2. RELATEDWORK
📌 2.1 컨볼루션 네트워크(ConvNet) 정리
1. ConvNet의 발전 과정
✅ 초기 모델들은 층을 깊게 쌓는 방식으로 성능을 향상
AlexNet (8층) → VGG (16층) → GoogleNet (22층) → ResNet (152층)
✅ 이후, ConvNet 아키텍처의 성능을 강화하기 위해 다양한 혁신적인 기법들 등장

📌 2.2 비전(컴퓨터 비전)에서의 자체-어텐션(Self-Attention in Vision) 정리
1. 자체-어텐션이 비전에 적용된 배경
Transformer의 자체-어텐션(Self-Attention)이 NLP 분야에서 뛰어난 성과를 거두면서,
연구 커뮤니티는 이를 컴퓨터 비전(CV)에도 적용하려는 시도를 시작함.
자체-어텐션의 원래 목적: NLP에서 장거리 의존성(Long-Range Dependency)을 학습하는 것.
비전에서의 적용 방식: 이미지의 서로 다른 공간적 위치에 대해 자체-어텐션을 수행.
2. 비전에서의 자체-어텐션 적용 방식 & 연구 흐름
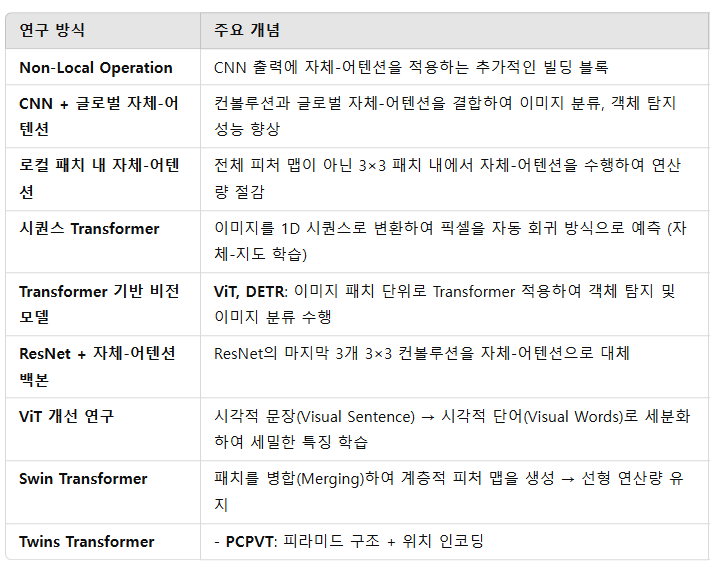
3. 주요 결론
✅ 초기에는 CNN 기반 모델에 자체-어텐션을 추가하는 방식이 많았음.
✅ 점차적으로 순수 Transformer 기반 모델(ViT, DETR)이 등장하면서 CNN을 대체하는 연구로 발전.
✅ Swin Transformer, Twins Transformer, XCA와 같은 연구들은 연산량 최적화 & 성능 향상을 목표로 개선됨.
✅ 최근에는 CNN 없이 Transformer만으로 강력한 시각적 표현 학습이 가능해지는 방향으로 연구가 진행 중.
📌 2.3 Summary
우리는 비전 백본(Vision Backbone) 아키텍처 설계를 위해 자체-어텐션(Self-Attention)을 탐구하는 것에 초점을 맞춘다.
대부분의 기존 기술들은 전통적인 자체-어텐션을 직접 활용하지만, 이웃한 키들 간의 풍부한 문맥(Context)을 명확하게 모델링하는 것을 간과한다.
반면, 우리의 Contextual Transformer(CoT) 블록은 키들 간의 문맥 추출(Context Mining)과 피처 맵(Feature Map) 상의 자체-어텐션(Self-Attention) 학습을 하나의 아키텍처로 통합하면서도, 적절한 파라미터 예산(Parameter Budget) 을 유지할 수 있도록 설계되었다.
3. OURAPPROACH
1. CoT 블록의 개념
- 기존 Transformer의 자체-어텐션(Self-Attention) 은 각 쿼리(Query)와 개별 키(Key) 간의 관계만 고려함.
- 하지만 이웃한 키들 간의 문맥적 정보(Contextual Information)를 충분히 활용하지 못하는 한계가 있음.
- CoT 블록은 자체-어텐션 학습을 강화하기 위해 문맥적 정보까지 반영하여 네트워크의 표현력을 향상시킴.
CoT 블록의 특징
✅ 기존 3×3 컨볼루션을 CoT 블록으로 대체하여 CNN 구조를 유지하면서도 Transformer의 장점을 활용 가능
✅ 이를 통해 Contextual Transformer Networks(CoTNet & CoTNeXt) 를 제안
- CoTNet: ResNet 기반
- CoTNeXt: ResNeXt 기반
3.1 Multi-Head Self-Attention in Vision Backbones
CoT 블록에서 확장 가능한 다중 헤드 자체-어텐션(Multi-Head Self-Attention) 을 사용하며, 기존 Transformer와 차별화된 문맥 정보(Contextual Information) 학습 방식을 적용한다.
📌 (1) Self-Attention Block (Conventional Self-Attention)
✅ 기존 Transformer에서 사용되는 전형적인 자체-어텐션(Self-Attention) 방식
✅ 쿼리(Query), 키(Key), 값(Value)를 생성하고, Softmax를 이용하여 어텐션 행렬을 학습
✅ 전역(Global) 관계를 학습할 수 있지만, 키(Key)들 간의 문맥 정보(Context)는 활용하지 않음
🔹 기존 Self-Attention의 연산 과정
-
(1) 쿼리(Q), 키(K), 값(V) 변환
- 입력 2D 피처 맵 X (크기: H×W×C)
- 1×1 컨볼루션을 사용하여 쿼리(Q), 키(K), 값(V)로 변환
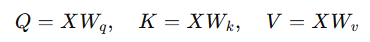
-
(2) 지역적 관계 행렬(Local Relation Matrix) 생성
로컬- k×k 그리드에서 쿼리-키 간 관계를 측정
- 각 쿼리는 주변 키들과 비교하여 문맥 정보 학습
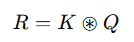
- Ch: 헤드(Head) 개수
- ⊛: 로컬 행렬 곱셈(Local Matrix Multiplication)
- R(i): 각 공간적 위치 i 에서의 k×k×Ch 차원의 벡터
-
(3) 위치 정보(Position Information) 추가
- 기존 Transformer에는 위치 정보가 부족 → 상대적 위치 임베딩(Relative Position Embedding) 추가
- 기존 관계 행렬에 위치 정보 P 를 추가하여 보강
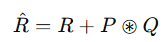
- 그리드 내 위치 정보 반영
- 모든 헤드(Ch)에서 공유됨
-
(4) 어텐션 가중치(Attention Weights) 계산
- 어텐션 행렬을 얻기 위해 Softmax 정규화 수 행
- k×k 크기의 로컬(Local) 어텐션 행렬 생성
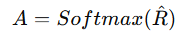
-
(5) 최종 출력 계산
- 값(Value)V 와 어텐션 행렬 A 를 곱하여 최종 출력 생성
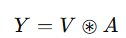
- 각 헤드의 결과를 종합하여 최종 출력 Y 를 생성
- 최종 출력 Y 는 모든 헤드에서 집계된 피처 맵을 연결(Concatenation)하여 생성
- 값(Value)V 와 어텐션 행렬 A 를 곱하여 최종 출력 생성
📌 (2) CoT Block (Contextual Transformer Block)
✅ Self-Attention을 개선하여, 키(Key)들 간의 문맥 정보(Context)를 활용할 수 있도록 설계된 블록
✅ 키(Key) 자체를 문맥화(Contextualized)하여 활용하며, Softmax 없이 어텐션 행렬을 학습
✅ CNN과 Transformer의 장점을 결합한 하이브리드 모델
🔹 CoT 블록의 연산 과정
-
(1) 정적 문맥 표현(Static Context Representation) K1생성
- 입력 2D 피처 맵 X (크기: H×W×C)
- 기존 Self-Attention에서는 1×1 컨볼루션을 사용하여 키(Key)를 변환하지만,
- CoT 블록에서는 k×k 컨볼루션을 사용하여 주변 문맥을 포함한 키(Key) K1을 생성
- K1은 한 번 학습되면 변하지 않는 "정적 문맥 표현"
-
(2) 어텐션 행렬 A 생성
- 쿼리(Query)와 문맥화된 키(Key) K1를 결합(Concat)하여 어텐션 학습
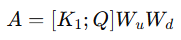
- 첫 번째 컨볼루션 𝑊𝑢는 ReLU 활성화 함수 적용 (비선형 변환)
- 두 번째 컨볼루션 𝑊𝑑는 활성화 함수 없이 출력 (최종 어텐션 행렬 생성)
- Softmax 없이 자체 학습
- 쿼리(Query)와 문맥화된 키(Key) K1를 결합(Concat)하여 어텐션 학습
-
(3) 동적 문맥 표현(Dynamic Context Representation) 𝐾2생성
- 문맥화된 어텐션 행렬 𝐴를 이용하여 값(Value) 𝑉를 종합(Aggregation)
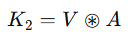
- 기존 Self-Attention과 다르게, 어텐션 행렬에 문맥 정보가 포함됨
- 문맥화된 어텐션 행렬 𝐴를 이용하여 값(Value) 𝑉를 종합(Aggregation)
-
(4) 최종 출력 𝑌생성
- 정적 문맥 𝐾1과 동적 문맥 𝐾2를 결합하여 최종 출력 생성
- 글로벌 평균 풀링(GAP)과 소프트 어텐션을 활용하여 최적의 출력을 생성
구조적 차이: Self-Attention vs. CoT Block
(a) 기존 Self-Attention Block (Conventional Self-Attention)
-
쿼리(Query), 키(Key), 값(Value) 생성 → 1×1 컨볼루션 사용
-
쿼리-키(Q⋅K^T ) 비교 후 Softmax 적용
-
값(Value) V 와 어텐션 행렬 곱해서 최종 출력 생성
-
기존 CNN과 다르게 전역(전체) 관계 학습 가능
-
하지만 키(Key)들 간의 문맥 정보를 학습하지 않음!
-
📌 한계:
❌ 각 키(Key)는 독립적으로 사용됨 → 주변 문맥 정보 반영 ❌
❌ Softmax 연산이 필요 → 연산량 증가
❌ CNN처럼 지역적(Local) 관계를 반영하는 능력이 부족
Self-Attention에서는 "Position + Query" 연산을 통해 위치 정보를 보완하지만, 여전히 키(Key)들 간의 문맥 정보(Context)는 학습하지 않음!
(b) CoT Block (Contextual Transformer Block)
-
쿼리(Query), 키(Key), 값(Value) 생성 → 기존과 다르게 키(Key) 변환 시 k×k 컨볼루션 사용
-
쿼리(Query)와 키(Key) 결합 (Concat) 후 1×1 컨볼루션을 거쳐 어텐션 행렬 생성
-
Softmax 없이 문맥 기반 학습을 수행
-
어텐션 행렬 δ 와 값(Value) V 곱한 후, 원래 키(Key) 정보까지 반영하여 최종 Fusion 수행
-
📌 개선점:
✅ 키(Key)들 간의 문맥 정보 학습 가능 → 기존 Self-Attention 대비 문맥 반영 O
✅ Softmax 연산 없이 자체 학습 가능 → 연산량 감소
✅ CNN과 유사하게 지역적(Local) 관계를 학습 → 더 자연스러운 특징 표현 가능
Contextual Transformer Networks (문맥적 Transformer 네트워크) 정리
✅ CoT 블록은 기존 CNN의 표준 컨볼루션을 대체할 수 있는 Self-Attention 기반의 빌딩 블록
✅ 이를 활용하여 ResNet 및 ResNeXt 같은 기존 CNN 모델을 문맥화된(Self-Attention 기반) 비전 백본으로 강화 가능
✅ CoT 블록을 적용하더라도, 전체적인 파라미터 수와 FLOPs(연산량)를 크게 증가시키지 않도록 설계됨
✅ Table 1 & Table 2에서 ResNet-50과 ResNeXt-50을 기반으로 한 CoTNet-50 및 CoTNeXt-50의 구조를 확인할 수 있음
✅ CoTNet은 ResNet-101과 같은 더 깊은 네트워크에도 확장 가능
📌 ResNet-50 vs. CoTNet-50 & ResNeXt-50 vs. CoTNeXt-50 (표 정리 및 비교 분석)
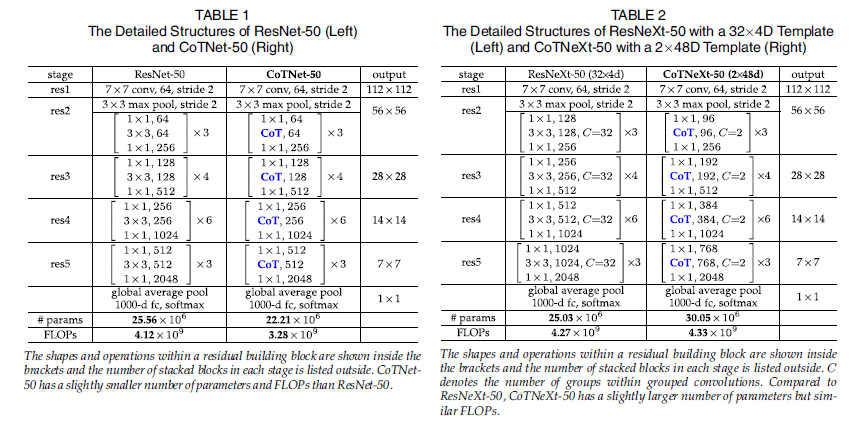
📌 1. Table 1: ResNet-50 vs. CoTNet-50
- 기존 ResNet-50의 모든 3×3 컨볼루션(스테이지 res2, res3, res4, res5)을 CoT 블록으로 직접 교체하여 구축됨.
- CoT 블록은 기존 3×3 컨볼루션과 연산량(Computational Cost)이 유사하므로, CoTNet-50은 ResNet-50과 거의 동일한(혹은 약간 더 적은) 파라미터 수 및 FLOPs를 가짐.
- 즉, 기존 ResNet-50보다 연산량은 거의 동일하면서도, 문맥 정보를 활용한 성능 향상을 기대할 수 있음!
📌 2. Table 2: ResNeXt-50 vs. CoTNeXt-50
- ResNeXt-50의 그룹 컨볼루션(Grouped Convolutions)에서 모든 3×3 컨볼루션을 CoT 블록으로 교체하여 구축됨.
- 그룹 컨볼루션(Grouped Convolution)의 특징:
- 그룹 개수(C 값)가 증가할수록, 각 컨볼루션 커널의 깊이(depth)가 감소 → 연산량이 줄어듦.
- ResNeXt-50에서는 그룹 컨볼루션을 활용하여 계산 비용을 C 배 줄일 수 있음.
- 이를 감안하여, CoTNeXt-50에서는 입력 특징 맵의 크기를 32×4d에서 2×48d로 조정하여,
ResNeXt-50과 유사한 수준의 파라미터 수 및 FLOPs를 유지하도록 설계됨.
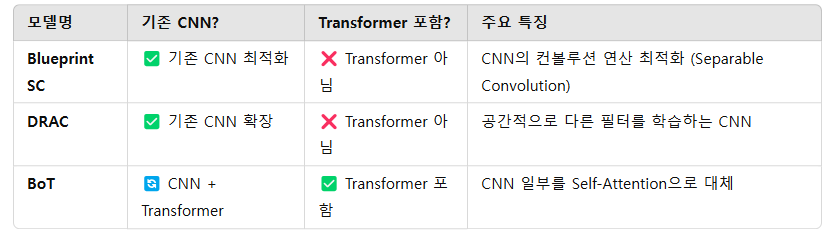
Connections With Previous Vision Backbones
Blueprint Separable Convolution
✅ 1×1 포인트와이즈 + k×k 깊이별 컨볼루션을 활용하여 채널 축소
✅ CoT 블록과 유사한 구조를 가짐
✅ 채널 공유 전략(Channel Sharing Strategy)을 사용하여 효율성 증가
Dynamic Region-Aware Convolution
✅ 1×1 컨볼루션을 사용하여 지역적 특징을 학습
✅ CoT 블록과 유사하게 로컬 어텐션 행렬을 동적으로 생성
✅ 하지만 CoT 블록은 문맥화된 키(Contextualized Key)와 쿼리(Query) 간의 상호작용을 더 적극적으로 활용
Bottleneck Transformer
✅ ResNet 기반 CNN에서 Self-Attention을 추가하는 구조
✅ 하지만 연산량이 높아, 네트워크 일부(최종 세 개의 3×3 컨볼루션)만 Transformer 블록으로 변경 가능
✅ 반면 CoT 블록은 네트워크 전체에서 3×3 컨볼루션을 대체 가능
✅ CoT 블록은 입력 키(Key) 간의 문맥을 활용하여 Self-Attention 학습을 더욱 강화