Contextual Transformer Networks for Visual Recognition
Abstract
Transformer와 자체-어텐션(self-attention) 기법은 자연어 처리(NLP) 분야에서 혁신적인 발전을 이뤄냈으며, 최근에는 컴퓨터 비전(CV)에서도 Transformer 스타일의 아키텍처가 등장하여 경쟁력 있는 성능을 보이고 있습니다.
하지만 대부분의 기존 Transformer 기반 모델들은 2D 피처 맵(feature map)에서 각 공간적 위치에 대해 독립적인 쿼리(query)와 키(key) 쌍을 사용하여 어텐션 행렬을 생성합니다. 그러나 이러한 방식은 이웃하는 키들 간의 풍부한 문맥적 정보(contextual information) 를 충분히 활용하지 못하는 한계가 있습니다.
이 논문에서는 Contextual Transformer(CoT) 블록이라는 새로운 Transformer 스타일의 모듈을 제안합니다. CoT 블록은 입력 키들의 문맥적 정보를 충분히 활용하여 동적 어텐션 행렬을 학습하고, 이를 통해 더욱 강력한 시각적 표현 능력을 갖춘 모델을 설계하는 것이 목표입니다.
INTRODUCTION
1.1
CNN(예: ResNet)은 지역적 특징을 잘 학습하지만, 장거리 의존성을 모델링하는 데 한계가 있음.
ViT와 DETR은 Transformer의 자체-어텐션(Self-Attention) 을 이용하여 이미지의 전역적인(long-range) 관계를 더 효과적으로 학습하지만, 연산량이 많고 대량의 데이터가 필요한 단점이 있음.
이 논문에서는 CNN과 Transformer의 장점을 결합하는 연구 흐름을 설명하고 있으며, 기존의 ViT나 DETR과 같은 Transformer 기반 모델이 어떻게 CNN과 통합되어 발전하고 있는지를 논의한다. 특히, 기존 모델들이 독립적인 쿼리-키(query-key) 상호작용만 고려하여 이웃하는 키 간의 문맥(contextual information)을 활용하지 못하는 문제를 지적한다.
이 문제를 해결하기 위해 새로운 "Contextual Transformer(CoT) 블록" 을 제안하며, CNN의 구조를 유지하면서도 Transformer 스타일의 장거리 의존성 학습을 강화하는 방식을 연구한다.
1.2
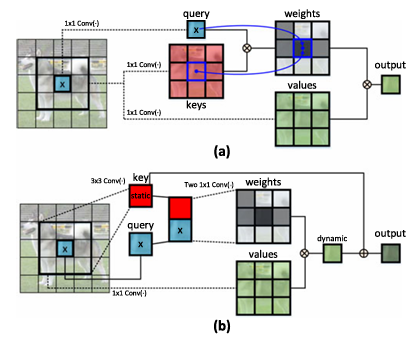
📌 CoT 블록 (Contextual Transformer Block) 개념 정리
1. 기존 Transformer의 한계
기존 Transformer의 자체-어텐션(Self-Attention) 은 각 쿼리(Query)와 키(Key) 간의 독립적인 관계만 고려함.
하지만, 이웃한 키들 사이의 문맥(Contextual Information)을 충분히 활용하지 못하는 문제가 있음.
결과적으로 국소적인(Local) 특징을 잘 반영하지 못하고, 공간적 연관성 부족 → 이미지의 문맥적 정보 학습이 어려움.
2. CoT 블록의 핵심 아이디어
✅ Transformer의 강점 (전역적 특징 학습) + CNN의 강점 (지역적 문맥 활용) → 둘을 결합하여 더욱 강력한 표현 학습
✅ 3×3 컨볼루션을 사용하여 키(Key)들의 문맥 정보를 포함한 표현 생성
✅ 기존 방식처럼 쿼리(Query)와 키(Key)를 단순 매칭하지 않고, 이웃한 키들의 정보를 포함하여 어텐션 수행
✅ 정적인 문맥(Static Context) + 동적인 문맥(Dynamic Context)을 결합하여 최종적인 강력한 표현 학습
3. CoT 블록의 동작 과정 (그림 1(b) 기반 설명)
1️⃣ 이웃한 키들의 문맥 정보 학습 (3×3 컨볼루션 사용)
기존 Transformer는 키(Key)를 독립적으로 사용하지만, CoT 블록은 3×3 컨볼루션을 통해 이웃한 키들의 정보까지 포함하는 새로운 키(Contextualized Key)를 생성
이 값을 정적인 문맥(Static Context) 으로 간주
2️⃣ 쿼리(Query)와 문맥 포함 키(Contextualized Key) 결합
기존 쿼리(Query)와 새롭게 생성한 문맥 포함 키를 결합(Concatenation)
3️⃣ 어텐션 학습 (두 개의 1×1 컨볼루션 사용)
결합된 특징을 두 개의 1×1 컨볼루션을 거쳐 어텐션 행렬(Attention Matrix) 학습
정적인 문맥 정보를 활용하여 더욱 정교한 어텐션 학습
4️⃣ 어텐션 행렬을 활용하여 최종 출력 생성
학습된 어텐션 행렬을 사용하여 입력 값(Values)들을 종합(Aggregation)
결과적으로 정적인 문맥(Static Context) + 동적인 문맥(Dynamic Context)을 모두 반영한 최종 출력 생성
4. CoT 블록의 장점
✅ Transformer의 장거리(Long-Range) 학습 능력 + CNN의 지역적(Local) 문맥 활용 능력 결합
✅ 기존 Transformer보다 더 정교하고 문맥적인 특징 학습 가능
✅ 이웃한 픽셀 간의 공간적 관계를 고려하여 성능 향상
✅ 별도의 추가적인 문맥 추출 과정 없이 하나의 블록 안에서 해결 → 효율적인 구조
📌 한 문장으로 요약하면?
"CoT 블록은 Transformer의 자체-어텐션 방식에 CNN의 지역적 문맥 정보 활용을 결합하여, 정적 & 동적 문맥을 동시에 학습하는 새로운 블록이다."
🔥 기존 Transformer보다 더욱 강력한 시각적 표현 학습이 가능해짐!
1.3
📌 CoTNet의 개념과 성능 요약
1. CoTNet이란?
CoT 블록을 기존 ResNet의 3×3 컨볼루션 대신 사용하여 만든 새로운 네트워크(CoTNet)
파라미터 수(Parameters)와 연산량(FLOP) 증가 없이 적용 가능
ResNet 구조와 호환 가능 → 기존 모델을 쉽게 CoTNet으로 변환 가능
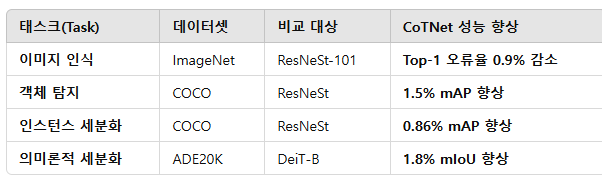
2. CoTNet의 성능 (기존 SOTA 모델 대비 향상 효과)
3. CoTNet의 장점
✅ 기존 ResNet 구조를 간단히 업그레이드 가능 (3×3 컨볼루션을 CoT 블록으로 교체)
✅ 추가적인 연산량 없이 성능 향상 가능
✅ 다양한 컴퓨터 비전 작업에서 최신 모델보다 더 좋은 성능을 보임
✅ Transformer 스타일의 장점(전역적 관계 학습) + CNN 스타일의 장점(지역적 문맥 활용) 결합
