Branch prediction & advanced pipeline
MIPS more than bp
1. Delayed Branching 기법
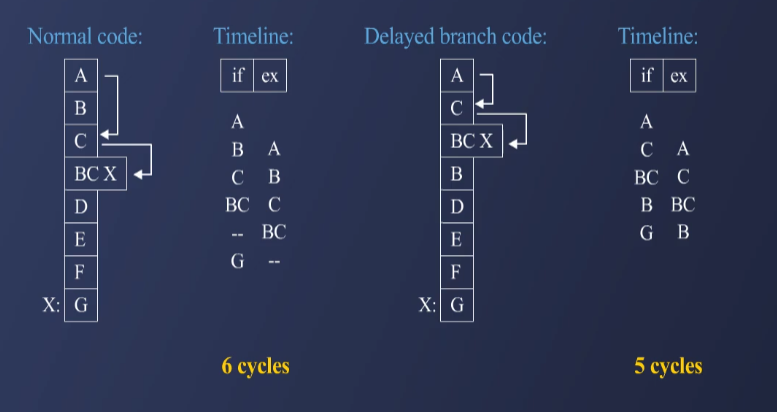
Delayed Branching 기법은 분기 명령어(Branch Instruction)의 실행을 몇 사이클 뒤로 미루는 방식으로, 해당 시간 동안 다른 명령어를 채워넣어 stall을 방지하는 기법이다.
1.1 Delayed Branching 원리
- 분기 명령어 실행 후의 지연 슬롯(Delay Slot)에 반드시 실행되어야 하는 명령어를 배치한다.
- 이를 통해 Pipeline을 stall 없이 채울 수 있어 성능 향상 효과를 얻을 수 있다.
1.2 Delayed Branching의 장점
- Branch 실행 여부와 관계없이 특정 명령어들이 항상 실행되므로, 불필요한 stall을 줄일 수 있다.
- Branch의 execution stage까지 기다릴 필요 없이, 일정한 명령어 실행을 유지할 수 있다.
1.3 Delayed Branching의 단점
- 분기 이후 실행될 명령어를 찾는 과정이 어렵다.
- 컴파일러가 delay slot에 적절한 명령어를 배치해야 하므로, 소프트웨어 최적화가 필요하다.
- 현대적인 프로세서에서는 사용되지 않는 기법이다.
1.4 Delayed Branching with Squashing
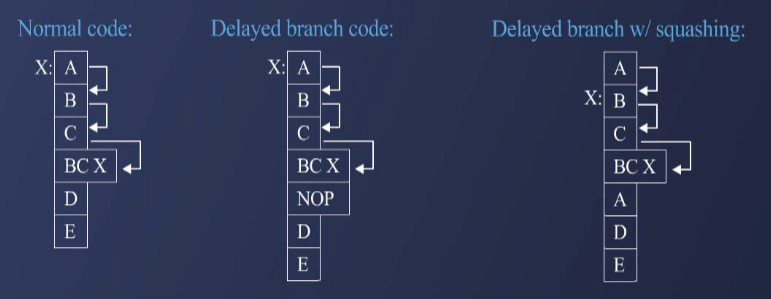
- 일반적인 Delayed Branching에서 NOP(No Operation)를 삽입하는 대신, 실행될 가능성이 높은 명령어를 배치하는 방식이다.
- 분기 방향이 결정되었을 때, 불필요한 명령어를 squashing(삭제)하여 더욱 최적화할 수 있다.
2. Fine-Grained Multithreading 기법
Fine-Grained Multithreading은 Control Dependency와 Data Dependency 문제를 해결하기 위해 여러 개의 실행 가능한 프로그램(스레드)을 하드웨어적으로 배치하여 실행하는 방식이다.
2.1 Fine-Grained Multithreading 원리
- Stall이 발생하는 사이클 동안 다른 프로그램을 실행함으로써, 전체적인 pipeline 사용률을 높인다.
- 여러 개의 프로그램을 번갈아 실행하여, 각 프로그램이 일정한 시간 간격으로 실행될 수 있도록 한다.
2.2 Fine-Grained Multithreading의 장점

- Dependency 체크가 필요 없으며, branch prediction logic을 제거할 수 있다.
- Stall 없이 모든 pipeline 사이클을 유용한 명령어 실행에 활용할 수 있다.
2.3 Fine-Grained Multithreading의 단점
- 단일 스레드(single thread) 성능이 저하될 수 있다.
- 매 사이클마다 다른 프로그램의 register 값을 교체해야 하므로, 추가적인 하드웨어 리소스가 필요하다.
2.4 Fine-Grained Multithreading의 예시
- Sun Microsystems의 Niagara 프로세서에서 구현되었으며, 64개의 스레드를 동시에 실행할 수 있는 구조를 가졌다.
3. 기타 Control Dependency Handling 기법
3.1 Multipath Execution
- Branch 발생 시, 가능한 모든 경로의 명령어를 실행하고, 최종적으로 불필요한 경로의 명령어를 버리는 방식이다.
- 높은 하드웨어 비용이 필요하지만, branch prediction의 오버헤드를 줄일 수 있다.
Memory & Storage Hierarchy
1. Memory Hierarchy 개요

- 컴퓨터 내부의 다양한 메모리는 속도와 용량, 비용의 차이에 따라 계층 구조를 형성한다.
- CPU 내부에는 L1, L2, L3 Cache가 존재하며, DRAM과 함께 시스템 메모리를 구성한다.
- 비휘발성(non-volatile) 메모리와 휘발성(volatile) 메모리로 구분되며, 접근 방식에 따라 랜덤 접근과 순차 접근 메모리로 나뉜다.
2. Memory Access 및 주소 체계
- 프로그램의 변수와 함수 코드들은 메모리에 저장되며, 각기 고유한 주소를 갖는다.
- CPU는 특정 메모리 주소를 참조하여 데이터를 읽고 쓰는 방식으로 동작한다.
- 이상적인 메모리 구조에서는 접근 시간이 0에 가깝고, 무한한 용량을 가정하지만, 실제 하드웨어에서는 이러한 이상적인 조건을 충족할 수 없다.

3. Memory Technology: DRAM vs. SRAM

DRAM (Dynamic Random Access Memory)
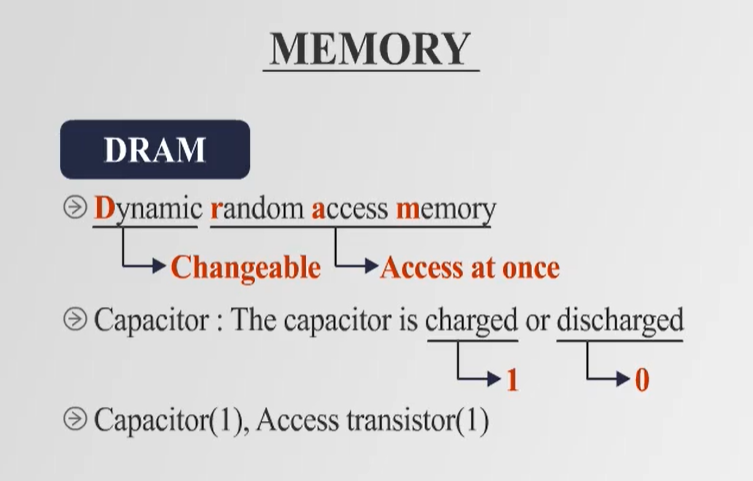
- Capacitor를 사용하여 데이터를 저장하는 방식으로, 일정 시간이 지나면 데이터가 손실될 수 있음.
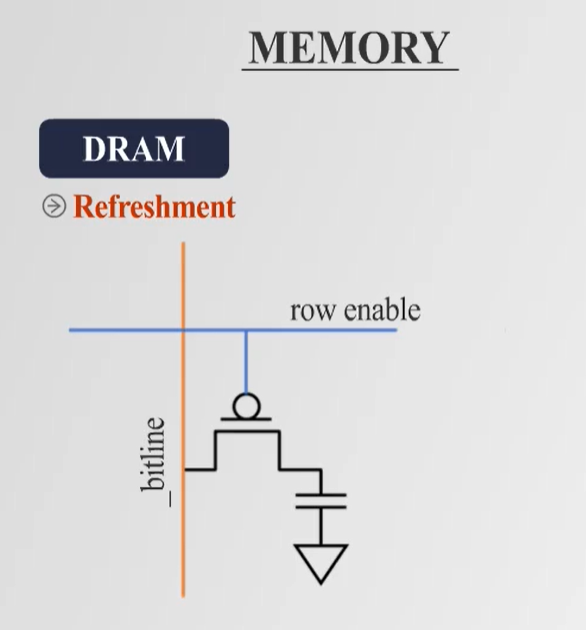
- 지속적인 Refresh가 필요하며, 하드웨어 구성은 간단하고 비용이 저렴하지만 속도가 느림.

SRAM (Static Random Access Memory)
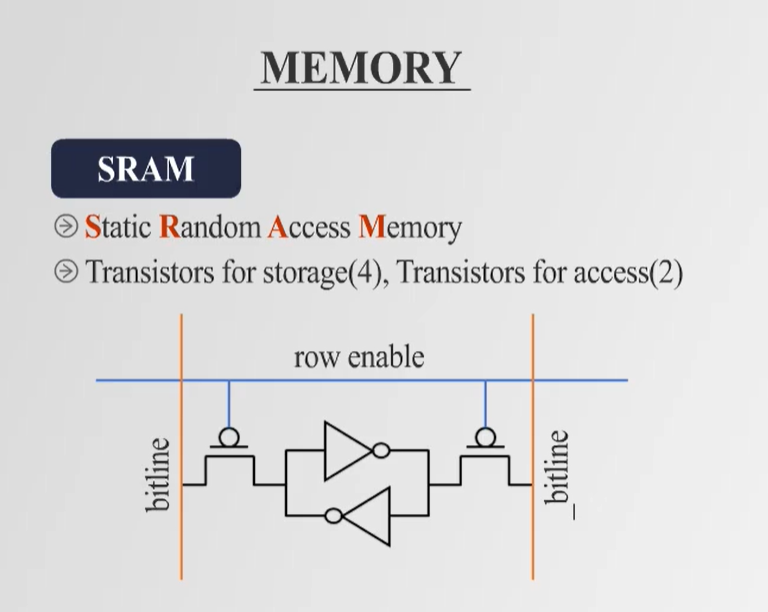
- Flip-Flop 구조의 로직 게이트를 이용하여 데이터를 저장하며, Refresh가 필요 없음.
- 접근 속도가 빠르지만, 더 많은 트랜지스터를 사용하여 제작 비용이 높고, 밀도가 낮음.
4. DRAM 구조 및 동작 방식
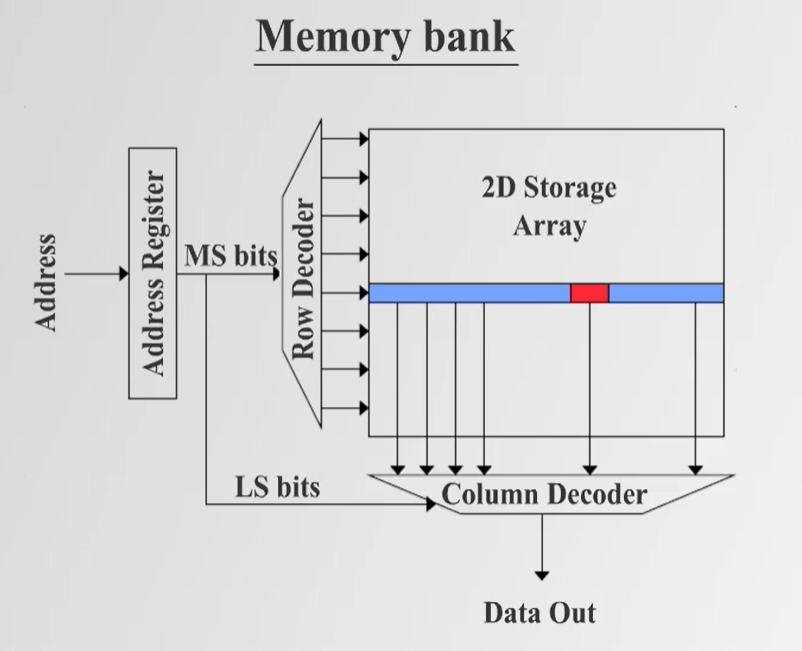
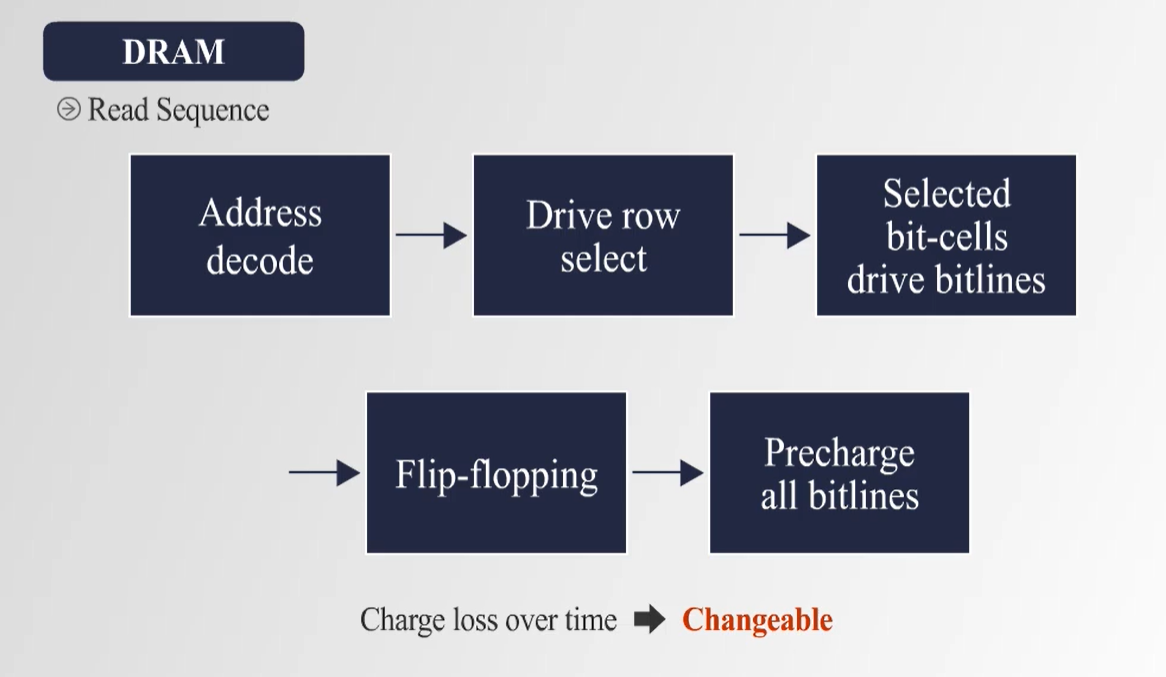
- DRAM은 capacitor와 transistor를 사용하여 bit 단위의 데이터를 저장한다.
- Memory Bank 구조에서 데이터를 행(Row)과 열(Column)로 접근하며, Row Decoder와 Column Decoder를 사용하여 데이터를 선택함.
- 읽기 과정에서 데이터를 증폭 후 전달하며, 일정 시간이 지나면 capacitor의 전하가 감소하여 Refresh 과정이 필요하다.
5. SRAM 구조 및 동작 방식
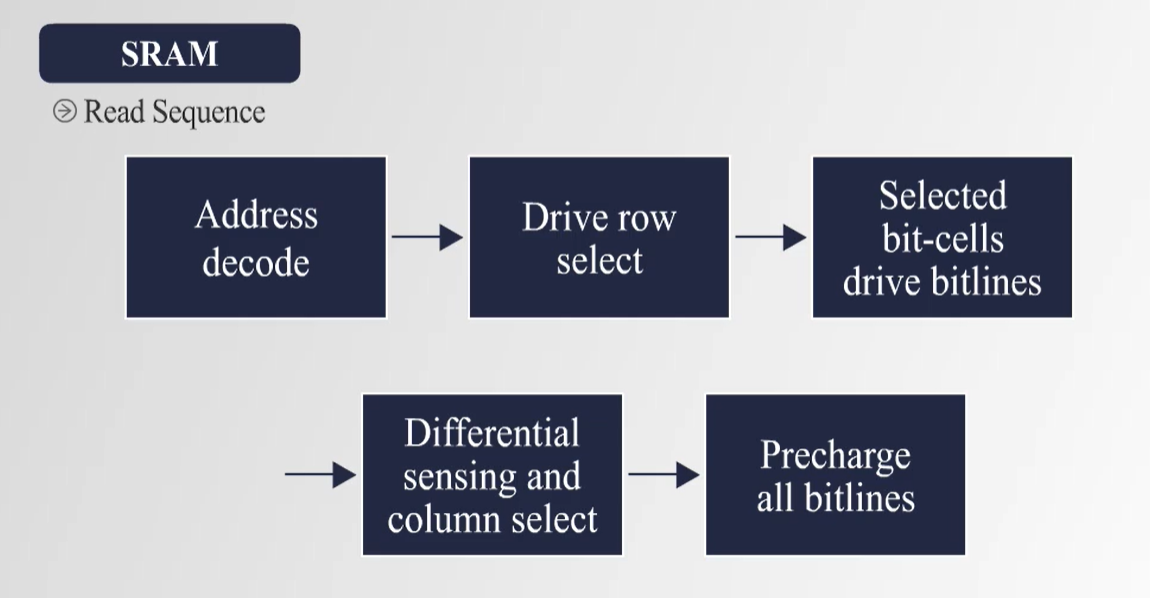
- SRAM은 6개의 트랜지스터를 이용한 Flip-Flop 구조를 통해 데이터를 저장한다.
- DRAM보다 속도가 빠르고 Refresh 과정이 필요 없지만, 제작 비용이 높고 저장 밀도가 낮다.
- CPU 내부의 Cache 메모리(L1, L2, L3 Cache)로 활용된다.
6. Memory Storage 계층 구조
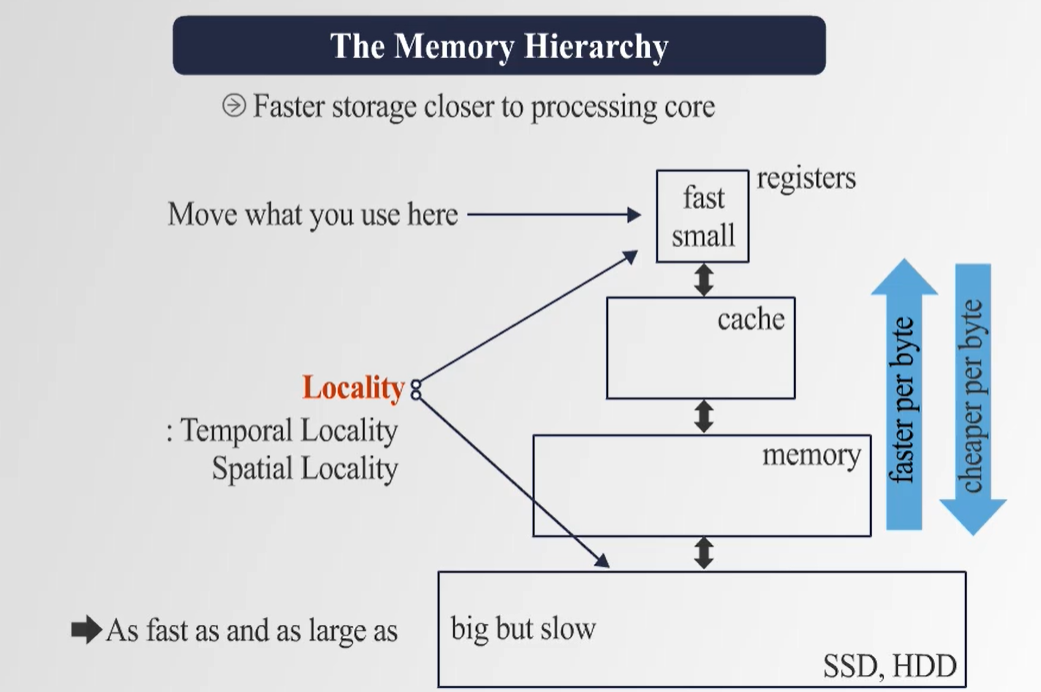
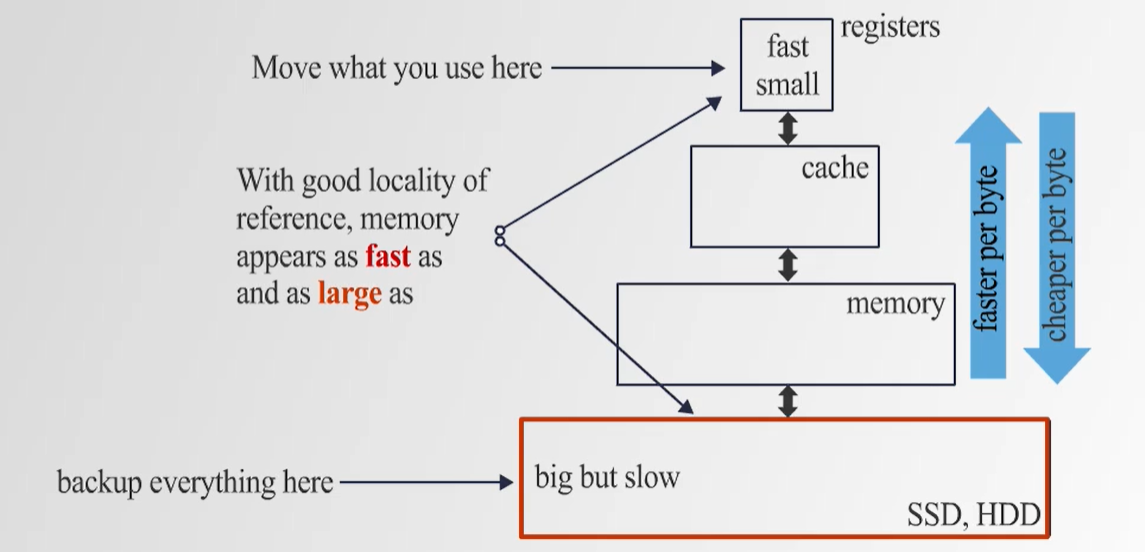
- 속도가 빠른 메모리는 용량이 작고, 속도가 느린 메모리는 용량이 크다.
7. Locality 개념 및 Cache의 역할
- Locality (지역성)
- 메모리 접근 패턴은 완전히 랜덤하지 않으며, 일정한 패턴을 따른다.
- Temporal Locality
- 한 번 접근한 데이터는 곧 다시 접근될 가능성이 높음.
- Spatial Locality
- 특정 주소에 접근한 경우, 그 근처의 주소들도 곧 접근될 가능성이 높 음.
- CPU의 Cache는 이러한 Locality를 활용하여 자주 사용되는 데이터를 저장함으로써, 메모리 접근 속도를 향상시킨다.
8. Storage 장치의 특성과 활용
- HDD (Hard Disk Drive)
- 회전하는 디스크와 자기적 성질을 이용하여 데이터를 저장함.
- 속도가 느리지만, 대용량 저장이 가능하고 가격이 저렴함.
- SSD (Solid State Drive)
- NAND Flash 메모리를 이용하여 데이터를 저장하며, HDD보다 빠른 접근 속도를 가짐.
- 비용이 상대적으로 높지만, 속도가 빠르고 내구성이 높음.
- Cloud Storage
- 인터넷을 통해 원격 서버에 데이터를 저장하는 방식.
- 대규모 데이터 관리와 백업에 유용하지만, 네트워크 속도에 따라 성능이 좌우됨.
Cache Memory
🔷 1. Cache란?
✅ Cache는 프로세서 내부에 존재하는 부분적인 저장소(Partial Storage)
✅ 메모리 접근 속도를 빠르게 하기 위해 사용됨
✅ 크기가 제한적이므로 전체 메모리를 저장할 수 없음
✅ 캐시에 데이터를 찾으면 Cache Hit, 찾지 못하면 Cache Miss 발생
🔷 2. Cache 계층 구조 (Cache Hierarchy)
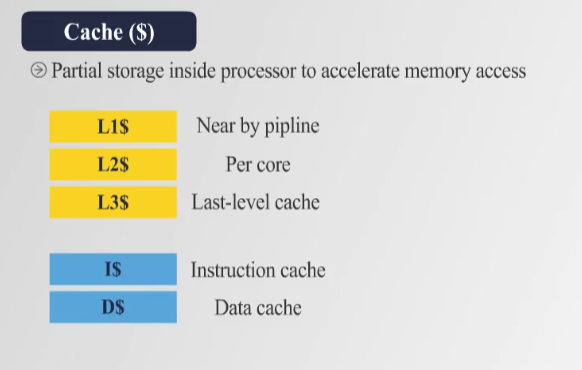
- 📌 캐시는 여러 레벨로 구성됨
- 🔹 L1 Cache ($) → 프로세서 파이프라인 근처에 위치, 가장 빠름 (작음)
- 🔹 L2 Cache ($$) → 각 CPU 코어마다 존재, L1보다 크고 약간 느림
- 🔹 L3 Cache ($$$) → CPU 전체에서 공유되는 마지막 캐시 (Last-Level Cache, LLC)
- 🔹 I$ (Instruction Cache) → 명령어 저장
- 🔹 D$ (Data Cache) → 데이터 저장
🔷 3. Cache의 동작 과정
-
📌 (1) 데이터 조회 (Look-up)
✅ 프로세서가 특정 메모리 주소를 조회
✅ 캐시에서 해당 주소의 데이터가 있는지 확인 -
📌 (2) Tag Store 조회
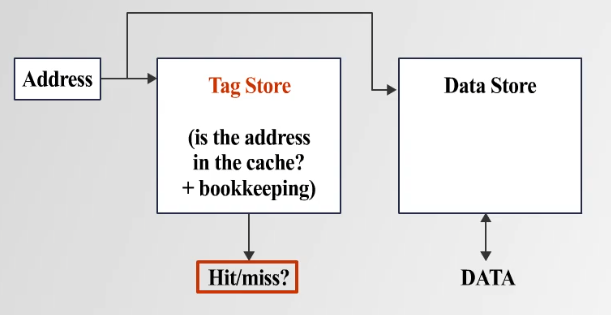
✅ 캐시는 메모리 주소를 그대로 저장하는 것이 아니라, 일부 Tag Bits만 저장
✅ 요청한 주소의 Tag Bits가 캐시에 있는 Tag Bits와 일치하면 Cache Hit
-
📌 (3) Cache Hit vs. Cache Miss
✅ Hit: 데이터를 캐시에서 바로 가져옴 → 빠른 응답
✅ Miss: 데이터가 없으면 메모리에서 데이터를 가져옴- L1 → L2 → L3 → Main Memory 순으로 조회
- Miss가 많아질수록 성능 저하 (Miss Rate 증가)
🔷 4. Cache Miss를 줄이는 방법
-
📌 (1) 효율적인 캐시 구조 설계
✅ Cache Line (Cache Block) 크기 증가
캐시 저장 단위를 늘려 Spatial Locality(공간 지역성) 활용
✅ Tag Store 최적화
메모리 주소를 효율적으로 인덱싱하여 빠른 조회 -
📌 (2) 다단계 캐시 사용
✅ L1 → L2 → L3 다중 계층 캐시(Hierarchy) 추가
✅ 각 계층별로 크기와 속도를 조정하여 Miss Latency 감소 -
📌 (3) 하드웨어 최적화
✅ 메모리 접근 최적화 기술 도입
✅ Prefetching(선제적 데이터 로딩), Branch Prediction(분기 예측) 기법 활용
🔷 5. Cache Mapping 기법
캐시 메모리에 데이터를 저장할 때, 특정한 주소에 어디에 데이터를 저장할지 결정하는 방법이 필요함.
- 📌 (1) Fully Associative Cache
✅ 주소의 일부인 Tag Bits + Cache Line Offset만 사용
✅ 모든 캐시 블록 중에서 어디든 저장 가능
✅ 비교: Tag Bits와 캐시 내 Tag Store를 비교
✅ 장점: 유연한 매핑 가능 → Miss 확률 감소
✅ 단점: 비교 연산(Associative Search)이 많아져 비용 증가
