sklearn.metrics import mean_squared_error (mse라 한다)
mean_squared_error(y_test, pred) - (실제값 = y_test , 예측값 = pred) , 예측값이 실제값과 얼마나 매치가 잘 되어있는지 평가하는 것 (오차값으로 평가)