전체 코드
import pandas as pd # 데이터 처리를 위한 라이브러리
import numpy as np # 수학 연산에 강력한 라이브러리리
from sklearn.model_selection import train_test_split # 데이터를 학습용과 테스트용으로 나누기 위한 도구
from sklearn.datasets import fetch_openml # 머신러닝용 데이터셋을 쉽게 불러오기위한 도구
# PyTorch 관련 모듈 (딥러닝 프레임워크)
import torch
from torch import nn, optim # nn: 신경망 구성 도구, optim: 최적화 알고리즘
# nn.Linear(선형 회귀 연산), nn.MSELoss(평균 제곱 오차 손실 함수)
from torch.utils.data import DataLoader, Dataset # 데이터를 신경망에 쉽게 전달하도록 도와주는 도구
import torch.nn.functional as F # 활성화 함수(ReLU 등)와 같은 기능 제공
# 그래프를 그리기 위한 도구(그래프 시각화)
import matplotlib.pyplot as plt
# 보스턴 데이터셋 불러오기
x, y = fetch_openml('boston', version=1, return_X_y=True, as_frame=True)
df = pd.DataFrame(x)
df['Price'] = y # 'Price' 열 추가
# 데이터 확인
print(df.head(10))
# 데이터 전처리
# 모든 데이터를 float 타입으로 변환
X = df.drop('Price', axis=1).astype(float).to_numpy() # X에 포함된 모든 값을 float 타입으로 변환
Y = df['Price'].astype(float).to_numpy().reshape((-1, 1)) # Y도 float 타입으로 변환
# TensorData 정의
class TensorData(Dataset):
def __init__(self, x_data, y_data):
self.x_data = torch.FloatTensor(x_data)
self.y_data = torch.FloatTensor(y_data)
self.len = self.y_data.shape[0]
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
# Train/Test Split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.5)
# x => 입력 데이터
# Y => 출력 데이터
# test_size => 테스트 데이터 비율
# shuffle => 데이터를 섞을지 여부(기본은 True)
trainsets = TensorData(X_train, Y_train)
trainloader = DataLoader(trainsets, batch_size=32, shuffle=True)
testsets = TensorData(X_test, Y_test)
testloader = DataLoader(testsets, batch_size=32, shuffle=False)
class Regressor(nn.Module):
def __init__(self):
super().__init__()
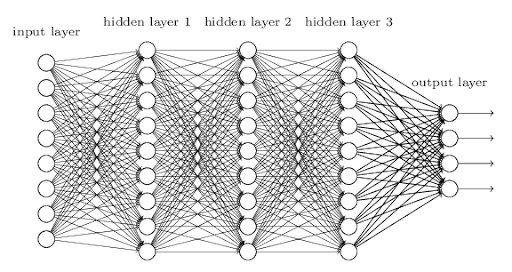
self.fc1 = nn.Linear(13, 50) # 입력층(13개 특징값) -> 첫 번째 은닉층(50개 노드)
self.fc2 = nn.Linear(50, 30) # 첫 번째 은닉층 -> 두 번째 은닉층(30개 노드)
self.fc3 = nn.Linear(30, 1) # 두 번째 은닉층 -> 출력층(1개 값: 집값)
self.dropout = nn.Dropout(0.2) # 과적합 방지를 위한 드롭아웃(20%)
def forward(self, x): # 모델의 연산 순서 정의
x = F.relu(self.fc1(x)) # 첫 번째 레이어 + 활성화 함수(ReLU)
x = self.dropout(F.relu(self.fc2(x))) # 두 번째 레이어 + 드롭아웃 + ReLU
x = F.relu(self.fc3(x)) # 마지막 레이어 + ReLU
return x
model = Regressor()
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=1e-2, weight_decay=1e-7)
# Training loop
ep = 0 # 가장 낮은 손실을 기록한 에포크를 저장할 변수
ls = float("inf") # 초기 손실 값, 비교 기준이 될 매우 높은 값으로 설정
loss_ = [] # 손실 값을 저장할 리스트
n = len(trainloader) # 배치 개수
for epoch in range(200): # 200번 학습
running_loss = 0.0
for data in trainloader: # 데이터 배치 단위로 가져오기
inputs, values = data # 입력값과 출력값 분리
optimizer.zero_grad() # 이전 기울기 초기화
outputs = model(inputs) # 모델에 데이터 입력 -> 예측값 산출
loss = criterion(outputs, values) # 예측값과 실제값 비교 -> 손실 계산
loss.backward() # 손실을 기준으로 역전파 수행
optimizer.step() # 가중치 업데이트
running_loss += loss.item() # 배치 손실 합산
l = running_loss / n # 에포크당 평균 손실 계산
loss_.append(l) # 손실 기록
print(l, ls)
if l < ls:
ls = l
ep = epoch
torch.save({'epoch': ep,
'loss': loss_,
'model': model.state_dict(),
'optimizer': optimizer.state_dict()
}, './models/reg4-1.pt')
print("Finished Training")
# 결과 시각화
plt.plot(loss_)
plt.title("Training Loss")
plt.xlabel("epoch")
plt.savefig("loss.png")
checkpoint = torch.load ('./models/reg4-1.pt', weights_only=True)
model.load_state_dict(checkpoint['model'])
optimizer.load_state_dict(checkpoint['optimizer'])
loss_ = checkpoint['loss']
ep = checkpoint['epoch']
ls = loss_[-1]
print(f"epoch={ep}, loss={ls}")
# RMSE 계산
def rmse(dataloader):
with torch.no_grad():
square_sum = 0
num_instances = 0
model.eval()
for data in dataloader:
inputs, targets = data
outputs = model(inputs)
square_sum += torch.sum((outputs - targets) ** 2).item()
num_instances += len(targets)
model.train()
return np.sqrt(square_sum / num_instances)
train_rmse = rmse(trainloader)
test_rmse = rmse(testloader)
print("Train RMSE: %.5f" % train_rmse)
print("Test RMSE: %.5f" % test_rmse)
라이브러리 불러오기
import pandas as pd # 데이터 처리를 위한 라이브러리
import numpy as np # 수학 연산에 강력한 라이브러리리
from sklearn.model_selection import train_test_split # 데이터를 학습용과 테스트용으로 나누기 위한 도구
from sklearn.datasets import fetch_openml # 머신러닝용 데이터셋을 쉽게 불러오기위한 도구
# PyTorch 관련 모듈 (딥러닝 프레임워크)
import torch
from torch import nn, optim # nn: 신경망 구성 도구, optim: 최적화 알고리즘
# nn.Linear(선형 회귀 연산), nn.MSELoss(평균 제곱 오차 손실 함수)
from torch.utils.data import DataLoader, Dataset # 데이터를 신경망에 쉽게 전달하도록 도와주는 도구
import torch.nn.functional as F # 활성화 함수(ReLU 등)와 같은 기능 제공
# 그래프를 그리기 위한 도구(그래프 시각화)
import matplotlib.pyplot as plt데이터 불러오기
# 보스턴 데이터셋 불러오기
x, y = fetch_openml('boston', version=1, return_X_y=True, as_frame=True)
df = pd.DataFrame(x)
df['Price'] = y # 'Price' 열 추가
# 데이터 확인
print(df.head(10))x, y = fetch_openml('boston', version=1, return_X_y=True, as_frame=True)
- fetch_openml은 OpenML 플랫폼에서 데이터를 다운로드하는 함수입니다.
- 'boston'은 데이터셋의 이름으로, 보스턴 주택 가격 예측 데이터입니다.
- version=1은 데이터셋의 버전을 지정하며, 여기서는 첫 번째 버전을 사용합니다.
- return_x_y=True:
데이터를 두 개의 객체로 반환:
x: 입력 데이터(독립 변수들).
y: 타겟 데이터(종속 변수, 여기서는 주택 가격).- as_frame=True:
데이터를 pandas.DataFrame 형태로 반환.
이 옵션이 없으면 NumPy 배열로 반환됩니다.
df = pd.DataFrame(x)
- x를 pandas.DataFrame 형태로 변환합니다.
- 데이터프레임은 행(row)과 열(column)로 구성된 테이블 형태로, 데이터 조작과 분석이 쉽습니다.
df['Price'] = y
- y(타겟 데이터, 주택 가격)를 데이터프레임 df의 새로운 열로 추가합니다.
열 이름은 'Price'로 지정되며, 이는 모델이 예측해야 하는 종속 변수(타겟 값)입니다
print(df.head(10))
- 데이터프레임 출력
데이터를 numpy 배열로 변환하기(float 타입 변환.)
# 데이터 전처리
# 모든 데이터를 float 타입으로 변환
X = df.drop('Price', axis=1).astype(float).to_numpy() # X에 포함된 모든 값을 float 타입으로 변환
Y = df['Price'].astype(float).to_numpy().reshape((-1, 1)) # Y도 float 타입으로 변환X = df.drop('Price', axis=1).astype(float).to_numpy()
- 데이터프레임 df에서 열 이름이 'Price'인 열을 제거합니다.
제거된 데이터프레임에는 입력 변수(독립 변수)만 남습니다.
axis=1은 열을 기준으로 제거한다는 뜻입니다.- 데이터프레임의 모든 값을 float 타입으로 변환합니다.
- pandas.DataFrame을 numpy.ndarray(NumPy 배열)로 변환합니다.
Y = df['Price'].astype(float).to_numpy().reshape((-1, 1))
- 데이터프레임에서 열 이름이 'Price'인 열을 선택합니다.
- Price는 보스턴 주택 데이터의 타겟 변수(종속 변수)로, 모델이 예측해야 하는 주택 가격입니다.
- 1D 배열을 2D 배열로 변환합니다.
(-1, 1)에서 -1은 배열의 행 개수를 자동으로 결정하고, 1은 열 개수를 의미합니다.
결과적으로 타겟 변수 Y는 (샘플 개수, 1) 형태의 2D 배열이 됩니다.- 2D 배열로 처리하는 이유
N (Batch Size): 샘플의 개수. 한 번에 처리할 데이터의 묶음.
F (Feature Size): 하나의 샘플에서 사용할 특성의 개수.
데이터셋 클래스 정의
class TensorData(Dataset):
def __init__(self, x_data, y_data):
self.x_data = torch.FloatTensor(x_data) # 입력 데이터를 텐서로 변환
self.y_data = torch.FloatTensor(y_data) # 출력 데이터를 텐서로 변환
self.len = self.y_data.shape[0] # 데이터 길이(샘플 개수)
def __getitem__(self, index):
return self.x_data[index], self.y_data[index] # 주어진 인덱스의 데이터 반환
def __len__(self):
return self.len # 데이터셋 길이 반환- def init(self, x_data, y_data):
self.x_data = torch.FloatTensor(x_data) # 입력 데이터를 텐서로 변환
self.y_data = torch.FloatTensor(y_data) # 출력 데이터를 텐서로 변환
self.len = self.y_data.shape[0] # 데이터 길이(샘플 개수)
- init 메서드는 일종의 생성자 역할을 한다.
- torch.FloatTensor로 변환:
PyTorch는 데이터를 텐서(Tensor) 형태로 처리한다.
따라서 numpy 배열(x_data, y_data)을 FloatTensor로 변환한다.
변환된 텐서는 GPU 연산(CUDA)도 가능해진다.- 데이터프레임 → NumPy 배열 → PyTorch 텐서
- def getitem(self, index):
return self.x_data[index], self.y_data[index] # 주어진 인덱스의 데이터 반환
- 이 메서드는 특정 인덱스의 샘플을 반환한다.
- PyTorch의 DataLoader가 TensorData 객체에서 데이터를 로드할 때 호출되며, 작동 방식은 아래와 같다:
self.x_data[index]: 입력 데이터에서 주어진 인덱스(index)에 해당하는 샘플을 반환.
self.y_data[index]: 타겟 데이터에서 주어진 인덱스에 해당하는 값을 반환.
(x, y) 형태로 반환한다. 이때 x는 입력 데이터(특성값), y는 타겟값(예측하려는 값)이다.
- def len(self):
return self.len # 데이터셋 길이 반환
- 이 메서드는 데이터셋의 샘플 개수를 반환한다.
- 파이토치는 데이터 로딩시 반복 횟수를 결정하기 위해 len 을 사용한다.
- 이 구조가 필요한 이유
PyTorch는 데이터셋을 효율적으로 관리하고 모델에 전달하기 위해 Dataset과 DataLoader를 사용한다.
Dataset 클래스:
데이터를 로드하고 특정 인덱스의 샘플을 반환하는 로직을 정의.
DataLoader 클래스:
Dataset에서 정의된 데이터를 배치 단위로 나누고, 무작위로 섞거나 순차적으로 반복하도록 도와줌.
ex)
TensorData 객체 생성:
dataset = TensorData(X_train, Y_train)
DataLoader로 배치 생성:
trainloader = DataLoader(dataset, batch_size=32, shuffle=True)
DataLoader에서 배치를 모델에 전달:
for inputs, targets in trainloader:
outputs = model(inputs) # 모델에 데이터 전달요약
TensorData 클래스의 역할:
데이터를 텐서로 변환하고, Dataset의 기본 구조를 재정의하여 PyTorch 모델과 호환되도록 만든다.
getitem으로 특정 데이터를 가져오고, len으로 데이터셋 크기를 알려준다.
Dataset과 DataLoader는 모델 학습 과정에서 데이터를 효율적으로 관리하는 핵심 요소이다.

학생