전체 코드
# 라이브러리 불러오기
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.datasets as datasets
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
# Data Loading
train_data = datasets.MNIST(root="data", train=True, download=True, transform=transforms.ToTensor())
test_data = datasets.MNIST(root="data", train=False, transform=transforms.ToTensor())
train_loader = DataLoader(train_data, batch_size=64, shuffle=True)
test_loader = DataLoader(test_data, batch_size=64, shuffle=False)
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.layers = nn.Sequential(
nn.Linear(28 * 28, 64), nn.ReLU(), nn.Linear(64, 64), nn.ReLU(), nn.Linear(64, 10)
)
def forward(self, x):
x = x.view(x.size(0), -1)
return self.layers(x)
model = MLP()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
for epoch in range(5):
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
print(f"Epoch {epoch}: Loss = {loss.item()}")
correct = 0
total = 0
with torch.no_grad():
for data, target in test_loader:
output = model(data)
_, predicted = torch.max(output.data, 1)
total += target.size(0)
correct += (predicted == target).sum().item()
print(f"Accuracy: {100 * correct / total}%")라이브러리
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.datasets as datasets
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
torch.nn: 신경망을 구성하기 위한 다양한 데이터 구조나 레이어 등이 정의되어 있는 라이브러리
torchvision.datasets: 유명한 데이터셋을 쉽게 불러올 수 있는 라이브러리 (예: MNIST).
torchvision.transforms: 이미지 전처리를 위한 도구.
Data Loading
train_data = datasets.MNIST(root="data", train=True, download=True, transform=transforms.ToTensor())
test_data = datasets.MNIST(root="data", train=False, transform=transforms.ToTensor())MNIST 훈련 데이터와 테스트 데이터를 다운로드, 픽셀 값을 텐서화한다.
여기서 텐서화: 이미지 데이터의 픽셀 값을 텐서 형태로 반환해 파이토치에서 사용할 수 있도록 만든다.
좀 더 구체적으론 MNIST 데이터셋은 28x28의 흑백 이미지이며, 각 픽셀의 값은 0~255의 정수인데, transforms.ToTensor()는 이 픽셀 값을 [0,1] 범위의 부동소수점으로 스케일링해 파이토치 텐서로 변형한다.
- train=True:
학습용 데이터셋을 로드합니다. (60,000개의 샘플) - train=False:
테스트용 데이터셋을 로드합니다. (10,000개의 샘플) - transform=transforms.ToTensor()
이미지를 이미지를 텐서(Tensor)로 변환하는 작업을 수행합니다.
train_loader = DataLoader(train_data, batch_size=64, shuffle=True)
test_loader = DataLoader(test_data, batch_size=64, shuffle=False)데이터를 미니배치로 관리하며, 훈련 데이터를 무작위로 섞는다.
- DataLoader
데이터셋을 배치 크기만큼 나누고, 학습 시 모델에 전달할 수 있도록 준비하는 역할을 합니다. - batch_size=64
한 번에 64개의 샘플을 가져옵니다. - shuffle=True
데이터를 매 에포크(epoch)마다 랜덤하게 섞습니다(학습 효율을 높이기 위함).
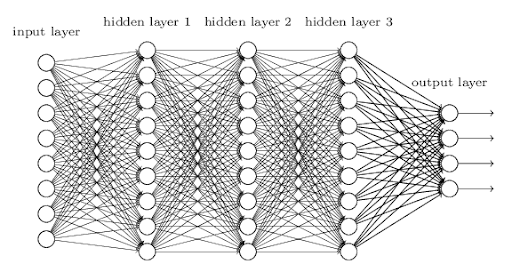
Model(MLP)
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.layers = nn.Sequential(
nn.Linear(28 * 28, 64), nn.ReLU(), nn.Linear(64, 64), nn.ReLU(), nn.Linear(64, 10)
)주어진 입력에 대한 예측 출력과 실제 출력 사이의 차이를 계산하는 손실 함수(loss function)를 사용해 모델을 훈련시키고, 경사 하강법(gradient descent) 알고리즘을 사용해 손실을 최소화하는 방향으로 가중치를 조절한다.
- self.layers
모델의 전체 구조를 정의합니다.- nn.Sequential
여러 레이어를 순차적으로 연결하는 컨테이너.
데이터를 입력하면 각 레이어를 순서대로 통과합니다.
nn.Linear(28 * 28, 64):
입력층에서 은닉층으로 연결.
입력 데이터의 크기가 28×28=784 픽셀(평탄화된 MNIST 이미지)에서 64개의 노드로 변환.n.ReLU():
활성화 함수로, 비선형성을 추가합니다.nn.Linear(64, 64):
첫 번째 은닉층에서 두 번째 은닉층으로 연결.
입력 64개의 특징을 받아 출력도 64개로 생성.nn.ReLU():
비선형 활성화 함수 추가.nn.Linear(64, 10):
마지막 은닉층에서 출력층으로 연결.
출력층:
10개의 노드: MNIST 데이터셋의 클래스(숫자 0~9) 수와 동일.
각 노드는 클래스에 해당하는 점수를 출력.
def forward(self, x):
x = x.view(x.size(0), -1)
return self.layers(x)- x = x.view(x.size(0), -1)
Flatten 작업
view는 텐서의 크기를 변경(reshape)하는 PyTorch 메서드입니다.
x.size(0): 입력 데이터의 첫 번째 차원(배치 크기)을 유지.
-1: 나머지 차원을 자동으로 계산하여 1차원으로 평탄화(Flatten).reason:
MNIST 데이터는 (배치크기,1,28,28) 크기의 4D 텐서로 들어옵니다.
nn.Linear 레이어는 2D 텐서를 입력으로 받으므로, 데이터를 (배치크기,28×28) 형태로 변환해야 합니다.
Loss Function, Gradient Descent
- Loss Function
손실 함수는 모델의 예측과 실제 값 간의 차이를 수치화하는 함수이다. 모델의 학습 목적은 이 손실함수의 값을 최소화하는 것이라고 할 수 있다. - Gradient Descent
경사 하강법은 손실함수의 값을 최소화하기 위한 최적화 알고리즘이다.(함수(오차)가 줄어드는 방향으로 파라미터를 갱신하는 것.)
model = MLP()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)손실 함수는 위에서 본 교차 엔트로피 손실 함수를, 최적화 알고리즘에는 경사하강법의 일종인 Adam을 사용한다.
Training Loop
for epoch in range(5):
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
print(f"Epoch {epoch}: Loss = {loss.item()}")
- 데이터를 배치 단위로 나누어 순차적으로 처리
- 각 비니배치마다 이전에 계산된 그래디언트를 초기화한다.
- 입력 데이터를 모델에 넣어 출력값을 얻는다. 이를 순전파(forward pass)라고 한다.
- 모델의 출력과 실제 값을 비교해 손실을 계산한다. 여기선 교차손실법을 이용한다.
- 손실값에 대한 그래디언트를 입력층으로 역전파한다.
- 계산된 그래디언트를 사용해 모델 파라미터를 업데이트한다. 여기선 Adam 알고리즘을 사용하고 있다.
Evaluation
correct = 0
total = 0
with torch.no_grad():
for data, target in test_loader:
output = model(data)
_, predicted = torch.max(output.data, 1)
total += target.size(0)
correct += (predicted == target).sum().item()
print(f"Accuracy: {100 * correct / total}%")
- 모델 평가에는 그래디언트 계산이 불필요하기 때문에 명시적으로 기능을 꺼준다.
- 데이터 로더에서 테스트 데이터와 실제 값을 미니매치 단위로 가져온다.
- 모델에 데이터를 넣어 출력을 얻는다. 이는 위에서도 봤듯이 순전파 과정이다.
- 모델의 출력은 10개의 클래스에 대한 확률 값으로 나타난다. torch.max는 그중 가장 높은 값을 갖는 클래스의 인덱스를 반환한다. 추가로 '_'는 해당 확률 값을 저장하지만 여기서는 사용되지 않는다.
- 테스트 데이터의 개수를 누적한다
- 모델의 예측과 실제 값이 일치하는 경우의 수를 누적한다.
- 전체 테스트 데이터에 대한 정확도를 출력한다.
