1. Attention의 기본 개념
Attention은 입력 데이터 중에서 가장 중요한 정보를 선택적으로 집중하여 학습하는 메커니즘입니다.
기존 RNN, CNN과 다르게 모든 입력을 동시에 고려하며, 유의미한 관계를 학습할 수 있습니다.
(1) 정보 보존과 변환

- 입력 데이터(텐서)는 가중치 행렬 W 를 통과하면서 변환됩니다.
- 변환이 일어나더라도 기본적인 정보는 유지되며, 학습된 방식으로 조정됩니다.
- Query, Key, Value의 개념을 활용하여 가장 중요한 정보에 집중할 수 있습니다.
2. Weighted Sum의 개념
Weighted Sum은 Attention에서 핵심적인 개념입니다. 이를 통해 특정 정보에 집중하고, 불필요한 정보를 줄입니다.
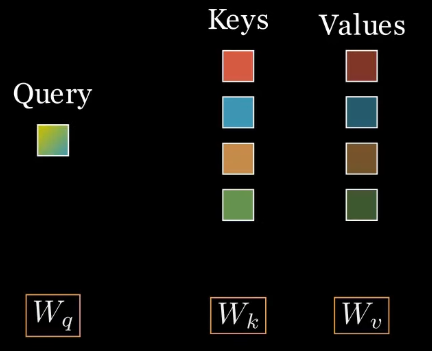
- 쿼리(Query) : 특정한 정보를 가진 하나의 텐서
- 키(Keys) : 서로 다른 정보를 가진 텐서들
- 값(Values) : 각 키에 연관된 정보
쿼리(Query)와 키(Key) 간의 내적(dot product)을 수행하여, 쿼리와 얼마나 연관된 값(Value)인지 측정합니다.
(1) Query와 Key의 내적
쿼리(Query)와 키(Key)의 내적(dot product)을 통해 유사도를 계산합니다.
- 내적 결과가 크면 → Query와 Key가 유사함
- 내적 결과가 작으면 → Query와 Key의 연관성이 낮음
그러나 내적 결과는 다음과 같은 문제를 가집니다.
- 음수일 수도 있음
- 합이 1이 아님 (즉, 확률적 해석이 어려움)
(2) Softmax로 가중치 정규화
이 문제를 해결하기 위해 softmax 함수를 사용합니다.
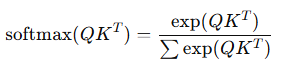

- 지수 함수 exp(x) 를 사용하면 내적 결과를 양수로 변환
- 정규화를 위해 모든 가중치 합이 1이 되도록 조정
이렇게 하면 Query와 Key의 연관성을 확률처럼 다룰 수 있습니다.
3. Attention을 통한 정보 추출
(1) Weighted Sum 결과의 정보성
- Softmax 결과를 사용해 Value를 가중합하면 최종적인 Attention 결과를 얻게 됩니다.
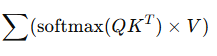
- 결과는 Key 정보들의 가중 합
- 하지만 Query가 Key와 얼마나 연관되는지에 따라 결정되므로, 간접적으로 Query의 정보도 반영됨
4. Positional Encoding
Transformer 모델은 CNN이나 RNN과 달리 순차적인 정보 처리를 하지 않는다. 따라서 문장 내에서 단어의 순서 정보를 모델이 인식할 수 있도록 Positional Encoding(위치 인코딩)을 추가해야 한다.
✅ 왜 필요한가?
Transformer는 입력 문장을 한 번에 병렬 처리하기 때문에 단어의 위치 정보가 사라짐.
단어의 순서를 모델이 학습할 수 있도록 추가적인 위치 정보(encoding)를 부여해야 함.
✅ 어떻게 적용하는가?
입력된 단어 임베딩 벡터에 Positional Encoding 벡터를 더하는 방식으로 적용.
대표적으로 Sine(사인)과 Cosine(코사인) 함수 기반의 위치 인코딩이 사용됨.
✅ 수식 (Sine & Cosine 기반)
Positional Encoding의 각 차원값은 특정 주기의 사인/코사인 함수로 정의됨.

✅ 특징
사인/코사인 함수를 사용하여 각 위치마다 고유한 인코딩 값을 생성.
멀리 떨어진 단어와 가까운 단어의 위치 관계를 유지.
인코딩 값끼리 유사한 패턴을 가지므로 내삽(Interpolation) 가능.
5. Self Attention
Self-Attention은 입력 문장의 각 단어가 문장 내 다른 단어들과 얼마나 관련이 있는지를 계산하는 메커니즘이다.
Transformer의 핵심 아이디어이며, RNN 없이 문맥 정보를 효과적으로 학습하는 데 도움을 준다.
✅ 왜 필요한가?
RNN은 순차적으로 정보를 처리하여 병렬 연산이 어렵고 긴 문장에서 기억 손실(장기 의존성 문제)이 발생.
CNN은 지역적인 패턴만 학습하여 멀리 떨어진 단어 간 관계를 인식하기 어려움.
Self-Attention을 사용하면 모든 단어가 서로를 참고하여 문맥을 반영할 수 있음.
✅ 어떻게 동작하는가?
Self-Attention은 주어진 입력 벡터
𝑋
X에 대해 Query(Q), Key(K), Value(V) 세 가지 벡터를 생성하여, 단어들 간의 유사도를 계산한 후 새로운 가중치로 값을 변환한다.

Transformer의 동작 및 학습 과정
🔷 1. Transformer의 기본 동작
Transformer는 Encoder-Decoder 구조를 가지며, 입력 문장을 인코딩한 후 이를 기반으로 출력 문장을 생성한다.
이를 통해 문장 번역, 문장 생성, 요약, 질의응답 등 다양한 NLP 작업을 수행할 수 있다.
🏗 Transformer 전체 구조
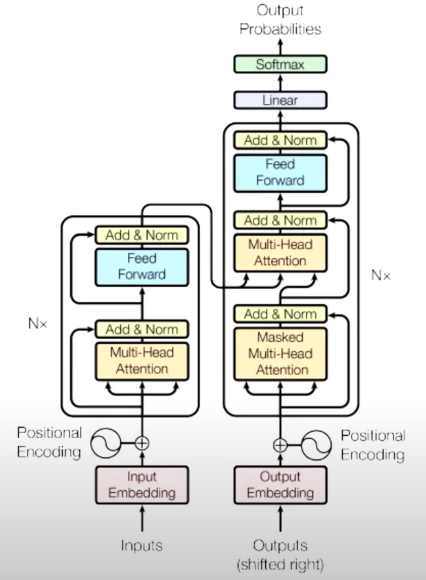
- Encoder: 입력 문장을 벡터로 변환 (문맥 정보를 학습)
- Decoder: 인코딩된 정보를 바탕으로 단어를 하나씩 생성
- Self-Attention: 문장 내 단어 간의 연관성을 학습
- Positional Encoding: 문장의 순서 정보를 반영
- Feed Forward Network: 추가적인 변환 및 학습
🔷 2. Encoder & Decoder 동작 방식
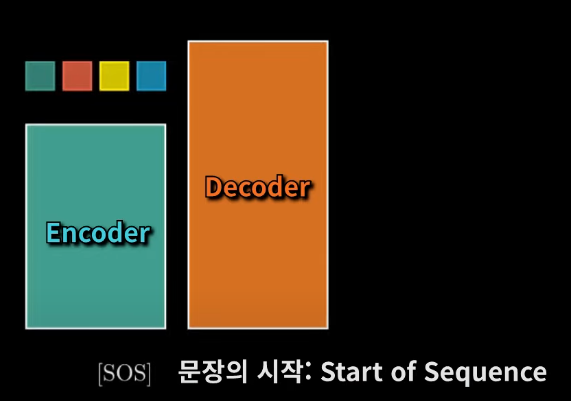
- Encoder 동작 과정
1️⃣ 입력 문장 처리
단어를 임베딩(Embedding) 벡터로 변환
Positional Encoding 추가하여 위치 정보 보완
2️⃣ Self-Attention 적용
문장 내에서 각 단어가 다른 단어들과 얼마나 관련 있는지 계산
각 단어의 문맥을 반영한 새로운 벡터 생성
3️⃣ Feed Forward Network (FFN)
비선형 변환을 거쳐 더 깊은 표현 학습
4️⃣ N번 반복 (Multi-Layer Encoder)
여러 개의 Encoder Layer를 쌓아 깊이 있는 표현 학습
- Decoder 동작 과정
1️⃣ 이전까지 예측된 단어를 입력으로 받음
2️⃣ Masked Self-Attention 적용
아직 예측되지 않은 단어는 가려서(Mask) 사용하지 않도록 함
3️⃣ Encoder-Decoder Attention
Encoder의 출력과 함께 Attention을 수행하여 적절한 단어를 예측
4️⃣ FFN 적용 후 단어 예측
Softmax 함수를 사용해 가장 확률이 높은 단어를 선택
🔷 3. Masking (마스킹)
Masking은 Transformer에서 예측되지 않은 단어가 예측 과정에 영향을 주지 않도록 차단하는 기법이다.
🔹 Padding Mask (패딩 마스크)
- ✅ 문장에서 패딩된 토큰(예: [PAD])을 연산에서 제외하기 위해 사용됨
✅ Self-Attention 연산 시, 의미 없는 패딩 값이 영향을 주지 않도록 마스킹
🔹 Look-Ahead Mask (미래 단어 마스킹)
- ✅ Decoder가 아직 예측되지 않은 미래 단어를 보지 않도록 차단
✅ Self-Attention에서 단어를 예측할 때 과거 단어들만 참고하도록 보장
✅ Decoder에서 단어를 하나씩 생성하는 방식과 잘 맞음
🛑 왜 필요한가?
Transformer는 한 번에 모든 단어를 처리하지만, 번역 등의 작업에서는 단어를 순차적으로 예측해야 하기 때문에 미래 단어를 사용하면 안 됨!
🔷 4. Transformer의 응용 (Encoder-Only vs. Decoder-Only)
Transformer의 구조에서 Encoder 또는 Decoder를 일부만 사용하여 다양한 모델이 탄생함.
🔹 BERT (Encoder-Only)
- ✅ Transformer의 Encoder 부분만 사용
✅ 입력 문장의 전체적인 문맥을 학습하는 데 특화됨
✅ MLM (Masked Language Model): 문장에서 일부 단어를 가리고 예측
✅ 응용 예시: 문장 이해, 질의응답, 문서 분류, 감성 분석 등
🔹 GPT (Decoder-Only)
- ✅ Transformer의 Decoder 부분만 사용
✅ 입력 문장의 다음 단어를 예측하는 방식으로 학습
✅ Auto-Regressive 방식: 이전 단어들을 참고하여 다음 단어를 예측
✅ 응용 예시: 텍스트 생성, 대화형 AI, 소설 작성, 코드 자동 생성
🔷 5. Transformer 기반 번역 과정 예시
📌 예제: "나는 사과를 좋아한다." → "I like apples."
1️⃣ Encoder 처리
- "나는 사과를 좋아한다." → [임베딩] → [Positional Encoding 추가]
- Self-Attention을 통해 단어 간 관계를 학습
- Feed Forward Network를 거쳐 문맥 정보가 반영된 벡터 출력
2️⃣ Decoder 예측 과정
- 첫 단어 [START] 입력 → "I" 예측
- "I"를 입력으로 넣고 → "like" 예측
- "I like"를 입력으로 넣고 → "apples" 예측
- "I like apples." 완성
🔥 Look-Ahead Masking이 적용되어 아직 예측되지 않은 단어는 보지 않도록 한다.
