머신러닝의 지도학습 (분류)
목 차
1. 의사결정나무 (DicisionTree)
2. 랜덤포레스트 (RandomForest)
3. xgboost
4. 교차검증 (CrossValidation: CV)
- 평가
1. 의사결정나무 (DicisionTree)
- 지도학습 알고리즘 (분류, 회귀 사용)
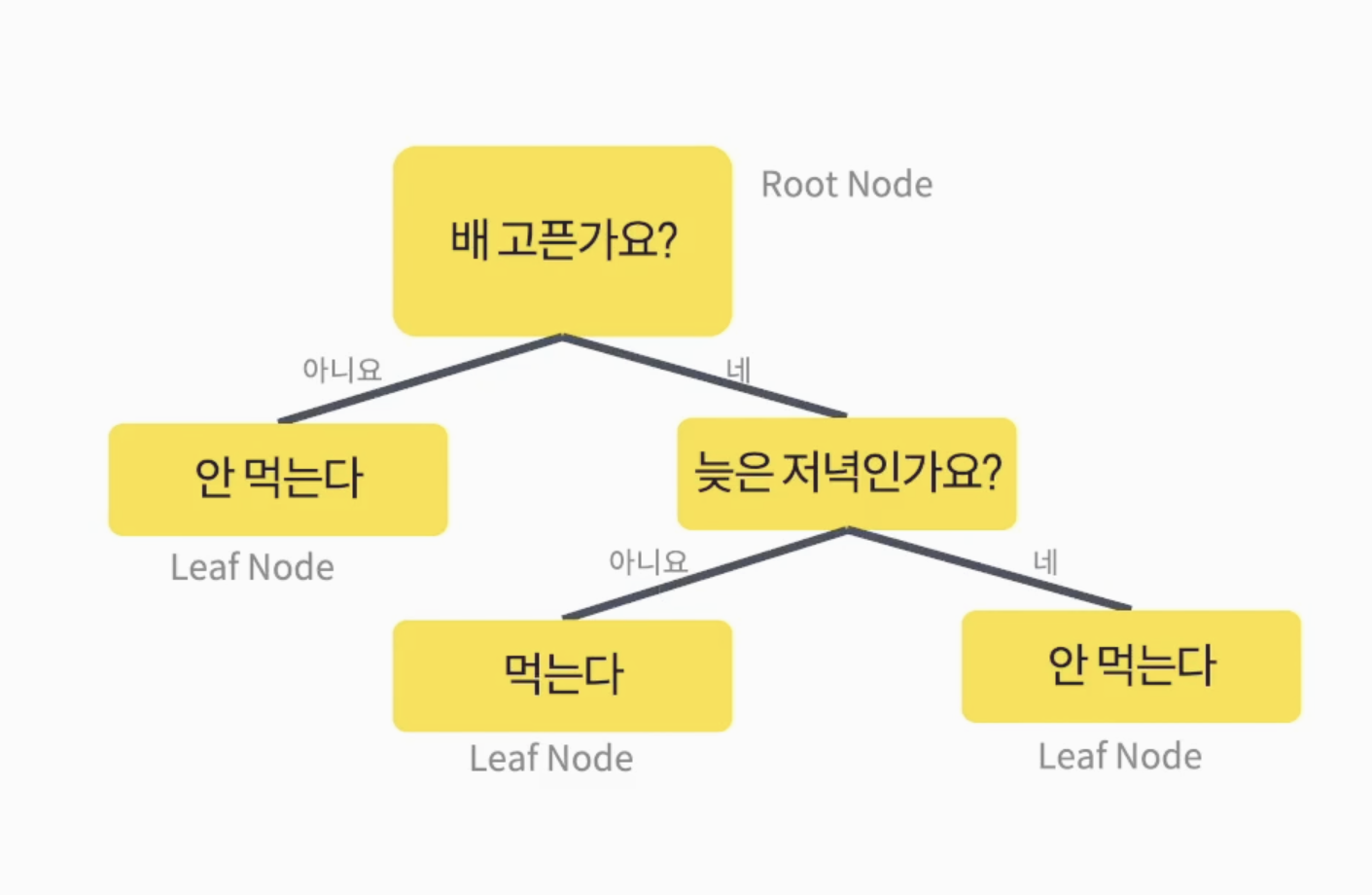
- 위 그림과 같이 Tree 형태로 구성되어 있는 알고리즘
- 과대적합(오버피팅) 되기 쉬운 알고리즘
- 정보이득이 최대가 되는 특성을 나누는 기준(불순도 측정기준)은 'gini'와 'entropy' 사용
- 데이터가 한 종류면 0, 서로 다른 데이터의 비율이 비슷하면 1에 가까움
- 정보이득의 최대는 (1-불순도) 불순도가 낮아지는 값을 찾아 가는 것!
1) 활용 해보기
- 데이터 불러오기 (유방암 data load)
from sklearn.datasets import load_breast_cancer- 데이터 셋 생성하기
def make_dataset():
iris = load_breast_cancer() # data 변수에 저장
#데이터프레임화(pandas)
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
df['target'] = iris.target # target 열 생성 후 target 값 대입
x_train, y_train, x_test, y_test = train_test_split(df.drop('target',axis=1), df['target'], test_size=0.5, random_state=1004) # target 열 생성 후 iris에 저장, 열 삭제 후 target 값 반환
return x_train, x_test, y_train, y_test
x_train, x_test, y_train, y_test = make_dataset()- 의사결정나무 (DicisionTreeClassifier)
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(random_state=0)
model.fit(x_train, y_train)
pred = model.predict(x_test)
accuracy_score(y_test, pred)- 의사결정나무 하이퍼파라미터
성능을 조율하기 위한 조건들(튜닝)
항상 기본값으로 설정 되어 있다- criterion(기본값 gini) : 불순도 지표(또는 엔트로피 불순도 entropy)
- max_depth(기본값 None) : 최대 한도 깊이, 오버피팅을 방지 (차원에서 z축)
- min_samples_split(기본값 2) : 자식 노드를 갖기 위한 최소한의 데이터 수(가임 가능한 부모 수 늘리기)
- min_samples_leaf(기본값 1) : 리프 노드가 되기 위한 최소 샘플 수
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(
max_depth=3, # 하이퍼 파라미터로 제한하기
min_samples_leaf=2, # 하이퍼 파라미터 제한하기2
criterion='entropy', # 하이퍼 파라미터 제한하기3
min_samples_split=5, # 하이퍼 파라미터 제한하기4
random_state=0)
model.fit(x_train, y_train)
pred = model.predict(x_test)
accuracy_score(y_test, pred)2. 랜덤포레스트 (RandomForest)
- 지도학습 알고리즘 (분류,회귀)
- 의사결정나무의 앙상블 (여러 트리들의 모임)
- 성능이 좋음 (과대적합 가능성 낮음)
- 부트스트랩 샘플링 (데이터셋 중복 허용)
- 최종 다수결 투표 (voting) - 모델들의 투표로 의사결정
- 앙상블
* 배깅 : 같은 알고리즘으로 여러 모델을 만들어 분류 (RandomForest)- 부스팅 : 학습과 예측을 하면서 가중치 반영 (xgboost)
- 랜덤포레스트 import
from sklearn.ensemble import RandomForestClassfier
model = RandomForestClassfier(random_state=0)
model.fit(x_train, y_train)
pred = model.predict(x_test)
accuracy_score(y_test, pred)- 랜덤 포레스트 하이퍼 파라미터
* n_estimators(기본값 100) : 트리의 수- criterion(기본값 gini) : 불순도 지표
- max_depth(기본값 None) : 최대 한도 깊이
- min_samples_split(기본값 2) : 자식 노드를 갖기 위한 최소한의 데이터 수
- min_samples_leaf(기본값 1) : 리프 노드가 되기 위한 최소 샘플 수
from sklearn.ensemble import RandomForestClassfier
model = RandomForestClassfier(
max_depth=3, # 하이퍼파라미터 1
n_estimators=200, # 하이퍼파라미터 2
min_samples_split=5,# 하이퍼파라미터 3
random_state=0) # 하이퍼파라미터 4
model.fit(x_train, y_train)
pred = model.predict(x_test)
accuracy_score(y_test, pred)
# 0.94736842~ + 하이퍼파라미터 (검증값 파라미터와 기록 해두면서 하면 비교하기 좋다!)3. xgboost
- eXtreme Gradient Boosting
- 부스팅(앙상블) 기반의 알고리즘
- 트리 앙상블 중 성능이 좋은 알고리즘
- 캐글(글로벌 AI 경진대회) 뛰어난 성능을 보이면서 인기 좋아짐
4. 교차검증 (CrossValidation: CV)
5. 평가
비전공자지만 밑바닥부터 공격적으로 공부중입니다! 공부 해온 것들 정리해보고 있습니다. 잘못 된 부분 있으면 알려주세요~ 서로 공유 하고 싶습니다